验证HBase新特性MOB并发读与写到底性能如何?
验证HBase新特性MOB并发读与写到底性能如何?
- 1. HBase MOB是什么?
- 2. 搭建环境并造数据
- 3. 测试场景
- 3.1 入库
- 3.2 查询
- 4. 测试结果
有没有兄弟突然接到领导的任务是这样子的?
“ 听说HBase 2.X 有个新特性MOB,你给咱测测他的性能。”
然后给拨了几台物理机,什么多的描述都没了,此时让人真心想把笔与本子扔他脸上,来句老子不弄!哎,一系列原因还是得弄啊~。
遇到这种常见问题,本博主从解决问题的思路上给大家分享一下。
- 1、先来看看什么是HBase MOB新特性,不然验证漫无目的;
- 2、测试数据得准备吧,至少得有1T基线吧,再分享一下在造数据过程中的心酸史;
- 3、重头戏~,编写并发入库与并发查询的代码,再调优;顺道再讲讲这里面有多少坑。
1. HBase MOB是什么?
HBase存储小文件(小于10K)十分出色,读写延迟低。对文档、图片和其他中等大小文件(100K-10M)的存储需求日益增长,并且要保持读写低延迟。一个典型的场景就是,银行存储客户的签字或扫描的文档。另一个典型的场景,交通部门保存路况或过车快照。通常只写入一次的中等大小文件。
存储这类文件时,由于 compaction 会导致性能下降。一个可能的场景,交通摄像头每天产生1TB的照片存到 Hbase 里,不断的 flush 生成一些小文件。根据 compaction 策略,数据可能会经过多次 compaction,数据因为压缩被重复写入新的大文件中。随着中等大小文件(moderate objects, MOBs)的积累,compaction 产生的读写会使 compaction 变慢,进一步阻塞 Memstore flush,最终阻塞更新。大量的 MOB 存储会触发频繁的 region split,相应region的可用性下降。
为了解决这个问题,Hbase的实现了对MOB的支持 (hbase-11339: HBase MOB,被合入的2.0.0版本,可以在CDH 5.4.x中获取)。对 MOB 的操作通常集中在写入,很少更新或删除,读取不频繁。MOB 通常跟元数据一起被存储。元数据相对 MOB 很小,通常用来统计分析,而 MOB 一般通过明确的 row key 来获取。
用户希望在 HBase 中用相同的 API 来读写 MOB 文件,并且保持低延迟,强一致性、安全、快照和 HBase 副本等特性。要达到这一目标,必须将 MOB 从 HBase 主要的读写目录移到新的读写目录。
HBase MOB 架构设计

由于大部分担心来自于压缩带来的IO,将 MOB 移出普通 region 的管理来避免 region split 和 compaction。HBase MOB 设计类似于 HBase+HDFS 的方式,将元数据和 MOB 分开存放。
不同的是服务端的设计:MOBs 在被刷到磁盘前缓存在 memstore 里,每次刷新 MOBs 被写入 MOB File(特殊的 HFile)。每个 MOB File 有多个入口相比于每个 MOB 一个 HDFS 文件的方式。MOB File 被放在特殊的 region 管理。读写都通过现有的Hbase API。
MOB文件读写
MOB 有一个最小值(阈值):如果 cell 长度大于这个值,这个 cell 就被认为是一个 MOB cell。

当 MOB cell 被更新时,会被写入 WAL 和 Memstore,跟正常的 cell 没区别。当刷新的时候,MOBs 被刷新到 MOB file,元数据和 MOB file 的路径被刷入 store file。数据一致性和副本都是原生的。
通过改变阈值,cell 可以在 store file 和压缩过的 MOB file 之间移动,默认的阈值设置为100KB。
如下图,Store file 中包含 MOB file 路径的 cell 被叫做 reference cells。Tags 在单元格中保留,所以我们可以继续依赖 Hbase 的安全机制。

reference cells 通过 reference tags 与正常的 cells 区分。reference tag 表示 MOB file 中的一个 MOB cell,因此需要在读取的时候进一步转换。
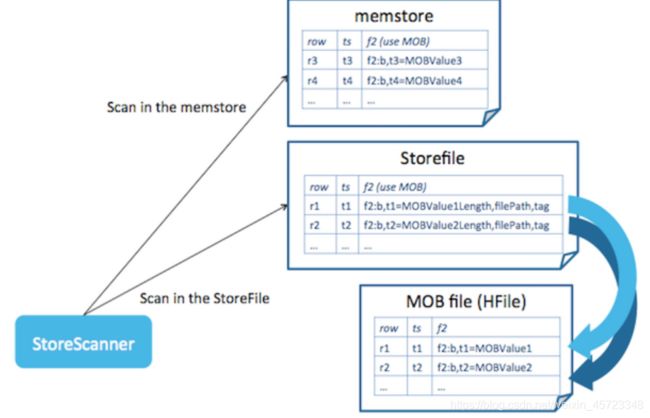
读取的时候,store scanner 会扫描 memstore 和 store file,如果遇到 reference cell,scanner 会读取单元格里的文件路径,通过相同的 row key 到 MOB file 中查找。扫描 MOB file 可以启用 block cache,可以加速查找。
这里不需要打开所有 MOB files 的 reader,只需要打开一个。随机读取不会受文件数量的影响,所以,不需要一遍又一遍的压缩足够大的文件。
MOB 文件名是可读的。由3部分组成,start key 的MD5值 + MOB 文件中的 cells 最新日期 + UUID。通常,MOB 有一个用户定义的过期时间,因此可以通过比较第二部分来找到、删除过期的 MOB files。
2. 搭建环境并造数据
搭建环境
HBase-2.3.0下载路径
Hadoop-3.2.1下载路径
Zookeeper-3.4.14下载路径
安装步骤参照官网步骤此处就不过多介绍,我在这里就以我们测试用的集群部署来举例,目前一台HMaster,剩下两台为HRegionServer的三节点集群测测试。
造数据
1、弯路一:
其他项目组只提供了50G的原始图片数据,目测大小为5k-100k左右,需要自己写程序将其翻成1T的测试数据,我就霹雳啪啦敲了并发翻数据的代码(https://github.com/springup2019/HBase_MOB/tree/master/src/com/fh/zj/copydata),这里不多说,就是将原生50G的图片文件全部文件名重命名,发现这么测在多并发下貌似测不出东西,需要那种数据不一样的测试。没想清楚就敲代码就是费时费力啊。
2、弯路二:
别的团队能够提供大概1T的原始图片与小视频,心想这下应该能测了吧,结果在自己编写的并发入库的代码上一跑,总是把客户端Queue堆满,不是OOM就是频繁触发fullGC,性能很难控,经过一系列定位,发现原始测试文件大的太大,小的太小,小的居然1-2K,大的8-9M 特别不均匀,前面生产者构造PUT的速度要不是跟不上调用HBase客户端PUT执行速度,就是全部堆积到队列里了,简直太难控制;
决定清洗一把数据,只留下100K-10M之间的 缩短他们的差距,发现测试后全部瓶颈都到磁盘读取构造PUT上了,根本构造PUT跟不上调用HBase Client入库执行的速度,结果也很不理想,HBase RegionServer端抓了几个堆栈信息,发现全部都是在waiting请求,不行不行。
3、弯路三:
不行压力全都在本地磁盘读上,磁盘都已经压满了,怎么办呢,决定将所有测试数据都拷贝到HM上,毕竟次数HM测试的机器上有6块盘,这样6块盘一起并发读一定构造读文件构造PUT的速度不会阻碍后面执行的速度了吧!结果拷贝了一天一晚上,还没拷贝完,太影响验证进度了,让这周出结果呢,怎么办?这样肯定是不行的。
4、正确道路
自己在内存中造数据算啦,不用什么读文件构造PUT了,直接内存中产生自己想要大小范围的测试数据,这样瓶颈不就没了,说整咱就动手写~
Random random = new Random();
// maxFileSize, minFileSize 为想要数据的范围
int picSize = minFileSize + (int)(Math.random() * (maxFileSize - minFileSize + 1));
// 造数据
byte[] buffer = new byte[picSize];
random.nextBytes(buffer);
// 构造put
String rowkey = fileName;
Put put = new Put(rowkey.getBytes());
put.addColumn(familyName.getBytes(), QUALIFIER_NAME.getBytes(), buffer);
就这么定了,造测试数据就到此为止。
3. 测试场景
在不同文件规格情况下按5,20,50,100并发来测入库与查询,文件规格分成小文件(100K~500K),大文件(1M-5M)两种来拆分,那么来了 该如何测呢?
3.1 入库
把构造数据当做生产者,调用HBase Client执行PUT命令当做消费者,一个典型的生产者消费者模型就出来了,那么就边构造,边入库吧!
在测试过程中遇到两个问题,解决过程如下:
1)先拿20G小量数据来测试时,发现入得非常慢,抓了几个RegionServer堆栈信息发现全部卡在WAL日志上,看来在构造HBase PUT时将WAL日志关闭,关闭方法如下:
put.setDurability(Durability.SKIP_WAL); //关闭WAL日志
发现关闭后性能确实提高了三分之一左右。
2)验证MOB新特性按照下面方式建表的:
create ‘mob_table’,{NAME => 'mob', MOB_THREADSHOLD => '10240', IS_MOB => 'true'}
- MOB_THREADSHOLD: 设置MOB阈值,超过阈值被当做MOB存储,此处设置为10K;
- IS_MOB:此项是开启MOB特性必备。
问题来了,发现这么建表在并发PUT场景下,磁盘压力还是上不去,并发效果不明显,于是发现所有的压力都在单region上,怎么办呢,那就预分region吧,提前在建表时提前多创建几个region,put构造时,将数据轮询式放入这几个region中,这样不就散开啦,创建表方式(预创建5个region)如下:
create ‘mob_table’,{NAME => 'mob', MOB_THREADSHOLD => '10240', IS_MOB => 'true',SPLITS => ['000','001','002','003','004']}
上面的坑都填差不多了,那么开测吧!
我编写的并发put代码地址:https://github.com/springup2019/HBase_MOB/tree/master/src/com/fh/zj/hbase/putdata
3.2 查询
并发查询,怎么测呢,数据是边造边入的,怎么拿到rowkey然后并发GET呢?
这点就看出我们的并发PUT测试的日志是否输出的完美并且可用,我这里就用到PUT输出的ROWKEY信息,我把此信息用脚本全部收集到一个文档中,我并发着读取此rowkey的文档来构造GET,再依附着构造好的GET调用HBASE Client的Get接口来进行并发测试。
好那么看看我怎么从日志中收集ROWKEY并输出来当做并发查询的入口呢?
用下面shell命令提取ROWKEY:
grep "ROWKEY:*" put.log | while read line; do tmp=${line#*|}; echo ${tmp%|*}; done > rowkey.txt
由于我并发PUT时日志中做了关键字,“ROWKEY:” 开头, 并且将我要的信息夹在了“ || ”双竖杠中间,那么我提取出来特别容易,小伙伴们也可以参考着来。
那么我们就就可以也参考着生产者消费者模式,边读Rowkey构造Get,边调用HBASE Client的Get接口来执行,Action!~
我编写的并发get代码地址:
https://github.com/springup2019/HBase_MOB/tree/master/src/com/fh/zj/hbase/getdata
4. 测试结果
先不列我的测试结果的列表,就看看在入库与查询下,我们把单盘压起来的状态看看是不是很给力:
并发入库 (100-120M/s):

并发查询(25-30M/s):
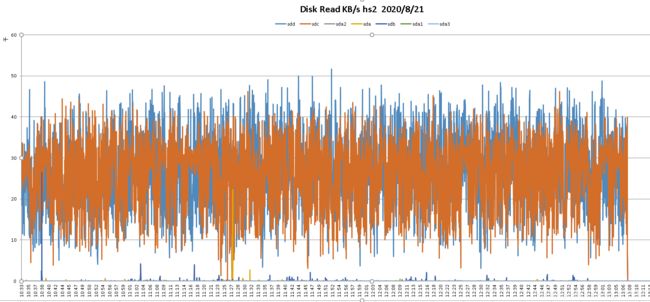
从上面的测试结论上来看,MOB新特性在性能提升方面还是很可观的。