CVPR2019论文基于异常特征来定位图像中的篡改痕迹(ManTra-Net: Manipulation Tracing Network For Detection And Localiztion)
1. Introduction
现实中的图像篡改取证问题一般都是有各种各样的篡改类型,有时候甚至是组合的篡改攻击,为了解决这个问题,本文提出了一种统一的深度神经网络架构,ManTra-Net。 不同于现有的很多方法,ManTra-Net是端到端的,即输入一张图片,输出一张同样尺寸的灰度图,其中原图中被篡改的位置概率值大。并且网络对输入图像尺寸无要求,支持拼接,copy-move,removal,enhancement等篡改类型。这篇论文一共不声不响的干了三件事:
- 设计了一个简单但是有效的自监督学习任务,分类385中图像篡改类型。385种类型
- 将图像篡改位置检测问题作为一个局部异常检测问题,并且提出了一个新的基于LSTM的检测这些局部异常的办法。
- 设计了精细的实验,系统的优化了文中提出的这个网络。
(PS:此篇论文的一作是亚马逊的,虽然文中表示此工作是在加入亚马逊之前完成的…论文地址)
2. Proposed framework
2.1 相关的一些工作。一张图明了:
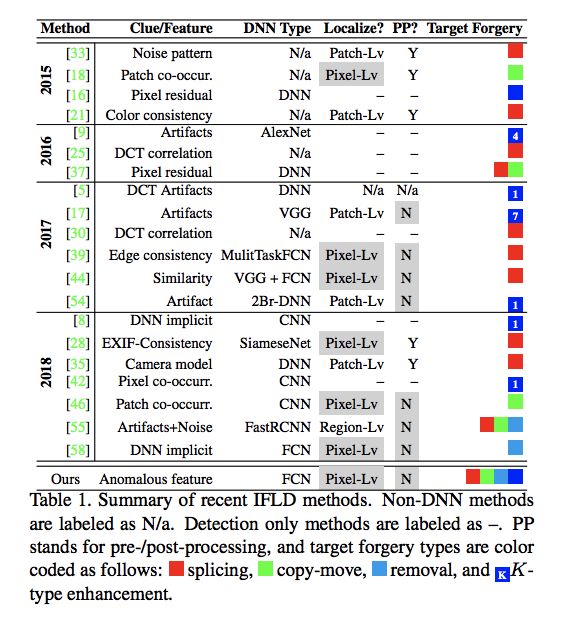
2.2 网络结构概览

从上面的网络中可以看出,整个网络结构分为两个子网络,第一个子网络负责篡改痕迹特征提取,并且提供一种统一的特征表达,第二个子网络,即局部异常检测网络(local anomaly detection network (LADN)) 直接定位被篡改的区域。在这个网络中,论文一共做了三点贡献:
- 重新定义了图像篡改痕迹特征,之前的特征只能用于判断一些已知的篡改类型。现在可以分辨385种篡改类型,其中甚至包含了基于深度学习的inpainting.
- 丢弃了之前在篡改定位上一直使用的基于语义分割的方法,而是提出一种基于异常位置检测的方法,提高了泛化性能。主要是想学习一个精确的映射函数,这个函数能把局部特征映射到一个具体的篡改类型。为了实现这个目标,提出两个设计:(1)ZPool2D DNN layer, 通过Z-Score的方式来标准化局部特征和映射的类型之间的loss函数值(2)一个级联的分析,在不同分辨率level的ZPool2D层上去分析Conv2DLSTM的结果。
- 进行了一系列的实验。
2.3 实验的一些设置。
IMC——image manipulation classification (IMC).
IFID—— image forgery localization/detection (IFLD).
篡改痕迹特征提取,即篡改分类(IMC任务)
使用Dresden数据集作为原始数据,按照8:1:1去划分训练集,验证集,测试集。并且将每张图像crop成256256 的大小,去重之后,得到了1.25M(millions)的图像patch。对这些patch的处理如下:(1)随机的选取一个patch P和一种篡改方式y(385种之一),对P应用y,再从P中随机crop出128128的region作为X,则(X,y)作为一个输入和输出样本对对于篡改分类的任务。
异常区域定位,IFLD任务。
此处用了四个数据集,分别是拼接数据集1,copy-move数据集2,消除数据集,用Dresden数据集和OpenCV制作的,以及增强数据集,其中增强数据集的制作有些麻烦,具体步骤如下:(1)引用了一个mask M参考31合成增强后的图片Z = P*(1-M)+y§*M,P和y为之前的patch和随机的一个篡改方式(3)将(Z,M)作为LADN任务的一个输入和输出对。
训练参数设定
batchsize = 64, 一个epoch有1000个patches。使用Adam优化方法,学习率1e-4,如果验证集loss有20个周期还不降的话,学习率减半。使用交叉熵损失函数。
IMC篡改分类网络
小试牛刀
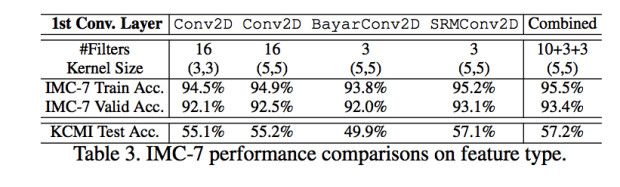
因为这块之前也没有统一的框架,所以,使用了三种分类网络的对比,三种网络的引用和结果如下图。为了加快训练过程,先进行了一个IMC-7种篡改分类的任务( 分别是compression, blurring, morphology, contrast manipulation, additive noise, resampling, and quantization)。并且在Kaggle Camera Identification Datasets上面进行测试。

最后发现VGG的最好,所以选择了VGG,并且在不同的卷积核使用上也做了一系列的实验,最后选择了最好的组合卷积特征。
拓展到385种
将七种的篡改定为level0,再将这几种篡改类型进行细分,比如将blurring细分为Gaussian blur,中值blur等等几种。一共进行6个level,对应的种类分别为7,25,49,96,185,385,如下表:
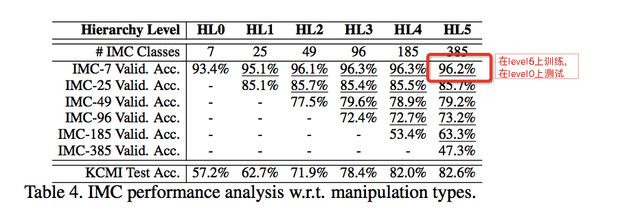
从表中看出,47.3%的准确率在385类的分类上,这个准确率有点略地,所以作者提出在这个baseline上面改进:(1)使得网络更宽(2)加深网络。最后获得的最好的准确率是51.8%。。。这个真的尽力了,感觉比较难。
以上主要是获得一个可以很好的表达图像被篡改了的特征的网络。
LADN(Local Anomaly Detection Network)篡改检测定位网络。
包含三个步骤:(1)调整网络。对上一步得到的IMC分类网络进行调整,使其适用于异常检测网络。(2)基于人类思维的异常特征提取。(3)决策,基于以上信息判断一个像素是否是篡改的。其中(2)是比较关键的。
异常特征提取
作者提出了一个疑问,看下面的图像:

看到篡改图像第一眼人是怎么分辨的呢?一种可能的过程是这样的:
- (1)找这幅图像主要的特征
- (2)和主特征不一样的就可能是异常特征。
所以作者在这个部分解决了两个问题: - (1)主特征是什么?怎么计算它?what is a dominant feature, and how to compute it?
- (2)如何衡量主特征和局部特征的差异。
先从一个简单的问题来看,主特征的一个简单选择如式(1)所示:

其中F是图像原始的像素矩阵,其实就是算图像的均值来作为图像的主特征。相似的,局部特征和主特征的差异就可以用式2来定义:
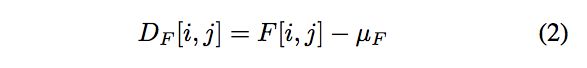
考虑到泛化性能,归一化一下应该会更好,如式3.
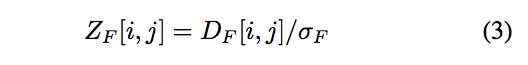
就是除以了标准差,标准差的定义见式4

在实际的实验过程中,论文使用了式(5)来代替标准差。
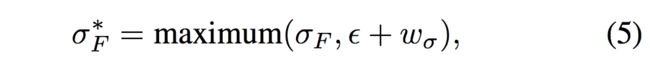
其中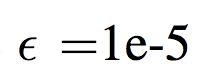 ,且w是一个需要学习的非负权重向量。
,且w是一个需要学习的非负权重向量。
最后一步,式(3)代表的特征表示了每个局部特征与主特征的差异,但是当一副图像中有两个以上区域被篡改的话,这个就不会特别准了。所以作者提出主特征的计算不在全局进行,而是在一个足够大的区域内进行,比如一个n*n的窗口。但是这个n的取值又很难去搞定,所以最后作者提出可以计算一系列的n值对应的Z-Score,组成一个score向量:

最后的一个亮点,作者为了模拟人眼看一副图像的由远及近的过程,将不同的窗口计算出来的score以窗口大小为第一个维度串起来,使用ConvLSTM2D层去分析每一个窗口对应的Z-score,换句话说,如果不确定的话,就会研究一个细粒度的zscore,因此概念上遵循从远到进的分析。
实验结果
准确性结果
在DNN-based manipulation,以及photoshop-battle dataset上进行了测试。计算图像级别的AUC,每张图像被篡改的概率就简单的认为是所有像素篡改概率的一个平均,并且选择是在前面的IMC网络上finetune还是随机初始化,得到结果如下表:

鲁棒性测试
对图像进行了各种可能的攻击:

可以看出,对于不同标准差的噪声攻击基本免疫,但对篡改区域边缘进行高斯模糊核过大就不行了。JPEG压缩还是比较难克服的。缩放的话基本GG(95%的缩放都只能到0.65的F1了)。
和其他方法的对比:
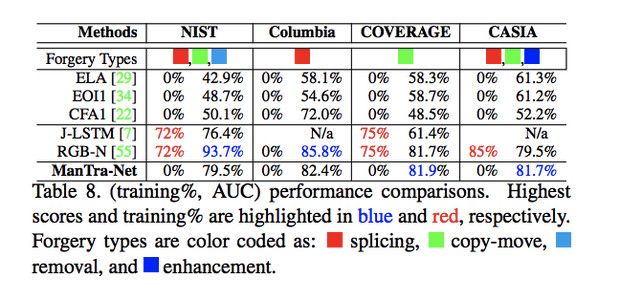
可以看出,本文的方法虽然没用这几个数据集做过训练(其他几个方法都或多或少用过),但是效果都还可以,本方法的泛化性能还是比较优秀的。
GitHub地址
详细测试版github地址: https://github.com/zhangqizky/ManTra_Net_Test_Demo
欢迎star~~
#总结
CVPR2019的论文,看得出来做了很多工作,但是篡改检测这个问题太难了,毕竟弱特征。还需要继续努力!在本文的基础上可以想到的改进就是继续扩展385类的分类,是第一阶段IMC分类网络能学习到更丰富的篡改特征。另一个方面就是改进后面的异常区域定位网络。这个除了可以尝试将网络加深加宽等,暂时没有什么特别好的idea。