本文章属于爬虫入门到精通系统教程第七讲
直接开始案例吧。
本次我们实现如何模拟登陆知乎。
1.抓包
首先打开知乎登录页 知乎 - 与世界分享你的知识、经验和见解
注意打开开发者工具后点击“preserve log”,密码记得故意输入错误,然后点击登录
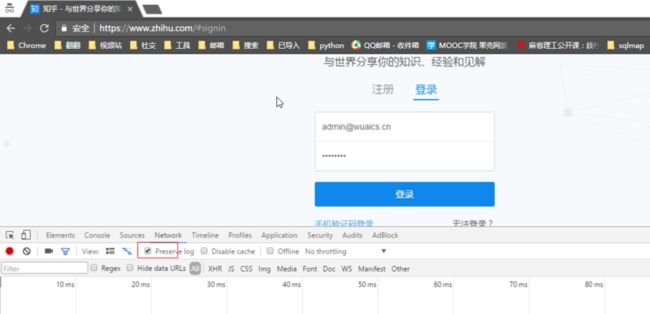
我们很简单的就找到了 我们需要的请求

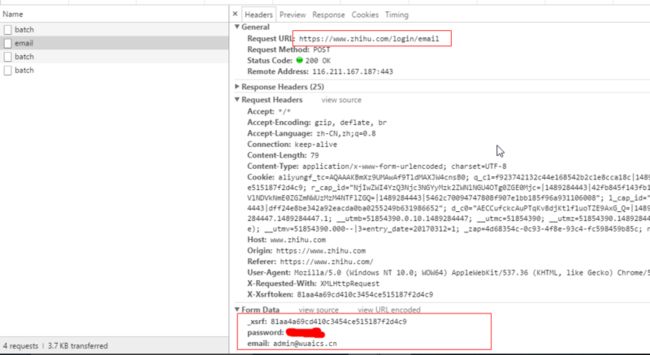
_xsrf:81aa4a69cd410c3454ce515187f2d4c9
password:***
email:[email protected]
可以看到请求一共有三个参数
email 和password就是我们需要登录的账号及密码
那么_xsrf是什么?我们在哪能找到?
像“_xsrf”这种参数,一般叫做页面校检码,是来检查你是否是从正常的登录页面过来的。
那我们复制这个值,在登录页面找找看。
//input[@name="_xsrf"]/@value
所以,本次登录我们需要得到的数据已经都得到了
步骤如下:
打开知乎登录页面,获取_xsrf
把_xsrf和自己的账号及密码一起发送(模拟登录)
2.模拟登录
import requests
url = 'https://www.zhihu.com/#signin'
z = requests.get(url)
print z.status_code
我们会看到 http状态码为500...
至于为什么会返回500状态码呢?是因为我们用程序来访问知乎被发现了...
我们伪装成浏览器,添加一行

可以看到返回正常了,http状态码为200(这就是headers的作用)
那我们现在获取_xsrf
from lxml import etree
sel = etree.HTML(z1.content)
# 这个xsrf怎么获取 我们上面有讲到
_xsrf = sel.xpath('//input[@name="_xsrf"]/@value')[0]
然后模拟登录
loginurl = 'https://www.zhihu.com/login/email'
# 这里的_xsrf就是我们刚刚上面得到的
formdata = {
'email':'[email protected]',
'password':'你的密码',
'_xsrf':_xsrf
}
z2 = requests.post(url=loginurl,data=formdata,headers=headers)
print z2.status_code
#200
print z2.content
# '{"r":0,\n "msg": "\\u767b\\u5f55\\u6210\\u529f"\n}'
print z2.json()['msg']
# 登陆成功
可以看到已经模拟登录并成功了。
那我们来打开知乎 - 与世界分享你的知识、经验和见解来检查下 是否有登录成功
# 为什么用这个页面呢?
# 因为这个页面只有登录后才能看得到,如果没有登录的话 会自动跳转让你登录的
mylog = 'https://www.zhihu.com/people/pa-chong-21/logs'
z3 = requests.get(url=mylog,headers=headers)
print z3.status_code
#200
print z3.url
# u'https://www.zhihu.com/?next=%2Fpeople%2Fpa-chong-21%2Flogs'
发现页面url是 (https://www.zhihu.com/?next=%...
并不是 我前面输入的 (https://www.zhihu.com/people/...
说明知乎判断我们没有登录,然后把我们跳转到登录页面了.
如果感兴趣的话,可以把z3.text 的返回值存为123.html,然后打开看看,是不是跳转到登录页面了..
那么为什么会跳到登录页面呢?刚刚不是已经登录成功了么?
这是因为,我们这几个模拟请求,相互间都是独立的,所以z2登录成功了,和z3并没有什么关系。
那如果我现在想要z3不用再模拟登录一次,也能登录的话,怎么办呢?
我们可以把z2登录成功后得到的cookie给z3,这样,z3也就能登录成功了.
用程序实现

再次判断下是否登录成功。
z3 = requests.get(url=mylog,headers=headers)
print z3.url
# u'https://www.zhihu.com/people/pa-chong-21/logs'
我们可以看到已经正常访问了。说明我们登录成功了
所以,以后只要你带着这个cookie,就可以访问登录后的页面了.(这就是cookie的作用..)
最后附上一个小技巧.
当你需要登录,或者说你需要在一段会话中操作(也就是我们上面的操作)
会话对象高级用法 - Requests 2.10.0 文档
会话对象让你能够跨请求保持某些参数。它也会在同一个 Session 实例发出的所有请求之间保持 cookie, 期间使用 urllib3 的 connection pooling 功能。所以如果你向同一主机发送多个请求,底层的 TCP 连接将会被重用,从而带来显著的性能提升。 (参见 HTTP persistent connection).
使用会话后,我们上面的代码可以改成这样

可以看到我们没有把cookie传过去,但是还是登录成功了,这是因为session会自动帮你处理这些,会自动帮你管理cookie
我们可以打印看下我们请求的headers

可以看到headers里面自动加上了cookie
最后所有的代码都在kimg1234/pachong
最后再次总结一下
看完本篇文章后,你应该要
能理解User-Agent,cookie的作用
了解requests中的session用法
了解如何模拟登录一个网页
如果你对requests这个库不太熟悉的话,你可以在快速上手 - Requests 2.10.0 文档浏览。