MapReduce实现求共同好友
简介
原始数据如下,依次求出两两之间的共同好友
A:B,C,D,F,E,O,j
B:A,C,E,K
C:F,A,D,I
D:A,E,F,L
E:B,C,D,M,L
F:A,B,C,D,E,O,M
G:A,C,D,E,F
H:A,C,D,E,O
I:A,O
J:B,O
K:A,C,D
L:D,E,F
M:E,F,G
O:A,H,I,J
X:A
最终效果如下
A-B C,E
A-C D,F
A-D E,F
A-E B,C,D
A-F B,C,D,E,O
A-G C,D,E,F
A-H C,D,E,O
A-I O
A-J B,O
A-K C,D
A-L D,E,F
A-M E,F
B-C A
B-D A,E
B-E C
.......//省略主要过程如下
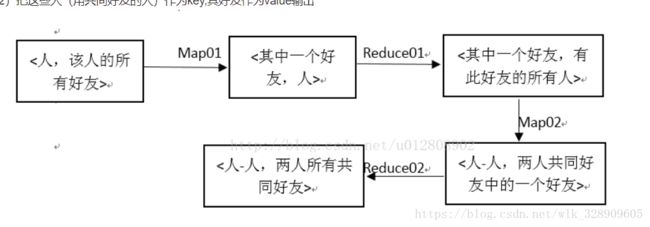
第一步:
给出的数据是一个人的好友有哪些,可以先求出哪些人的共同好友是这个人
map1阶段求出的结果是 B A C A D A E A …
map1的代码如下:
public class MapTask extends Mapper
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] split = value.toString().split(":");
String[] split2 = split[1].split(",");
for (String string2 : split2) {
context.write(new Text(string2),new Text(split[0]));
}
}
}reduce1过程产生的结果是
A K B C D O F X G H I reduce1的代码如下:
public class ReduceTask extends Reducer<Text, Text, Text, Text>{
@Override
protected void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException {
StringBuffer sb = new StringBuffer();
for (Text text : values) {
sb.append(text.toString()).append(" ");
}
String string = sb.toString();
context.write(key, new Text(string));
}
} 第二步:根据第一步的结果再进行Map Reduce运算,
map2的过程结果是 A-B C A-B E//A和B的共同好友是c和e
代码如下:
@Override
protected void map(LongWritable key, Text value, Mapper.Context context)
throws IOException, InterruptedException {
FileSplit fileSplit = (FileSplit)context.getInputSplit();
String name = fileSplit.getPath().getName();
String string = value.toString();
String[] split = string.split("\t");
String friend = split[0];
String[] persons = split[1].split(" ");
Arrays.sort(persons);//排序的原因 只能从前往后 不会出现重复的
//只能出现A-B 不会有B-A
for (int i = 0; i < persons.length-1; i++) {
for (int j = i+1; j < persons.length; j++) {
context.write(new Text(persons[i]+"-"+persons[j]), new Text(friend));
}
}
}
reduce2过程结果是
A-B C,E
A-C D,F
A-D E,F
A-E B,C,D
A-F B,C,D,E,O
A-G C,D,E,F
A-H C,D,E,O
A-I O
A-J B,O
A-K C,D
A-L D,E,F
A-M E,F
B-C A
B-D A,E
B-E C
B-F A,C,E
B-G A,C,E
B-H A,C,E
B-I A
B-K A,C
B-L E
......//省略代码如下:
public class ReduceTask2 extends Reducer<Text, Text, Text, Text>{
@Override
protected void reduce(Text key, Iterable values, Reducer.Context context)
throws IOException, InterruptedException {
StringBuffer sb = new StringBuffer();
Set set = new HashSet();
for(Text friend : values){
if(!set.contains(friend.toString()))
set.add(friend.toString());
}
for(String friend : set){
sb.append(friend.toString()).append(",");
}
sb.deleteCharAt(sb.length()-1);
context.write(key, new Text(sb.toString()));
}
注意:第一次Map Reduce产生的结果作为第二次Map Reduce的输入,路径千万写对