条件随机场(Conditional Random Field, CRF)
主要内容
- 背景知识
- 隐马尔科夫模型
- 马尔可夫随机场
- 条件随机场
- 条件随机场的应用
一、背景知识
生成模型与判别模型。生成模型(Generative Model)对X和Y的联合概率分布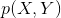 建模,然后通过贝叶斯公式求得
建模,然后通过贝叶斯公式求得![]() ,最后选取使得
,最后选取使得![]() 最大的
最大的 ,即
,即![]() 。判别模型(Discriminative Model)直接对条件概率
。判别模型(Discriminative Model)直接对条件概率![]() 建模,训练模型的过程中学习得到参数
建模,训练模型的过程中学习得到参数 ,预测过程根据得到的参数和输入X,得到输出Y。生成模型包括朴素贝叶斯模型、隐马尔科夫模型HMM等等;判别模型包括LR、条件随机场CRF等等。
,预测过程根据得到的参数和输入X,得到输出Y。生成模型包括朴素贝叶斯模型、隐马尔科夫模型HMM等等;判别模型包括LR、条件随机场CRF等等。
概率图模型。概率图模型是一类用图来表达变量相关关系的概率模型。它以图为表示工具,常见的是用一个结点表示一个或者一组随机变量,结点之间的边表示变量间的概率相关关系。根据边的性质不同,概率图模型可大致分为两类:第一类是使用有向无环图表示变量间的依赖关系,称为有向图模型或者贝叶斯网;第二类是使用无向图表示变量间的相关关系,称为无向图模型或马尔可夫网。若变量间存在显示的因果关系,则常使用贝叶斯网;若变量间存在相关性,但是难以获得显示的因果关系,则常使用马尔可夫网。
马尔可夫链。系统的下一时刻的状态仅由当前状态决定,不依赖于以往的任何状态,即t时刻的状态 仅依赖于t-1时刻的状态
仅依赖于t-1时刻的状态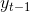 ,与其余的n-2个状态无关,或者说与其余的n-2个状态条件独立,即
,与其余的n-2个状态无关,或者说与其余的n-2个状态条件独立,即![]() 。
。
二、隐马尔科夫模型
隐马尔科夫模型(Hidden Markov Model, HMM)是结构简单的动态贝叶斯网,是有向图模型,属于生成模型。模型图结构如图2.1。状态变量(状态序列)![]() ,其中
,其中![]() 表示第i个时刻的系统状态,通常假定状态变量是隐藏的、不可被观测的,因此状态变量也称隐变量。状态序列其实就是HMM中的隐含状态链,或者说就是隐藏的马尔可夫链。观测变量(观测序列)
表示第i个时刻的系统状态,通常假定状态变量是隐藏的、不可被观测的,因此状态变量也称隐变量。状态序列其实就是HMM中的隐含状态链,或者说就是隐藏的马尔可夫链。观测变量(观测序列)![]() ,其中
,其中![]() 表示第i个时刻的观测值。关于HMM的详细介绍请看oba的另一篇博客,隐马尔可夫模型。
表示第i个时刻的观测值。关于HMM的详细介绍请看oba的另一篇博客,隐马尔可夫模型。
 (图2.1)
(图2.1)
三、马尔可夫随机场
马尔可夫随机场(Markov Random Field, MRF)是典型的马尔可夫网,是无向图模型,属于生成模型。模型图结构如图3.1。图中每个结点表示一个或者一组变量,结点之间的边表示两个变量之间的依赖关系。马尔可夫随机场有一组势函数(亦称“因子”)是定义在变量子集上的非负实函数,用于定义概率分布函数,换言之可以用于度量结点之间的依赖关系。
 (图3.1)
(图3.1)
图3.1表示一个简单的马尔可夫随机场。对于图中结点的一个子集,若其中任意两个结点都有边连接,则称该结点子集为一个“团”。若在一个团中加入另外任何一个结点都不再形成团,则称该团为“极大团”;换言之,极大团就是不能被其他团所包含的团。图3.1中,都是团,但是
![]() 不能构成团,因为
不能构成团,因为![]() 之间缺乏连接;同时,除了
之间缺乏连接;同时,除了![]() 之外都是极大团。
之外都是极大团。
势函数可以定量刻画团中变量之间的相关关系。
马尔可夫随机场中,多个变量之间的联合概率分布能够基于团分解为多个因子的乘积,每个因子只与一个团相关。即多个变量之间的联合概率分布能够分解为多个势函数的乘积,每个势函数只与一个团相关。对于n个变量![]() ,所有团构成的集合为C,对于团Q(其中
,所有团构成的集合为C,对于团Q(其中![]() )对应的变量集合记为
)对应的变量集合记为![]() ,则联合概率分布
,则联合概率分布![]() 定义为
定义为
![]() (公式3.1)
(公式3.1)
其中,![]() 是与团Q对应的势函数,用于对团Q中变量之间的相关关系进行建模。
是与团Q对应的势函数,用于对团Q中变量之间的相关关系进行建模。![]() 是规范化因子,对概率分布进行归一化操作。
是规范化因子,对概率分布进行归一化操作。
显然,如果变量的个数较多,则团的数目会很多(例如所有相互连接的两个变量都会构成团)。这就意味着公式3.1会有很多乘积项,计算的代价变大。同时,我们注意到如果团Q不是极大团,那么它一定被一个极大团![]() 所包含,即
所包含,即![]() ,例如
,例如![]() 不是极大团,但是他们被极大团
不是极大团,但是他们被极大团![]() 所包含;这就意味这变量
所包含;这就意味这变量![]() 之间的关系不仅体现在势函数
之间的关系不仅体现在势函数![]() 中,还体现在
中,还体现在![]() 中。于是联合概率分布
中。于是联合概率分布![]() 可以基于极大团来定义。假设所有极大团构成的集合为
可以基于极大团来定义。假设所有极大团构成的集合为![]() ,那么
,那么
![]() (公式3.2)
(公式3.2)
例如,图3.1中联合概率分布![]() ,其中
,其中![]() 定义在极大团
定义在极大团![]() 上,所以无需再为
上,所以无需再为![]() 构建势函数,从而减少了计算量。
构建势函数,从而减少了计算量。
四、条件随机场 CRF
条件随机场(Conditional Random Field, CRF),不同于隐马尔科夫模型和马尔可夫随机场,它属于判别模型。可以看作是给定观测变量的马尔可夫随机场。观测序列![]() ,标记序列(状态序列)
,标记序列(状态序列)![]() ,条件随机场的目标是构建条件概率模型
,条件随机场的目标是构建条件概率模型![]() 。其中,标记变量Y可以是结构型变量,即其分量(元素)之间具有某种相关性。
。其中,标记变量Y可以是结构型变量,即其分量(元素)之间具有某种相关性。
假设![]() 表示一个无向图,其结点V与标记变量Y中的元素一一对应。假设
表示一个无向图,其结点V与标记变量Y中的元素一一对应。假设![]() 表示与结点v对应的标记变量,
表示与结点v对应的标记变量,![]() 表示v的邻接结点。如果G中每个变量
表示v的邻接结点。如果G中每个变量![]() 都满足马尔可夫性(见上文马尔可夫链),即
都满足马尔可夫性(见上文马尔可夫链),即![]() ,那么(Y,X)构成一个条件随机场。理论上图G可以有任意结构,只要能表示标记变量之间的条件独立性即可,这里主要讨论链式条件随机场,如图4.1。
,那么(Y,X)构成一个条件随机场。理论上图G可以有任意结构,只要能表示标记变量之间的条件独立性即可,这里主要讨论链式条件随机场,如图4.1。
 或者
或者 (图4.1)
(图4.1)
类似于马尔可夫随机场通过势函数和团定义联合概率分布的方式,条件随机场通过势函数和团定义条件概率分布。给定观测序列![]() ,图4.1中的链式条件随机场主要包含两种关于标记变量的团,即单个标记变量
,图4.1中的链式条件随机场主要包含两种关于标记变量的团,即单个标记变量![]() 和相邻的标记变量
和相邻的标记变量![]() 。在条件随机场中,选用指数势函数并且引入特征函数,构造条件概率分布
。在条件随机场中,选用指数势函数并且引入特征函数,构造条件概率分布
 (公式4.1)
(公式4.1)
其中,![]() 表示观测序列为
表示观测序列为 时(或者理解为观测值为
时(或者理解为观测值为 时)标记序列中相邻两个标记位置上的转移特征函数,用于刻画标记序列中相邻标记变量之间的相关关系,可以类比隐马尔可夫模型中的状态转移概率矩阵,不同的是这里是在观测序列为的情况,也就是说不同的观测序列下转移特征函数可能不同。
时)标记序列中相邻两个标记位置上的转移特征函数,用于刻画标记序列中相邻标记变量之间的相关关系,可以类比隐马尔可夫模型中的状态转移概率矩阵,不同的是这里是在观测序列为的情况,也就是说不同的观测序列下转移特征函数可能不同。![]() 表示观测序列为时(或者理解为观测值为时)标记序列第
表示观测序列为时(或者理解为观测值为时)标记序列第 个标记位置上的状态特征函数,用于刻画标记序列第个标记变量受观测序列的影响程度,可以类比隐马尔可夫模型中的观测概率矩阵。
个标记位置上的状态特征函数,用于刻画标记序列第个标记变量受观测序列的影响程度,可以类比隐马尔可夫模型中的观测概率矩阵。 和
和 是对应项的参数,
是对应项的参数, 为规范化因子,对概率分布进行归一化操作。
为规范化因子,对概率分布进行归一化操作。
五、条件随机场的应用
条件随机场在NLP领域应用广泛,尤其是序列标注方面,例如中文分词、词性标注、实体识别等等,主要用来进行句子或者query维度的分析。这里我们以实体识别为例,例如下边图5.1的query。

其中,artist表示歌手,song表示歌曲,是我们需要从句子中识别的实体。O表示没有实体意义的字,B表示实体的第一个字,E表示实体的最后一个字,I表示实体的中间部分。这里是用基于BIEO的方式进行标注,其中,两个字构成的实体只需要BE进行标注,单个字构成的实体只需要B进行标注。也可以用基于BIESO的方式进行标注,其中,单个字构成的实体通过S标注。
上面的标注结果是基于字粒度(character)的分析,当然也可以基于词粒度或者token粒度的分析,具体情况,需要根据业务问题而定。例如,可以作成基于词粒度的表示方式,尤其是针对英文,基于单词(string)的粒度表示往往比基于字母(character)的粒度表示效果要好;或者,针对每个query,如果在预测阶段能够得到和训练阶段一致的分词结果,而且分词结果置信(没有过多的由于分词导致的噪声),也可以用基于词粒度的方式进行表示。当然,可以作成基于token粒度的表示方式,前提是能够针对每个query获得比较精准并且一致的token描述。
图5.1中,query就是CRF中的观测序列![]() ,序列标注就是CRF中的状态序列
,序列标注就是CRF中的状态序列![]() 。CRF的目的就是已知
。CRF的目的就是已知 的情况下,求解概率
的情况下,求解概率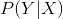 最大情况下的
最大情况下的 。即已知query,求解最有可能的序列标注结果。结合图5.1,回顾上文CRF的条件概率分布函数。转移特征函数描述的是“观测值为‘杰’时,状态值由I-artist到E-artist(或者B-artist到I-artist)”发生的可能性。状态特征函数描述的是“观测值为‘杰’时,对应的状态值等于I-artist”发生的可能性。转移特征函数和状态特征函数,以及对应项的和,就是我们训练阶段需要学习的参数。
。即已知query,求解最有可能的序列标注结果。结合图5.1,回顾上文CRF的条件概率分布函数。转移特征函数描述的是“观测值为‘杰’时,状态值由I-artist到E-artist(或者B-artist到I-artist)”发生的可能性。状态特征函数描述的是“观测值为‘杰’时,对应的状态值等于I-artist”发生的可能性。转移特征函数和状态特征函数,以及对应项的和,就是我们训练阶段需要学习的参数。
训练完成之后,带入公式4.1,就可以求得所有状态序列的概率,选取概率最大的状态序列即为最终的序列标注结果。如何通过代码程序,选取概率最大的状态序列呢?答案非常简单,这是一道动态规划题目。具体可以参考oba之前的博客隐马尔可夫模型中的维特比算法。