Hive案例---日志数据文件分析
案例一

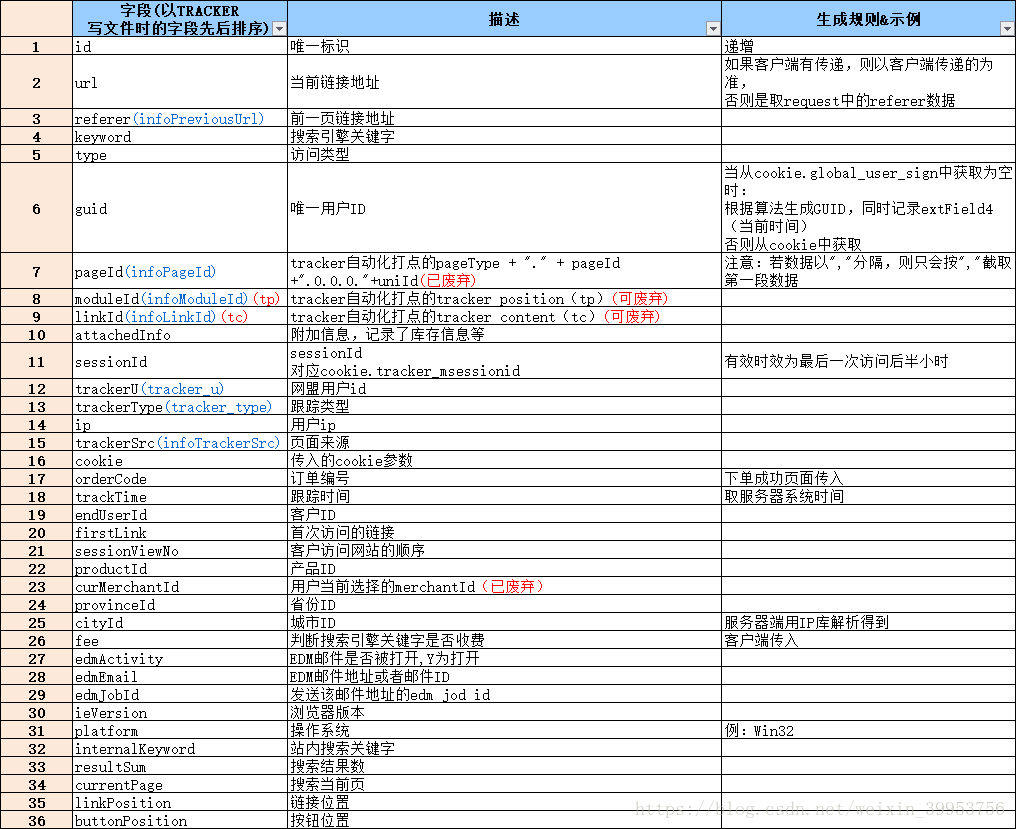
-》需求:统计24小时内的每个时段的pv和uv
-》pv统计总的浏览量
-》uv统计guid去重后的总量
-》获取时间字段,日期和小时 -》分区表
-》2015-08-28 18:14:59 -》28和18 substring方式获取
-》数据分析
-》hive :select sql
-》sqoop:导出mysql
日期 小时 pv uv
-》日期和小时:tracktime
-》pv:url
-》uv:guid
1.【数据收集】
登陆hive:
启动服务端:bin/hiveserver2 &
启动客户端:bin/beeline -u jdbc:hive2://node-1:10000/ -n ibeifeng -p 123456
创建源表:
create database track_log;
create table yhd_source(
id string,
url string,
referer string,
keyword string,
type string,
guid string,
pageId string,
moduleId string,
linkId string,
attachedInfo string,
sessionId string,
trackerU string,
trackerType string,
ip string,
trackerSrc string,
cookie string,
orderCode string,
trackTime string,
endUserId string,
firstLink string,
sessionViewNo string,
productId string,
curMerchantId string,
provinceId string,
cityId string,
fee string,
edmActivity string,
edmEmail string,
edmJobId string,
ieVersion string,
platform string,
internalKeyword string,
resultSum string,
currentPage string,
linkPosition string,
buttonPosition string
)
row format delimited fields terminated by '\t';
load data local inpath '/opt/datas/2015082818' into table yhd_source;
load data local inpath '/opt/datas/2015082819' into table yhd_source;
2. 【数据清洗】
时间是2015082812,需要截取日期28,时间12
创建清洗表
create table yhd_qingxi(
id string,
url string,
guid string,
date string,
hour string
)
row format delimited fields terminated by '\t';
insert into table yhd_qingxi select id,url,guid,substring(trackTime,9,2) date,substring(trackTime,12,2) from yhd_source;
select id,url,guid,date,hour from yhd_source;
创建分区表:根据时间字段进行分区,分区的好处是检索速度加快
create table yhd_part(
id string,
url string,
guid string
)partitioned by (date string,hour string)
row format delimited fields terminated by '\t';
insert into table yhd_part partition(date='20150828',hour='18');
select id,url,guid from yhd_qingxi where date='28' and hour='19';
select id,url,guid from yhd_part where date='20150828' and hour='19';
set hive.exec.dynamic.partition.mode=nonstrict;
id string,
url string,
guid string
)partitioned by (date string,hour string)
row format delimited fields terminated by '\t';
insert into table yhd_part partition(date='20150828',hour='18')
select id,url,guid from yhd_qingxi where date='28' and hour='18';
insert into table yhd_part2 partition (date,hour) select * from yhd_qingxi;
3. 数据分析
PV:
select date,hour,count(url) pv from yhd_part group by date,hour;
结果:
+-----------+-------+--------+--+
| date | hour | pv |
+-----------+-------+--------+--+
| 20150828 | 18 | 64972 |
| 20150828 | 19 | 61162 |
+-----------+-------+--------+--+
UV:
select date, hour, count(distinct(guid)) uv from yhd_part group by date,hour;
结果:
+-----------+-------+--------+--+
| date | hour | uv |
+-----------+-------+--------+--+
| 20150828 | 18 | 23938 |
| 20150828 | 19 | 22330 |
+-----------+-------+--------+--+
最中的结果导入到结果表中:
create table result as select date,hour,count(url) uv, count(distinct(guid)) pv from yhd_part;
4.数据导出:
将最终结果导入到MySQL中:
在MySQL里创建表:
create table save(
date varchar(30),
hour varchar(30),
pv varchar(30),
uv varchar(30),
primary key(date,hour)
);
sqoop方式:
hive=> mysql
bin/sqoop export \
--connect jdbc:mysql://node-1:3306/sqoop/ \
--username root \
--password 123456 \
--table save \
--export-dir /user/hive/warehouse/track_log.db/result/ \
--m1 \
--input-fields-terminate-by "\001"
因为创建result表是通过create as select语句案例二
会话信息表
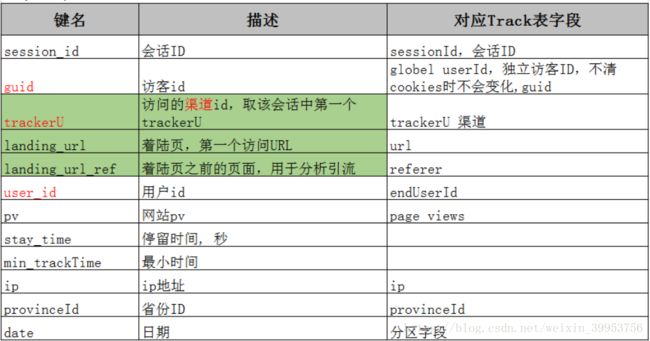
数据字典表
流程:
-》需求分析(业务性)
-》数据采集(采集的框架和平台处理框架)
-》数据清洗(处理的手段)
-》数据分析(分析的逻辑)
-》结果展示(数据可视化)
1、需求分析
日期:可以根据最后统计分析的时候根据日期进行分组,可以建立分区表
pv:count(url)
uv:count(distinct(guid))
登陆访客:user_id有值,会员,有账号登陆
游客:user_id 无值,非登陆人员
平均访问时长:每个用户登陆都会产生一个session,统计session平均的停留时间
-》进入页面第一条时间戳,最后离开页面的最后一条时间戳
二跳率:一个用户在一个session会话中,点击的页面大于等于的会话就是二跳率
-》求访问页面超过2个的用户,联想到PV
-》统计PV大于等于2的用户再除以总的人数
独立ip:统计ip去重(公网ip)
create database yhd_log;
create table yhd_source(
id string,
url string,
referer string,
keyword string,
type string,
guid string,
pageId string,
moduleId string,
linkId string,
attachedInfo string,
sessionId string,
trackerU string,
trackerType string,
ip string,
trackerSrc string,
cookie string,
orderCode string,
trackTime string,
endUserId string,
firstLink string,
sessionViewNo string,
productId string,
curMerchantId string,
provinceId string,
cityId string,
fee string,
edmActivity string,
edmEmail string,
edmJobId string,
ieVersion string,
platform string,
internalKeyword string,
resultSum string,
currentPage string,
linkPosition string,
buttonPosition string
)
partitioned by(date string)
row format delimited fields terminated by '\t';
trackerU访问渠道:通过什么方式进入到网站
-》收藏夹
-》手输网站
-》论坛、博客
。。。
-》需要获取第一个记录
作用:可以通过访问的渠道,加大投放力度,去宣传
-》着陆页面
-》用户进入网站的第一个页面
-》分析同一个session会话中的第一个页面
-》需要获取第一个记录
-》着陆页面之前的地址
-》需要获取第一个记录
min_trackTime最小时间:进入第一个页面的时间戳,后面的时间是增加的
session_id string ,
guid string ,
trackerU string ,
landing_url string ,
landing_url_ref string ,
user_id string ,
pv string ,
stay_time string ,
min_trackTime string ,
ip string ,
provinceId string
)
partitioned by (date string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' ;
-》加载数据:数据来源于源表
-》针对每个会话来说要进行一个 group by sessionId
-》按照sessionId进行分组之后可能会得到多条记录
-》由于session进行分组,那么就是对于每个session里面统计PV
对sessionID进行group by之后,session_id,guid,user_id,pv,stay_time,min_trackTime,ip,provinceId都可以通过聚合函数得到!!但是trackerU,landing_url, landing_url_ref 有多个,我们无法通过聚合函数得到最早时间的值,所以我们可以考虑通过两个临时表做join,通过第一张表的sessionID,min_trackTime 与第二张表的sessionID,trackTime相等作为判据,就会得到我们想要的trackerU,landing_url, landing_url_ref ;
select
sessionId session_id,
max(guid) guid,
max(endUserId) user_id,
count(distinct url) pv,
(unix_timestamp(max(trackTime))-unix_timestamp(min(trackTime))) stay_time,
min(trackTime) min_trackTime,
max(ip) ip,
max(provinceId) provinceId
from yhd_source where date='2015082818'
group by sessionId;
-》从源表中获取每一条记录的时间
-》然后进行最小时间与源表中最小时间的join,获取trackerU、landing_url、landing_url_ref
-》这张表不需要group by
-》从源表中的每一条记录中获取字段
select
sessionId session_id,
trackTime trackTime,
url landing_url,
referer landing_url_ref,
trackerU trackerU
from yhd_source
where date='2015082818';
-》join
insert overwrite table session_info partition(date='2015082818')
select
a.session_id session_id,
max(a.guid) guid,
max(b.trackerU) trackerU,
max(b.landing_url) landing_url,
max(b.landing_url_ref) landing_url_ref,
max(a.user_id) user_id,
max(a.pv) pv,
max(a.stay_time) stay_time,
max(a.min_trackTime) min_trackTime,
max(a.ip) ip,
max(a.provinceId) provinceId
from session_tmp a join track_tmp b on
a.session_id=b.session_id and a.min_trackTime=b.trackTime
group by a.session_id;
create table result as
select
date date,
sum(pv) PV,
count(distinct guid) UV,
count(distinct case when user_id is not null then guid else null end) login_user,
count(distinct case when user_id is null then guid else null end) visitor,
avg(stay_time) avg_time,
(count(case when pv>=2 then session_id else null end)/count(session_id)) session_jump,
count(distinct ip) IP
from session_info
where date='2015082818'
group by date;
日期 PV UV 登陆人员 游客 平均访问时长 二跳率 ip数
2015082818 36420.0 23928 23928 0 49.74171774059963 0.25886201755838995 19174
create table result2 as
select
date date,
sum(pv) PV,
count(distinct guid) UV,
count(distinct case when length(user_id)!=0 then guid else null end) login_user,
count(distinct case when length(user_id)=0 then guid else null end) visitor,
avg(stay_time) avg_time,
(count(case when pv>=2 then session_id else null end)/count(session_id)) session_jump,
count(distinct ip) IP
from session_info
where date='2015082818'
group by date;
日期 PV UV 登陆人员 游客 平均访问时长 二跳率 ip数
2015082818 36420.0 23928 11586 12367 49.74171774059963 0.25886201755838995 19174