LSTM实现文本生成
LSTM实现文本生成
数据: 摘取的一段英文
LSTM_text.txt
The United States continues to lead the world with more than 4 million cases of COVID-19, the disease caused by the virus. Johns Hopkins reports that Brazil is second, with more than 2 million cases, followed by India with more than 1 million.
重复90行
#加载数据
data = open("LSTM_text.txt").read()
#移除换行
data = data.replace("\n","").replace("\r","")
print(data)
#分出字符
letters = list(set(data))
print(letters)
num_letters = len(letters)
print(num_letters)
LSTM要建立字符-编号字典
#建立字典
int_to_char = {a:b for a,b in enumerate(letters)}
print(int_to_char)
char_to_int = {b:a for a,b in enumerate(letters)}
print(char_to_int)

#设置步长
time_step = 20
#批量字符数据预处理
import numpy as np
from keras.utils import to_categorical
#滑动窗口提取数据
def extract_data(data,slide):
x = []
y = []
for i in range(len(data) - slide):
x.append([a for a in data[i:i+slide]])
y.append(data[i+slide])
return x,y
#字符到数字的批量转换
def char_to_int_Data(x,y,char_to_int):
x_to_int = []
y_to_int = []
for i in range(len(x)):
x_to_int.append([char_to_int[char] for char in x[i]])
y_to_int.append([char_to_int[char] for char in y[i]])
return x_to_int,y_to_int
#实现输入字符文章的批量处理,输入整个字符,滑动窗口大小,转化字典
def data_preprocessing(data,slide,num_letters,char_to_int):
char_data = extract_data(data,slide)
int_data = char_to_int_Data(char_data[0],char_data[1],char_to_int)
Input = int_data[0]
Output = list(np.array(int_data[1]).flatten() )
Input_RESHAPED = np.array(Input).reshape(len(Input ),slide)
new = np.random.randint(0,10,size=[Input_RESHAPED.shape[0],Input_RESHAPED.shape[1],num_letters])
for i in range(Input_RESHAPED.shape[0]):
for j in range(Input_RESHAPED.shape[1]):
new[i,j,:] = to_categorical(Input_RESHAPED[i,j],num_classes=num_letters)
return new,Output
# 提取X y
X,y = data_preprocessing(data,time_step,num_letters,char_to_int)
print(X.shape)
print(len(y))
(23308, 20, 41)
23308个样本 每个样本20
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.1,random_state=10)
print(X_train.shape,X_test.shape,X.shape)
(20977, 20, 41) (2331, 20, 41) (23308, 20, 41)
y_train_category = to_categorical(y_train,num_letters)
print(y_train_category)
[[1. 0. 0. … 0. 0. 0.]
[0. 0. 0. … 0. 0. 0.]
[0. 0. 0. … 0. 0. 0.]
…
[0. 0. 0. … 0. 0. 0.]
[0. 0. 0. … 0. 1. 0.]
[0. 0. 0. … 0. 0. 0.]]
模型
from keras.models import Sequential
from keras.layers import Dense,LSTM
model = Sequential()
# input_shape 看样本的
model.add(LSTM(units=20,input_shape=(X_train.shape[1],X_train.shape[2]),activation="relu"))
#输出层 看样本有多少页
model.add(Dense(units=num_letters ,activation="softmax"))
model.compile(optimizer="adam",loss="categorical_crossentropy",metrics=["accuracy"])
model.summary()
#训练模型
model.fit(X_train,y_train_category,batch_size=1000,epochs=50)
#预测
y_train_predict = model.predict_classes(X_train)
#转换成文本
y_train_predict_char = [int_to_char[i] for i in y_train_predict ]
print(y_train_predict_char)
# 训练准确度
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_train,y_train_predict)
print(accuracy)
# 测试集准确率
y_test_predict = model.predict_classes(X_test)
accuracy_test = accuracy_score(y_test,y_test_predict)
print(accuracy_test)
y_test_predict_char = [int_to_char[i] for i in y_test_predict ]
训练次数多了 两个准确率都是1
预测文本
new_letters = 'The United States continues to lead the world with more than '
X_new,y_new = data_preprocessing(new_letters,time_step,num_letters,char_to_int)
y_new_predict = model.predict_classes(X_new)
print(y_new_predict)
#转成字符
y_new_predict_char = [int_to_char[i] for i in y_new_predict ]
print(y_new_predict_char)
for i in range(0,X_new.shape[0]-20):
print(new_letters[i:i+20],'--predict next letter is --',y_new_predict_char[i])
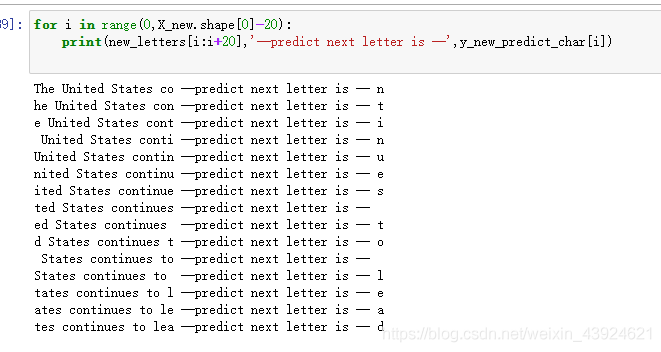
成功预测