cs224n学习笔记 04:Contextual Word Embeddings
课程目标
- Reflections on word representations
- Pre-ELMo and ELMO
- ULMfit and onward
- Transformer architectures
- BERT
Reflections on word representations
之前的CS22N的课程介绍了词向量比如,Word2vec, GloVe, fastText。通过这些词向量能在神经网络的训练中起到一个很好的效果,如图所示:

这种常规的词向量有很多问题,比如unknown-words针对训练词向量unknown-word,有一些解决方法:
- 使用 一个《UNK》表示全部的unknown单词
- 如果test时出现unknown单词,在你的无监督词向量出现过,使用那个词向量作为unknown的词向量。
- 对每一个unknown使用随机的词向量表示
此外,还有一些问题,比如词向量唯一表示单词而不考虑单词在文章中出现的位置,比如一个词在不同的句子中有不同的含义等。
针对这些问题,有人想到单词的词向量表示应该结合单词所在的句子进行考虑。但是标准的Rnn训练只在 task-labeled 的小数据上,后来有人想能不能用词向量的编码,比如lstm的编码来表示单词,并且在大型的无标签的数据上进行训练,于是就产生了Contextual Word Representations。如图

Pre-ELMo and ELMO
tagLM模型采用的就是上面说的这种方法,直接用一个RNN语言模型编码后的隐藏层作为一种特殊的词嵌入向量,如图所示:

- 训练词向量嵌入和语言模型
- 对于输入序列的每一个token将word_embedding和LM_embedding将其结合为新embedding
- 将新的ebedding输入到任务模型中去,输出得到结果
详细的过程如图所示:
ELMo模型和前面的模型相比有如下特点:
- 训练一个双向的LM
- 使用了2层的bilstm网络
- 使用字符级CNN去建立初始词向量
- 使用4096维度的lstm隐藏层但使用了feed-forward层转为512维传向下一个输入
具体如图所示:

ELMo模型一个比较重要的特点是,它不仅使用了LSTM最上面的一层隐藏层,也使用其他隐藏层,对所有的隐藏层做一个权重的求和,得到ebeding的结果,公式如图所示:

使用ELMo完成task
首先,预训练biLM模型得到单词的 representations
冻结上一步得到的biLM的参数
将得到的ELMo权重应用于特定的任务
如图:

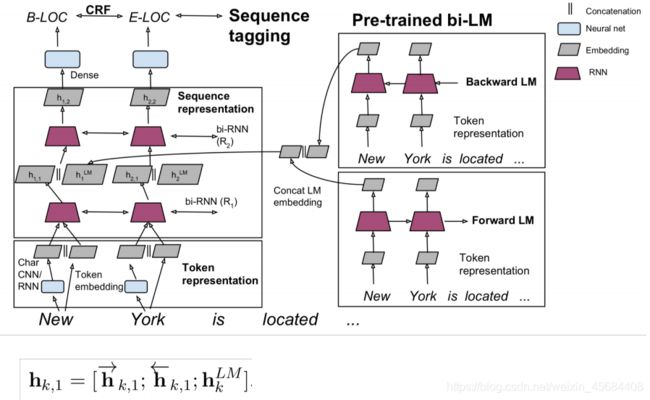
课程给出了将ELMo模型应与sequence tagger任务,如图所示:

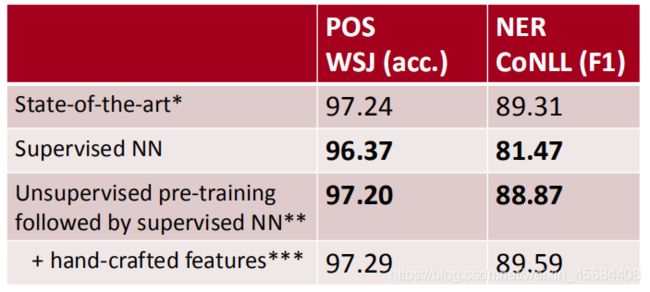
ELMo模型在NLP的很多应用都取得很好的效果,对普通的baseline模型,应用了ELMo后,都取得了一定水平的提升,如图所示:

ELMo的biLSTM NLM层各有特点,也适合不同的NLP任务:
一般来说,低层的权重更适合低层次的语法任务,比如Part-of-speech tagging, syntactic dependencies, NER等;高层的权重更适合层次更好的语义任务,比如Sentiment, Semantic role labeling, question answering, SN等。
ULMfit and onward
课程介绍了和ELMo同时期ULMfit模型,这个模型同样较好的展示了迁移学习的思想,如图所示:

对于模型的处理,UML采用了如下三步:
首先,在一个非常大的数据集(和任务数据集不相关)上训练一个LM模型。
接着,使用任务相关的数据集,对模型进行fine-tune(进行训练,在前一个模型的基础上对参数进行微调)
使用classifier任务继续fine-tune
如图所示:

ULMfit取得的效果也非常的明显,如图:

这中迁移学习的方法在NLP中开了一个头,从此网络越来越复杂,训练的规模也越来越大。
Transformer architectures
《Attention Is All You Need》是一篇Google提出的将Attention思想发挥到极致的论文。这篇论文中提出一个全新的模型,叫 Transformer,抛弃了以往深度学习任务里面使用到的 CNN 和 RNN ,目前大热的Bert就是基于Transformer构建的,这个模型广泛应用于NLP领域,例如机器翻译,问答系统,文本摘要和语音识别等等方向。
总体结构如图所示:

Encoder
Stage 1 - Encoder input
Encoder的输入即是原始的word embedding。由于在Transformer模型中,没有递归,也没有卷积,所以序列中每个标记的绝对(或相对)位置的信息用“位置编码”来表示,因此编码器的输入为:
positional embeddings added + embedded inputs
接下来是由6个相同的层连接组成的,每一层中又包含了两个子层。其中,第一个子层是Multi-Head Attention层,该子层利用多头注意力机制,利用线性变换将Q、K、V映射到不同的子空间(论文中num_heads = 8),从而希望可以学习到单词的不同表示。
stage 2 - Multi-Head Attention
Transformer模型使用了多层注意力机制来代替了single self-attention,以此来提升模型的效果。Multi-Head Attention的效果体现在以下两个方面:
(1)扩展了模型关注不同位置的能力。如上图所示,在不同的context中,使得单词"it"关注到不同的target word。
(2)增强了Attention机制对关注句子内部单词之间作用的表达能力。相比于single self-attention, Multi-Head Attention中的each head都维持了一个自己的Q、K、V矩阵,实现不同的线性转换,这样每个head也就有了自己特殊的表达信息。

这种思想背后的原理即是,当你翻译一个单词的时候,你会基于你所问的问题的类型来对每个单词给予不同的关注程度。例如,当你在“I kick the ball”这个句子中翻译“kick”时,你可以问“Who kick”。根据答案的不同,把这个单词翻译成另一种语言可能会发生变化。或者问其他问题,比如“做了什么?”等等。
stage 3 - Feed Forward
而在Multi-Head Attention层之后还添加了一层Feed Forward层。Feed Forward层是一个两层的fully-connection层,中间隐藏层的单元个数为d_ff = 2048。这里在学习到representation之后,还要再加入一个Feed Forward的作用我的想法是:
注意到在Multi-Head Attention的内部结构中,我们进行的主要都是矩阵乘法(scaled Dot-Product Attention),即进行的都是线性变换。而线性变换的学习能力是不如非线性变化的强的,所以Multi-Head Attention的输出尽管利用了Attention机制,学习到了每个word的新representation表达,但是这种representation的表达能力可能并不强,我们仍然希望可以通过激活函数的方式,来强化representation的表达能力。比如context:The animal didn’t cross the road because it was too tired,利用激活函数,我们希望使得通过Attention层计算出的representation中,单词"it"的representation中,数值较大的部分则进行加强,数值较小的部分则进行抑制,从而使得相关的部分表达效果更好。(这也是神经网络中激活函数的作用,即进行非线性映射,加强大的部分,抑制小的部分)。我觉得这也是为什么在Attention层后加了一个Layer Normalizaiton层,通过对representation进行标准化处理,将数据移动到激活函数的作用区域,可以使得ReLU激活函数更好的发挥作用。同时在fully-connection中,先将数据映射到高维空间再映射到低维空间的过程,可以学习到更加抽象的特征,即该Feed Forward层使得单词的representation的表达能力更强,更加能够表示单词与context中其他单词之间的作用关系。
整个过程的数学公式表达为:其中max即代表了ReLU激活函数
FFN(x) = max(0, xW1 + b1)W2 + b2
BERT
全称:Bidirectional Encoder Representations from Transformers,它采用双向的transformer结构,进行Encoder Representations。
语言模型通常是单向的,通常由左到右或者从右到左进行,但是语言的理解通常是一个双向的过程。所以需要建立一个双向的网络,但是通常的双向编码是会造成Words “see themselves”,如图所示:

BERT模型是一个多层的Transformer,具体Transformer模型结构见,一下模型结构根据代码可得
embedding层:将input_id转化为word embedding
embedding_processor层:word embedding + position embedding(和Transformer一致) +segment embedding(BERT模型创新)
Transformer层
BERT-base: L=12, H=768, A=12, Total Parameters=110M
BERT-large: L=24, H=1024, A=16, TotalParameters=340M
BERT-base为了和OpenAI GPT进行对比,所以模型大小与OpenAI GPT设置一致。不同的在于OpenAI GPT使用left-to-right的self-attention,而BERT使用双向self-atten
输入表示(Input Representation)
无论是单个文本还是文本对,输入都是一个token sequence。其中[CLS]表示sequence的开始,[SEP]表示两个文本的分割。输入向量是由词向量,位置向量和分割向量构成的,如下图:

input embedding= word embedding+ position embedding + segment embedding
word embedding用的是WordPiece embeddings,包含30000tokens
position embedding是学习得到的,支持最长序列长度为512个tokens
[CLS]的隐状态的输出,对于分类问题,可以作为sequence的表示;对于非分类问题,则忽略
句子pair也用一个sequence进行输入。a.利用[SEP]作为两个句子的区分;b.segment embedding可以区分两个句子;对于一个句子的输入,可以只用segment embedding A