hbase的高级特性
Compaction(StoreFile合并机制)
条件
1、当一个Region中所有MemoryStore内存之和大于hbase.hregion.memstore.flush.size(默认大小是:134217728字节(128M))的时候,这个MemoryStore所在的Region中的所有MemoryStore都会写到磁盘
2、当一个HRegionServer中所有的MemoryStore加在一起的大小大于hbase.regionserver.global.memstore.upperLimit,默认大小是堆内存的40%,那么这个HRegionServer中的所有的Region中的内存数据都会flush到磁盘中,当所有的内存使用达到hbase.regionserver.global.memstore.lowerLimit的时候就不会flush了
随着时间的推移,Store中小的HFile越来越多,使得性能下降,这个时候就需要Compaction了
Compaction其实就是将小的HFile文件合并成大的HFile文件
Compaction:
Minor compactions:选择一个Store中的小量的HFile进行合并成一个大的HFile文件,范围是:某个Region下的某个Store中(局部范围内),这个执行起来效率很高,不会影响hbase的正常执行
Major compactions:合并一个表的所有Store中的HFiles,使得一个Store只有一个HFile(大范围),默认每隔7天执行一次,需要的资源很多,可能会影响hbase的性能
1、Major Compaction还会真的删除需要删除的数据
2、Major Compaction还会真的删除多余版本的数据
3、默认是每7天会自动执行一次,将hbase.hregion.majorcompaction(默认是604800000 milliseconds,即7天)设置为0的话,则表示禁止自动压缩
手工major
compaction: major_compact ‘表名’
也可以在监控界面中进行手工compaction

Region Split
pre split(预切分)
一般来说创建表的时候,一开始默认是给这张表分配一个Region的
那么问题来了,一个Region存在一个RegionServer中,客户端要给这个Region操作的时候,也是给这一个RegionServer发请求,那么一旦客户端一下子给这个Region发了很多请求,那么这个RegionServer很可能就被搞死了(这种场景就叫Hotspotting)
针对这种问题我们采用表的pre-split可以解决这个问题:
分为四个region,下面是三个切割点
create ‘test_pre_split’,‘f’,SPLITS => [‘10’,‘20’,‘30’]

以上方式写数据的案例:
put ‘test_pre_split’,‘0row’,‘f’,‘123’ 这条数据会进入10那个region中去
按照文件里的值进行切分
create ‘t14’,‘f’,SPLITS_FILE=>’/home/jrq/splits.txt’
另外的创建方式
根据随机字节键创建包含四个区域的表
create ‘t2’,‘f1’, { NUMREGIONS => 4 , SPLITALGO => ‘UniformSplit’ }
NUMREGIONS :多少个region
SPLITALGO :切分的算法
这种方式节省空间,但是可读性比较差,用于rowkey是随机的字节的情况
最小值为(byte)0x00
最大值为(byte)0xFF
根据十六进制键创建包含五个区域的表
create ‘t3’,‘f1’, { NUMREGIONS => 4, SPLITALGO => ‘HexStringSplit’ }
需要更多的空间,但是可读性比较好,用于十六进制字符串的rowkey,比如md5的rowkey
最小值为00000000
最大值为FFFFFFFF
auto split
当一个Region达到一定的大小的时候,这个Region会自动切分成两个Region
切分策略:
onstantSizeRegionSplitPolicy:
当一个Region的大小大于hbase.hregion.max.filesize(默认是10G)的时候就切分
IncreasingToUpperBoundRegionSplitPolicy(这个是默认的切分策略,也是最主要的切分):
规则算法:Min (R^3 * “hbase.hregion.memstore.flush.size * 2”, “hbase.hregion.max.filesize”)
一开始只有一个region的时候,在1^3 * 128M*2=256M的时候会切分,现在有2个region了
那么下次切分的需要达到2^3 * 128M * 2 =2048M的时候才会切成3个
下次呢,则是3^3 * 128M *2=6912M的时候才会切分
最终达到配置hbase.hregion.max.filesize的时候为止
KeyPrefixRegionSplitPolicy:
如果你的RowKey有前缀的话,那么相同的前缀的RowKey肯定是在同一个Region中
怎么指定切分策略:
1.在hbase-site.xml中配置全局默认的切分策略
#这就是默认的切分策略
hbase.regionserver.region.split.policy
org.apache.hadoop.hbase.regionserver.IncreasingToUpperBoundRegionSplitPolicy
2.使用Java API在创建table的时候指定切分策略
HTableDescriptor tableDesc = new HTableDescriptor(“test”);
tableDesc.setValue(HTableDescriptor.SPLIT_POLICY, ConstantSizeRegionSplitPolicy.class.getName());
tableDesc.addFamily(new HColumnDescriptor(Bytes.toBytes(“cf1”)));
admin.createTable(tableDesc);
3.使用hbase shell在创建table的时候指定切分策略
hbase> create ‘test’, {METADATA => {‘SPLIT_POLICY’ => ‘org.apache.hadoop.hbase.regionserver.ConstantSizeRegionSplitPolicy’}},{NAME => ‘cf1’}
关闭auto-split
有些场景不需要它自动的切分,因此可以用下面的方式来做
将hbase.hregion.max.filesize设置很大,且将切分的策略设置为:ConstantSizeRegionSplitPolicy
强制手工split
在hbase shell中执行:
split ‘test_split’,‘b’
test_split:table
b:rowkey
也可以在控制界面中进行强制split

auto-split的实现步骤
1、RegionServer决定split一个Region,那么这个RegionServer需要获得一个对这个Region所在表的共享读锁,防止在split期间客户端对数据的修改,所以在zk node /hbase/region-in-transition下创建了一个节点/hbase/region-in-transition/region-name, 且将这个节点的值设置为SPLITING
2、Master监听/hbase/region-in-transition节点,知道了有region在进行split
3、RS在HDFS上的parent_region目录下创建一个名为.split的子目录
4、RS将parent region关闭掉,使得这个spliting的region对外不提供服务了,如果这个时候客户端有来访问这个region的,则会抛出NotServingRegionException异常
5、RS为两个子Region分别创建文件目录
6、RS为两个子Region分别创建parent_region的引用文件目录,剋是对parent_region的store file进行切分并将切分的文件数据移到对应的daughter中的文件目录上来
7、修改.META.中parent Region的元数据信息
8、并发打开两个子Region
9、两个子Region的信息同步到.META.中
10、RS更新znode中节点/hbase/region-in-transition/region-name的值为SPLIT,Master会检测到值的改变
太多的region
所有的MemoryStore加起来的大小如果大于hbase.regionserver.global.memstore.upperLimit默认大小是堆内存的40%,则会进行compaction
Region太多 -> compaction愈来愈多 -> Compaction storm(风暴,影响很大)
太多的region的影响
1、snapshots time out
2、compaction storms
3、客户端的操作会超时(比如flush)
4、bulk load会超时(可能会抛出RegionTooBusyException)
造成太多region的原因
1、为每一个Region的file size配置过小(hbase.hregion.max.filesize)
2、不合理的对region进行了切分或者预切分
merge region(如果region出现过多怎么解决)
merge_region ‘ENCODED_REGIONNAME’,‘ENCODED_REGIONNAME’ (合并两个region)
merge_region ‘ENCODED_REGIONNAME’,‘ENCODED_REGIONNAME’ ,true (true表示立即执行合并操作)
ENCODED_REGIONNAME:
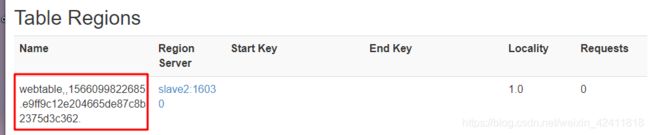
Balancing的功能
1.保持Region可以均匀的分布在每一个RegionServer上
2.HMaster每隔:hbase.balancer.period(默认是300000ms即5分钟)会进行一次Balance
Snapshot
用于数据的恢复或重跑,或者备份
在hbase-site.xml中配置如下参数,然后开启snapshot功能
hbase.snapshot.enabled
true
然后同步,重启
hbase> snapshot ‘myTable’, ‘myTableSnapshot-122112’
hbase> list_snapshots
hbase> clone_snapshot ‘myTableSnapshot-122112’, ‘myNewTestTable’
disable ‘myTable’
#恢复数据
restore_snapshot ‘myTableSnapshot-122112’
enable ‘myTable’
hbase> delete_snapshot ‘myTableSnapshot-122112’