Datawhale--TASK1
1.1 学习目标
理解赛题数据和目标,清楚评分体系。
完成相应报名,下载数据和结果提交打卡(可提交示例结果),熟悉比赛流程
1.2 了解赛题
赛题概况、数据概况、预测指标、分析赛题
1.2.1 赛题概况
比赛要求参赛选手根据给定的数据集,建立模型,二手汽车的交易价格。来自 Ebay Kleinanzeigen 报废的二手车,数量超过 370,000,包含 20 列变量信息,为了保证 比赛的公平性,将会从中抽取 10 万条作为训练集,5 万条作为测试集 A,5 万条作为测试集 B。同时会对名称、车辆类型、变速箱、model、燃油类型、品牌、公里数、价格等信息进行 脱敏。
1.2.2 数据概况
一般而言,对于数据在比赛界面都有对应的数据概况介绍(匿名特征除外),说明列的性质特征。了解列的性质会有助于我们对于数据的理解和后续分析。 Tip:匿名特征,就是未告知数据列所属的性质的特征列。
train.csv
name - 汽车编码 regDate - 汽车注册时间 model - 车型编码车型编码 brand - 品牌 bodyType - 车身类型
fuelType - 燃油类型 gearbox - 变速箱 power - 汽车功率 kilometer - 汽车行驶公里 notRepairedDamage - 汽车有尚未修复的损坏 regionCode - 看车地区编码 seller - 销售方 offerType - 报价类型 creatDate - 广告发布时间 price - 汽车价格 v_0’, ‘v_1’, ‘v_2’, ‘v_3’, ‘v_4’, ‘v_5’, ‘v_6’, ‘v_7’, ‘v_8’, ‘v_9’, ‘v_10’, ‘v_11’, ‘v_12’, ‘v_13’,‘v_14’(根据汽车的评
论、标签等大量信息得到的embedding向量)【人工构造 匿名特征】 数字全都脱敏处理,都为label encoding形式,即数字形式
1.2.3 预测指标
本赛题的评价标准为MAE(Mean Absolute Error):
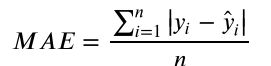
一般问题评价指标说明:
什么是评估指标:
评估指标即是我们对于一个模型效果的数值型量化。(有点类似与对于一个商品评价打分,而这
是针对于模型效果和理想效果之间的一个打分)
一般来说分类和回归问题的评价指标有如下一些形式:
分类算法常见的评估指标如下:
对于二类分类器/分类算法,评价指标主要有accuracy, [Precision,Recall,F-score,Pr曲线],ROC-AUC曲线。
对于多类分类器/分类算法,评价指标主要有accuracy, [宏平均和微平均,F-score]。
对于回归预测类常见的评估指标如下:

1.2.4. 分析赛题
- 此题为传统的数据挖掘问题,通过数据科学以及机器学习深度学习的办法来进行建模得到结果。
- 此题是一个典型的回归问题。
- 主要应用xgb、lgb、catboost,以及pandas、numpy、matplotlib、seabon、sklearn、keras等等数据挖掘常用库或者框架来进行数据挖掘任务。
- 通过EDA来挖掘数据的联系和熟悉数据。
1.3 代码示例
本部分为对于数据读取和指标评价的示例。
1.3.1 数据读取pandas
In [2]:import pandas as pd
import numpy as np
path = './data/'
## 1) 载入训练集和测试集;
Train_data = pd.read_csv(path + 'train.csv', sep = ' ')
Test_data = pd.read_csv(path + 'testA.csv', sep = ' ')
print('Train data shape:',Train_data.shape)
print('TestA data shape:',Test_data.shape)
Train data shape: (150000, 31)
TestA data shape: (50000, 30)In [3]:
Train_data.head()
Out[3]:
SaleID name regDate model brand bodyType fuelType gearbox power kilometer ...
0 0 736 20040402 30.0 6 1.0 0.0 0.0 60 12.5 ...
1 1 2262 20030301 40.0 1 2.0 0.0 0.0 0 15.0 ...
2 2 14874 20040403 115.0 15 1.0 0.0 0.0 163 12.5 ...
3 3 71865 19960908 109.0 10 0.0 0.0 1.0 193 15.0 ...
4 4 111080 20120103 110.0 5 1.0 0.0 0.0 68 5.0 ...
5 rows × 31 columns
1.3.2 分类指标评价计算示例
In [4]:
## accuracy
import numpy as np
from sklearn.metrics import accuracy_score
y_pred = [0, 1, 0, 1]
y_true = [0, 1, 1, 1]
print('ACC:',accuracy_score(y_true, y_pred))
ACC: 0.75
In [5]:
## Precision,Recall,F1-score
from sklearn import metrics
y_pred = [0, 1, 0, 0]
y_true = [0, 1, 0, 1]
print('Precision',metrics.precision_score(y_true, y_pred))
print('Recall',metrics.recall_score(y_true, y_pred))
print('F1-score:',metrics.f1_score(y_true, y_pred))
Precision 1.0
Recall 0.5
F1-score: 0.6666666666666666
In [6]:
## AUC
import numpy as np
from sklearn.metrics import roc_auc_score
y_true = np.array([0, 0, 1, 1])
y_scores = np.array([0.1, 0.4, 0.35, 0.8])
print('AUC socre:',roc_auc_score(y_true, y_scores))
AUC socre: 0.751.3.3 回归指标评价计算示例
In [8]:
# coding=utf-8
import numpy as np
from sklearn import metrics
# MAPE需要自己实现
def mape(y_true, y_pred):
return np.mean(np.abs((y_pred - y_true) / y_true))
y_true = np.array([1.0, 5.0, 4.0, 3.0, 2.0, 5.0, - 3.0])
y_pred = np.array([1.0, 4.5, 3.8, 3.2, 3.0, 4.8, - 2.2])
# MSE
print('MSE:',metrics.mean_squared_error(y_true, y_pred))
# RMSE
print('RMSE:',np.sqrt(metrics.mean_squared_error(y_true, y_pred)))
# MAE
print('MAE:',metrics.mean_absolute_error(y_true, y_pred))
# MAPE
print('MAPE:',mape(y_true, y_pred))
MSE: 0.2871428571428571
RMSE: 0.5358571238146014
MAE: 0.4142857142857143
MAPE: 0.1461904761904762
In [10]:
## R2-score
from sklearn.metrics import r2_score
y_true = [3, - 0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
print('R2-score:',r2_score(y_true, y_pred))
R2-score: 0.9486081370449679
1.4 相关经验总结
(1)理解赛题背后的任务逻辑,知道相关数据以及用到哪些指标(这些指标能否做到线上线下一致),以及对于特征是否了解并且可以通过EDA来寻求他们直接的关系,最后构造出满意的特征。
(2)从哪里挖掘特征,哪种线下验证更稳定。出现了问题,例如过拟合问题如何解决。数据问题:哪些数据是可靠的,需要精密处理,哪些是关键的
(3)评价指标,线上提交次数很有限。同时不同指标的侧重点不同
(4)多方考虑,有些隐藏问题。比如高效性要求,比如对于数据异常的识别处理,比如工序流程的差异性,比如模型运行的
时间,比如模型的鲁棒性等
1.5 baseline的实现
# -*- coding: utf-8 -*-
##step1:导入函数工具箱
import os
print(os.path.abspath(os.path.dirname(__file__)))
import numpy as np
import pandas as pd
import warnings
import matplotlib
import matplotlib.pylab as plt
import seaborn as sns
from scipy.special import jn
from IPython.display import display,clear_output
import time
warnings.filterwarnings('ignore')
#%matplotlib inline
#模型预测的
from sklearn import linear_model
from sklearn import preprocessing
from sklearn.svm import SVR
from sklearn.ensemble import RandomForestRegressor,GradientBoostingRegressor
#数据降维处理
from sklearn.decomposition import PCA,FastICA,FactorAnalysis,SparsePCA
import lightgbm as lgb
import xgboost as xgb
#参数搜索和评价
from sklearn.model_selection import GridSearchCV,cross_val_score,StratifiedKFold,train_test_split
from sklearn.metrics import mean_squared_error,mean_absolute_error
#Step 2 数据读取
#通过pandas对于数据进行读取(pandas是个很友好的数据读取函数库)
Train_data = pd.read_csv('/home/ysn7/PycharmProjects/Datawhale/used_car_train_20200313.csv',sep=' ')
TestA_data=pd.read_csv('/home/ysn7/PycharmProjects/Datawhale/used_car_testA_20200313.csv',sep=' ')
#输出数据的大小信息
print("Train data shape:",Train_data.shape)
print("TestA data shape",TestA_data.shape)
#1)数据简要浏览
print(Train_data.head())
# 通过 .info() 简要可以看到对应一些数据列名,以及NAN缺失信息
#2)数据信息查看
print(Train_data.info())
#通过 .columns 查看列名
print(Train_data.columns)
print(TestA_data.info())
#3)数据统计信息浏览
#通过 .describe() 可以查看数值特征列的一些统计信息
print(Train_data.describe())
print(TestA_data.describe())
#step 3特征与标签构建
#1)提取数值类型特征列名
numerical_cols=Train_data.select_dtypes(exclude='object').columns #不包括
print(numerical_cols)
categorical_cols=Train_data.select_dtypes(include='object').columns#包括
print(categorical_cols)
#2)构建训练和测试样本
#选择特征列
feature_cols=[col for col in numerical_cols if col not in['SaleID','name','regDate','creatDate','price','model','brand','regionCode','seller']]
print("---")
print(feature_cols)
feature_cols=[col for col in feature_cols if 'Type' not in col]
print("---")
print(feature_cols)
#提取特征列,标签列构造训练样本和测试样本
X_data = Train_data[feature_cols]
Y_data = Train_data['price']#标签
X_test = TestA_data[feature_cols]
print('X train shape:',X_data.shape)
print('X test shape:',X_test.shape)
#定义一个统计函数,方便后续信息统计
def Sta_inf(data):
print('_min', np.min(data))
print('_max:', np.max(data))
print('_mean', np.mean(data))
print('_ptp', np.ptp(data))#计算最大与最小值的差的函数
print('_std', np.std(data))#计算标准差
""" 计算标准差时,需要注意numpy中的std和pandas的std在计算标准差时,默认的计算结果会存在不一致的问题。
原因在于默认情况下,
numpy计算的为总体标准偏差,ddof=0;一般在拥有所有数据的情况下,计算所有数据的标准差时使用,即最终除以n,而非n-1;
pandas计算的为样本标准偏差,ddof=1;一般在只有部分数据,但需要求得总体的标准差时使用,当只有部分数据时,根据统计规律,除以n时计算的标准差往往偏小,因此需要除以n-1,即n-ddof;
实际使用时需要注意,并且根据数据情况选择合适的函数,在数据量较大时,推荐使用numpy进行计算。
"""
print('_var', np.var(data))#方差
#3)统计标签的基本分布信息
print('sta of label:')
print(Sta_inf(Y_data))
#绘制标签的统计图,查看标签分布
plt.hist(Y_data)#绘制直方图
plt.show()
plt.close()
#4)缺省值用-1填补
X_data=X_data.fillna(-1)
X_test=X_test.fillna(-1)
#step 4 模型训练与预测
#1) 利用xgb进行五折交叉验证查看模型的参数效果
##--xgb-model
"""
Xgboost是Boosting算法的其中一种,
Boosting算法的思想是将许多弱分类器集成在一起,
形成一个强分类器。
因为Xgboost是一种提升树模型,
所以它是将许多树模型集成在一起,形成一个很强的分类器。
而所用到的树模型则是CART回归树模型。
"""
xgr=xgb.XGBRegressor(n_estimators=120,learning_rate=0.1,gamma=0,subsample=0.8,colsample_bytree=0.9,
max_depth=7
)
scores_train=[]
scores=[]
#五折交叉验证方式
"""
KFold交叉采样:将训练/测试数据集划分n_splits个互斥子集,每次只用其中一个子集当做测试集,剩下的(n_splits-1)作为训练集,进行n_splits次实验并得到n_splits个结果。
注:对于不能均等分的数据集,前n_samples%n_spllits子集拥有n_samples//n_spllits+1个样本,其余子集都只有n_samples//n_spllits个样本。
(例10行数据分3份,只有一份可分4行,其他均为3行)
n_splits:表示将数据划分几等份
shuffle:在每次划分时,是否进行洗牌
若为False,其效果相当于random_state为整数(含零),每次划分的结果相同
若为True,每次划分的结果不一样,表示经过洗牌,随机取样的
random_state:随机种子数,当设定值(一般为0)后可方便调参,因为每次生成的数据集相同
StratifiedKFold分层采样,用于交叉验证:与KFold最大的差异在于,StratifiedKFold方法是根据标签中不同类别占比来进行拆分数据的。
"""
sk=StratifiedKFold(n_splits=5,shuffle=True,random_state=0)
for train_ind,val_ind in sk.split(X_data,Y_data):
"""
iloc比较简单,它是基于索引位来选取数据集,0:4就是选取 0,1,2,3这四行,
需要注意的是这里是前闭后开集合
使用标签选取数据:
df.loc[行标签,列标签]
df.loc['a':'b']#选取ab两行数据
df.loc[:,'one']#选取one列的数据
"""
train_x = X_data.iloc[train_ind].values
train_y = Y_data.iloc[train_ind]
# # print(train_x)
# # print("---")
# # print(train_y)
val_x = X_data.iloc[val_ind].values
val_y = Y_data.iloc[val_ind]
xgr.fit(train_x, train_y)
#fit()解释:简单来说,就是求得训练集X的均值啊,方差啊,最大值啊,
# 最小值啊这些训练集X固有的属性。可以理解为一个训练过程
pred_train_xgb = xgr.predict(train_x)
pred_xgb = xgr.predict(val_x)
score_train = mean_absolute_error(train_y, pred_train_xgb)
scores_train.append(score_train)
score = mean_absolute_error(val_y, pred_xgb)
scores.append(score)
print("train mae:",np.mean(score_train))
print("val mae:",np.mean(scores))
#2)定义xgb和lgb模型函数
def build_model_xgb(x_train,y_train):
model=xgb.XGBRegressor(n_estimators=150,learning_rate=0.1,gamma=0,subsample=0.8,
colsample_bytree=0.9,max_depth=7)
model.fit(x_train,y_train)
return model
def build_model_lgb(x_train,y_train):
estimator=lgb.LGBMRegressor(num_leaves=127,n_estimators=150)
param_grid={
'learning_rate':[0.01,0.05,0.1,0.2]
}
gbm=GridSearchCV(estimator,param_grid)
gbm.fit(x_train,y_train)
return gbm
"""
xgboost和lightgbm
决策树算法
XGBoost使用的是pre-sorted算法,能够更精确的找到数据分隔点;
首先,对所有特征按数值进行预排序。
其次,在每次的样本分割时,用O(# data)的代价找到每个特征的最优分割点。
最后,找到最后的特征以及分割点,将数据分裂成左右两个子节点。
优缺点:
这种pre-sorting算法能够准确找到分裂点,但是在空间和时间上有很大的开销。
i. 由于需要对特征进行预排序并且需要保存排序后的索引值(为了后续快速的计算分裂点),
因此内存需要训练数据的两倍。
ii. 在遍历每一个分割点的时候,都需要进行分裂增益的计算,消耗的代价大。
LightGBM使用的是histogram算法,占用的内存更低,数据分隔的复杂度更低。
其思想是将连续的浮点特征离散成k个离散值,并构造宽度为k的Histogram。然后遍历训练数据,
统计每个离散值在直方图中的累计统计量。在进行特征选择时,只需要根据直方图的离散值,遍历寻找最优的分割点。
Histogram 算法的优缺点:
Histogram算法并不是完美的。由于特征被离散化后,找到的并不是很精确的分割点,
所以会对结果产生影响。但在实际的数据集上表明,离散化的分裂点对最终的精度影响并不大,
甚至会好一些。原因在于decision tree本身就是一个弱学习器,采用Histogram算法会起到正则化的效果,
有效地防止模型的过拟合。
时间上的开销由原来的O(#data * #features)降到O(k * #features)。
由于离散化,#bin远小于#data,因此时间上有很大的提升。
Histogram算法还可以进一步加速。一个叶子节点的Histogram可以直接由父节点的Histogram和
兄弟节点的Histogram做差得到。一般情况下,构造Histogram需要遍历该叶子上的所有数据,
通过该方法,只需要遍历Histogram的k个捅。速度提升了一倍。
"""
#3)切分数据集(train,val)进行魔性训练,评价和预测
#Split data with val
x_train,x_val,y_train,y_val=train_test_split(X_data,Y_data,test_size=0.3)
print("----------")
print('train lgb...')
model_lgb=build_model_xgb(x_train,y_train)
val_lgb=model_lgb.predict(x_val)
MAE_lgb=mean_absolute_error(y_val,val_lgb)
print('MAE of val with lgb:',MAE_lgb)
print('predict lgb...')
model_lgb_pre=build_model_lgb(X_data,Y_data)
subA_lgb=model_lgb_pre.predict(X_test)
print("Sta of predict lgb:")
Sta_inf(subA_lgb)
print('train xgb...')
model_xgb = build_model_xgb(x_train,y_train)
val_xgb = model_xgb.predict(x_val)
MAE_xgb = mean_absolute_error(y_val,val_xgb)
print('MAE of val with xgb:',MAE_xgb)
print('predict xgb...')
model_xgb_pre = build_model_xgb(X_data,Y_data)
subA_xgb = model_xgb_pre.predict(X_test)
print('Sta of predict xgb:')
Sta_inf(subA_xgb)
#4)进行两模型的结果加权融合
#采取简单的加权融合方式
val_Weighted=(1-MAE_lgb/(MAE_xgb+MAE_lgb))*val_lgb+(1-MAE_xgb/(MAE_xgb+MAE_lgb))*val_xgb
# 由于我们发现预测的最小值有负数,而真实情况下,price为负是不存在的,
# 由此我们进行对应修正
val_Weighted[val_Weighted<0]=10
print("MAE of val with Weighted ensemble:",mean_absolute_error(y_val,val_Weighted))
sub_Weighted=(1-MAE_lgb/(MAE_xgb+MAE_lgb))*subA_lgb+(1-MAE_xgb/(MAE_xgb+MAE_lgb))*subA_xgb
#查看预测值的统计直方图
plt.hist(Y_data)
plt.show()
plt.close()
#5)输出结果
"""
DataFrame是一种表格型数据结构,
它含有一组有序的列,每列可以是不同的值。
DataFrame既有行索引,也有列索引,
它可以看作是由Series组成的字典,
不过这些Series公用一个索引。
DataFrame的创建有多种方式,
不过最重要的还是根据dict进行创建,
以及读取csv或者txt文件来创建。
"""
sub=pd.DataFrame()#pandas的DataFrame就像numpy中的矩阵,不过它拥有列名和索引名,
sub['SaleID']=TestA_data.SaleID
sub['price'] = sub_Weighted
sub.to_csv('./sub_Weighted.csv',index=False)
print(sub.head())
1.6 baseline的运行结果
/home/ysn7/PycharmProjects/Datawhale
Train data shape: (150000, 31)
TestA data shape (50000, 30)
SaleID name regDate ... v_12 v_13 v_14
0 0 736 20040402 ... -2.420821 0.795292 0.914762
1 1 2262 20030301 ... -1.030483 -1.722674 0.245522
2 2 14874 20040403 ... 1.565330 -0.832687 -0.229963
3 3 71865 19960908 ... -0.501868 -2.438353 -0.478699
4 4 111080 20120103 ... 0.931110 2.834518 1.923482
[5 rows x 31 columns]
RangeIndex: 150000 entries, 0 to 149999
Data columns (total 31 columns):
SaleID 150000 non-null int64
name 150000 non-null int64
regDate 150000 non-null int64
model 149999 non-null float64
brand 150000 non-null int64
bodyType 145494 non-null float64
fuelType 141320 non-null float64
gearbox 144019 non-null float64
power 150000 non-null int64
kilometer 150000 non-null float64
notRepairedDamage 150000 non-null object
regionCode 150000 non-null int64
seller 150000 non-null int64
offerType 150000 non-null int64
creatDate 150000 non-null int64
price 150000 non-null int64
v_0 150000 non-null float64
v_1 150000 non-null float64
v_2 150000 non-null float64
v_3 150000 non-null float64
v_4 150000 non-null float64
v_5 150000 non-null float64
v_6 150000 non-null float64
v_7 150000 non-null float64
v_8 150000 non-null float64
v_9 150000 non-null float64
v_10 150000 non-null float64
v_11 150000 non-null float64
v_12 150000 non-null float64
v_13 150000 non-null float64
v_14 150000 non-null float64
dtypes: float64(20), int64(10), object(1)
memory usage: 35.5+ MB
None
Index(['SaleID', 'name', 'regDate', 'model', 'brand', 'bodyType', 'fuelType',
'gearbox', 'power', 'kilometer', 'notRepairedDamage', 'regionCode',
'seller', 'offerType', 'creatDate', 'price', 'v_0', 'v_1', 'v_2', 'v_3',
'v_4', 'v_5', 'v_6', 'v_7', 'v_8', 'v_9', 'v_10', 'v_11', 'v_12',
'v_13', 'v_14'],
dtype='object')
RangeIndex: 50000 entries, 0 to 49999
Data columns (total 30 columns):
SaleID 50000 non-null int64
name 50000 non-null int64
regDate 50000 non-null int64
model 50000 non-null float64
brand 50000 non-null int64
bodyType 48587 non-null float64
fuelType 47107 non-null float64
gearbox 48090 non-null float64
power 50000 non-null int64
kilometer 50000 non-null float64
notRepairedDamage 50000 non-null object
regionCode 50000 non-null int64
seller 50000 non-null int64
offerType 50000 non-null int64
creatDate 50000 non-null int64
v_0 50000 non-null float64
v_1 50000 non-null float64
v_2 50000 non-null float64
v_3 50000 non-null float64
v_4 50000 non-null float64
v_5 50000 non-null float64
v_6 50000 non-null float64
v_7 50000 non-null float64
v_8 50000 non-null float64
v_9 50000 non-null float64
v_10 50000 non-null float64
v_11 50000 non-null float64
v_12 50000 non-null float64
v_13 50000 non-null float64
v_14 50000 non-null float64
dtypes: float64(20), int64(9), object(1)
memory usage: 11.4+ MB
None
SaleID name ... v_13 v_14
count 150000.000000 150000.000000 ... 150000.000000 150000.000000
mean 74999.500000 68349.172873 ... 0.000313 -0.000688
std 43301.414527 61103.875095 ... 1.288988 1.038685
min 0.000000 0.000000 ... -4.153899 -6.546556
25% 37499.750000 11156.000000 ... -1.057789 -0.437034
50% 74999.500000 51638.000000 ... -0.036245 0.141246
75% 112499.250000 118841.250000 ... 0.942813 0.680378
max 149999.000000 196812.000000 ... 11.147669 8.658418
[8 rows x 30 columns]
SaleID name ... v_13 v_14
count 50000.000000 50000.000000 ... 50000.000000 50000.000000
mean 174999.500000 68542.223280 ... -0.003147 0.001516
std 14433.901067 61052.808133 ... 1.286597 1.027360
min 150000.000000 0.000000 ... -4.123333 -6.112667
25% 162499.750000 11203.500000 ... -1.060428 -0.437920
50% 174999.500000 52248.500000 ... -0.035956 0.138799
75% 187499.250000 118856.500000 ... 0.941469 0.681163
max 199999.000000 196805.000000 ... 5.913273 2.624622
[8 rows x 29 columns]
Index(['SaleID', 'name', 'regDate', 'model', 'brand', 'bodyType', 'fuelType',
'gearbox', 'power', 'kilometer', 'regionCode', 'seller', 'offerType',
'creatDate', 'price', 'v_0', 'v_1', 'v_2', 'v_3', 'v_4', 'v_5', 'v_6',
'v_7', 'v_8', 'v_9', 'v_10', 'v_11', 'v_12', 'v_13', 'v_14'],
dtype='object')
Index(['notRepairedDamage'], dtype='object')
---
['bodyType', 'fuelType', 'gearbox', 'power', 'kilometer', 'offerType', 'v_0', 'v_1', 'v_2', 'v_3', 'v_4', 'v_5', 'v_6', 'v_7', 'v_8', 'v_9', 'v_10', 'v_11', 'v_12', 'v_13', 'v_14']
---
['gearbox', 'power', 'kilometer', 'v_0', 'v_1', 'v_2', 'v_3', 'v_4', 'v_5', 'v_6', 'v_7', 'v_8', 'v_9', 'v_10', 'v_11', 'v_12', 'v_13', 'v_14']
X train shape: (150000, 18)
X test shape: (50000, 18)
sta of label:
_min 11
_max: 99999
_mean 5923.327333333334
_ptp 99988
_std 7501.973469876438
_var 56279605.94272992
None
train mae: 632.1044782154634
val mae: 716.6872722142282
----------
train lgb...
MAE of val with lgb: 707.5136195806954
predict lgb...
Sta of predict lgb:
_min -519.1502598641224
_max: 88575.10877210615
_mean 5922.982425989068
_ptp 89094.25903197027
_std 7377.297141258001
_var 54424513.11041347
train xgb...
MAE of val with xgb: 707.5136195806954
predict xgb...
Sta of predict xgb:
_min -84.89418
_max: 88809.58
_mean 5924.659
_ptp 88894.47
_std 7366.966
_var 54272188.0
MAE of val with Weighted ensemble: 707.4855148878429
SaleID price
0 150000 40448.350777
1 150001 375.141264
2 150002 7519.016810
3 150003 11750.868057
4 150004 581.169751
Process finished with exit code 0
第一次执行
plt.hist(Y_data)#绘制直方图
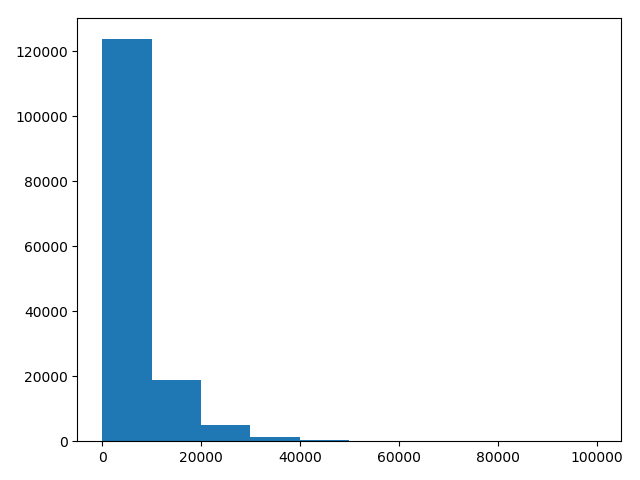 第二次执行
第二次执行
plt.hist(Y_data)#绘制直方图