背景
在日益数据量增长的情况下,影响数据库的读写性能,我们一般会有分库分表的方案和使用newSql方案,newSql如TIDB。那么为什么需要使用TiDB呢?有什么情况下才用TiDB呢?解决传统分库分表的什么问题呢?还会解释一些关键点和踩坑点。下面我会用比较白话的形式解读,当做对TiDB进行推广。
目前痛点
目前分库表无论使用原生JDBC+ThreadLocal方案,还是使用中间件proxy、还是SDK嵌入代码的形式,即使用sharding-jdbc、zdal、mycat都存在着以下问题。
- 分库分表算法方案的选型
- 分库分表后带来的后续维护工作,每次增加节点,都需要申请磁盘、机器
- 新增节点需要进行停机、然后迁移数据,停机迁移对线上用户造成实时的读写影响。迁移失败还有代码回滚。迁移前还要等mysql没有binlog产生后才能迁移。
- 分库分表后,跨库一致性问题,都是使用最终一致性,代码维护繁琐。
- 数据存储压力、数据存放量偏移于某个节点
- 数据索引查询效率:即使是分库了,要走索引查询,其实还是需要查询多个库后得出结果后汇聚的。
- 不支持跨库left join其他表
- 唯一索引在跨库跨表不能保证唯一,场景如:支付流水号。现在分库分表的唯一key都很靠应用层代码控制。
- 表加字段麻烦。每个库每个表都要加
目的
分析TiDB如何解决痛点
点赞再看,关注公众号:【地藏思维】给大家分享互联网场景设计与架构设计方案
掘金:地藏Kelvin https://juejin.im/user/5d67da8d6fb9a06aff5e85f7
TiDB整体架构
TiDB是一种分布式数据库。其实形式上来讲比较像Hadoop的做法,把数据分布在不同的机器上,并且有副本,有负责计算的机器、也由负责存储的机器。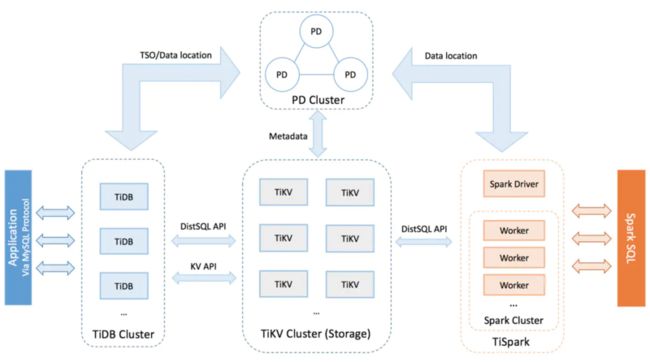
入口层为tidb-server,图中TiDB,是客户端接入的入口,负责处理请求接口,这一层对存储要求不高,用于计算所以对CPU要求高,还有记录每个region的负责的范围。
第二层是PD,负责调度,如zookeeper的形式,负责数据迁移的调度、选举的调度。
第三层是tikv,也叫store,负责真实存储数据的一层。其中tikv由1个或者多个region组成,Region为最小的存储单元,就如JVM G1算法的Region的意思。每个Region将会打散分布在各个tikv下。
数据存储模型
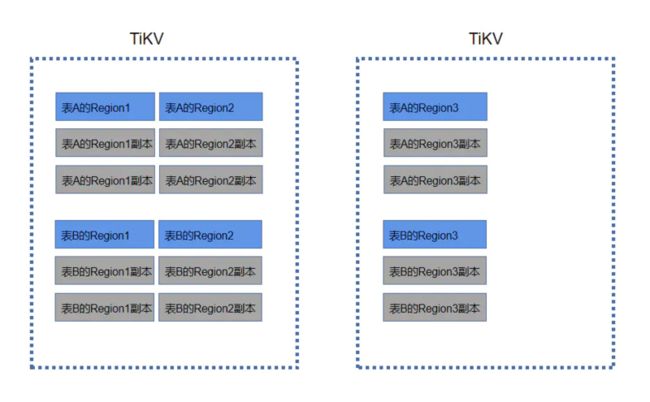
- 行数据(元数据)
一个表将会由一个或者多个Region存储。不同的表将会在不同的Region,而不是如传统分库那样每个库里的表都是相同。
那么一个表下,每一行数据存储在哪个Region下是如何确定呢?
首先,Region里面是一个Map, key 由 table_id表id、rowid主键组成。如:
t[table_id]_r[row_id]
map的value为表中每行数据的真实数据。
- 索引数据
索引数据将会在另外一个Region存储,每建一个索引,就会有那个索引对应的Region。它的Map的 key 由 table_id、index_id 以及索引列的值编码组成。如:
t[table_id]_iindex_id
value为rowid,这样就能用rowid来找到上面的表数据的位置。
就如mysql按索引查询,会先去找索引记录,再去找到主键聚簇索引来获取真实数据一个逻辑。
数据切分
定位在哪个Region,就是靠Key来算出落在哪个Region里面。和分库分表的根据某个字段来一致性hash算法方案不同。
TiDB的负责行真实数据的Region是使用主键范围来划分的。
有索引情况下,负责索引的Region会根据索引字段范围来划分。
基于Key通过计算,将会得出一个数字,然后按范围划分多个区间,每个区间由一个Region管理。
如:一个表数据主键rowid落在3个Region。
[0,10000)
[10001,20000)
[20001,30000)
这个范围需要数据入表前确定这个规则。
因为Region将会分布在所有TiKV上,也就有多个服务器去存数据,所以利用多机器CPU和磁盘,解决了 痛点5存储压力,也解决了 痛点1分库分表用哪个算法方案,只需要确定主键范围即可。
后续会说如何扩容。
提高索引效率
现有问题:
传统分库分表的索引都是在每个mysql实例里,跟着表走的。分库分表规则,一般都是根据表中的userid用户字段或组合性较高的字段来做切分库或者表的键,相同的userid将会落在相同的库或者表。
但是上述情况下,表中的索引字段假设为code,则code="aaa"的可能会因为不同的userid落在不同的库中,需要查询全量的库和表后,再重新聚合,这样就会增加CPU查询的消耗、还有TCP连接握手的消耗。
TiDB解决:
然而TiKV的有专门用于存储索引的Region,它数据结构的Key是由 表id+索引id+索引值id来决定的,value是rowid数据行主键,并且一个Region管理一个范围的Key,所以同一个索引同一个值都会在一个Region里面,这样就比较好快速定位相同的索引值的Region,得出对应的rowid,再根据rowid去存储表数据的Region中更快速找到表真实数据。就不需要走全量库的索引查找,因为mysql索引查找机制是先找到索引值,然后再找聚簇的主键后返回整行数据,从而提高性能。
这种做法有点像elastic-search的倒排索引,先根据value值再定位数据原来位置。这里 解决痛点6减少索引查询压力。
TIDB特性
1. 提供乐观事务模型和悲观事务模型
在3.0.8之前只有乐观事务模型,都是通过2PC两次提交的方式来进行事务提交。如果开启悲观事务模型,会比较像sharding-jdbc的柔性事务,有重试的功能,但是依然重试过多次(256次)失败仍然会丢失。
1.1 优缺点分析
TiDB 事务有如下优点:
- 实现原理简单,易于理解。
- 基于单实例事务实现了跨节点事务。
- 锁管理实现了去中心化。
但 TiDB 事务也存在以下缺点:
- 两阶段提交使网络交互增多。
- 需要一个中心化的版本管理服务。
- 事务数据量过大时易导致内存暴涨。
1.2 事务的重试
使用乐观事务模型时,在高冲突率的场景中,事务很容易提交失败。而 MySQL 内部使用的是悲观事务模型,在执行 SQL 语句的过程中进行冲突检测,所以提交时很难出现异常。为了兼容 MySQL 的悲观事务行为,TiDB 提供了重试机制。
这种加重试就是悲观事务。
上述解决 痛点4,不用再去自己维护跨库处理的事务最终一致性的代码,如A用户转账到B用户,也如商家和买家的情况,商家比较多收入时的交易情况。
虽然重试多次仍然会失败,但是这部分由TiDB处理。如果跨库事务以前的系统有框架处理,那现在就不需要如sharding-jdbc的sdk方式需要靠程序运行时才能重试,不然如果我们程序down机重试就没了。
2. 自动扩容
2.1 Region分裂
Region为最小的存储单元,当数据进入一个Region后达到一定数量,就会开始分裂(默认是超过现有Region负责范围的1/16)。
注意:数据表 Key 的 Range 范围划分,需要提前设置好,TiKV 是根据 Region 的大小动态分裂的。
这里是解决 痛点2的每次都需要申请资源,不再运维来做上线前迁移数据, 痛点3迁移时又要停机影响生成用户。
因为TiDB作为中间件,不带任何业务属性,所以就不能使用userid等字段来做分片规则的键和自定义算法,使用主键是最通用的选择。(其实我觉得如果TiDB能做到就最好了)
2.2 新增存储节点
- 新增节点或者分裂Region,都有可能会触发迁移Region,由TiDB自动完成。不再需要入侵代码、或者使用中间件做分库分表逻辑和数据迁移、上线演练,全程交给运维(手动甩锅)。
- 并且不需要代码服务停机,不需要等没有新sql执行后才能迁移,这个是运行过程中实时迁移数据的。
这里就解决了 痛点3停机迁移数据、痛点5存储压力。
3. 副本容灾
每个 Region 负责维护集群的一段连续数据(默认配置下平均约 96 MiB),每份数据会在不同的 Store 存储多个副本(默认配置是 3 副本),每个副本称为 Peer。同一个 Region 的多个 Peer 通过 raft 协议进行数据同步,所以 Peer 也用来指代 raft 实例中的成员。
所以如果有1亿数据,将会由3亿数据落在磁盘中,虽然消耗磁盘,但是提高了可靠性。
TIDB成本
- 官方推荐至少部署 3 个 TiKV, 3 个 PD,2 个 TiDB。
- TiDB需要能使用线程数多的,PD需要CPU比较好的,TiKV需要SSD和CPU比较好的。
- 在论坛看到大家用的内存都是100G的,磁盘都是2T 的SSD。因为每行数据都总共有3个副本,消耗磁盘多。所以一个系统使用一套TiDB需要不少的成本。
- 然而这只是一个系统所需,一个项目中有多个系统组成情况下,就消耗更多资源了。并且随着数据日益增多将会越来越多资源。
使用场景
- 数据量达到一定量级,需要减少查询压力或者连接池不够等等因素后才需要进行。因为官方建议需要有2个tidb-server、至少两个PD、三个tikv,而且tikv需要都是SSD固态硬盘。所以在这种成本下,不一定所有项目都会使用,公司不一定愿意花成本去使用。而在一些数据量小的情况,建议还是使用mysql,等到数据量上来后,再做数据同步到TiDB。
- 已经分库分表后,希望改为使用TiDB,也能进行合并,需要使用TiDB Data Migration。
- 先在公司的架构组的项目使用,再到不是核心业务的项目使用,最后铺开给核心项目使用。
- 入门成本高,实验起来需要成本,因为官方推荐的部署方式需要多台好的机器。
注意事项与坑点
- 建议使用3.0.4、3.0.8或者4.0.0 (现在是2020年4月2日),不建议使用2.0版本,不然会出现升级不兼容的问题,需要去解决。
- 在增加节点扩容时,或者Region分裂时,同时有SQL执行insert或者更新数据,如果命中到对应的Region正在迁移,就可能会出现insert或者update出错 说“not leader”没有找到对应的位置的意思。但是会有重试的形式,把数据最终提交。
- 提前设置路由Region的分片范围规则,不然导入数据时会都落在一个节点上。如果你以前的主键数据时雪花算法得出的,那就需要求出最大最小值自己算范围手动设置好范围规则。
- TiDB 不支持 SELECT LOCK IN SHARE MODE。使用这个语句执行的时候,效果和没有加锁是一样的,不会阻塞其他事务的读写。
- 不要再使用Syncer同步数据或迁移到TiDB,因为如果在已经分库分表的情况下,使用Syncer同步,在某个帖子看的说会出问题。建议使用TiDB Data Migration
- TiDB无法修改字段类型
总结
其实有了上述功能,就可以减少分库分表的开发、运维维护成本,主要是平常分库分表到一定量要迁移,经常需要监控是否到迁移的量了,迁移时需要演练,迁移时要更新代码或者配置并且停业务是影响最大的。
虽然完成分库分表好像解决了一些问题,但是带来的后续还是很多的,TiDB就给我们解决了上面的问题,这样就可以更加专注的做业务了。
欢迎关注,文章更快一步
我的公众号 :地藏思维
掘金:地藏Kelvin
简书:地藏Kelvin
我的Gitee: 地藏Kelvin https://gitee.com/kelvin-cai