Spark jobServer搭建+提交作业执行
安装scala
根据spark版本,在官网下载对应的unix版tar文件
配置环境变量
export PATH="$PATH:/usr/scala-2.10.6/bin"立即生效命令
source /etc/profile部署sbt
配置环境变量
export PATH="$PATH:/usr/sbt/"建立启动sbt的脚本文件
在sbt目录下,创建sbt文件
#!/bin/bash
SBT_OPTS="-Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M"
java $SBT_OPTS -jar /usr/sbt/bin/sbt-launch.jar "$@"查看sbt版本,第一次启动会自动下载文件
sbt sbt-version搭建jobServer
在github上下载对应spark版本的jobServer源码
在config目录下,重命名template(模板)文件,local.conf 和 local.sh
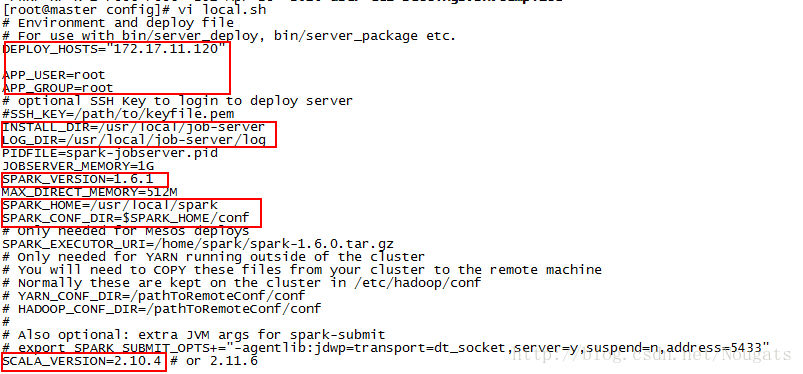
修改local.sh中的配置
(INSTALL_DIR: jobServer安装路径)
bin目录下执行
./server_package.sh local编译需要较长时间,编译成功后,在生成的job-server目录下启动
./server_start.sh在8090端口查看
打包wordcount并提交执行
在源码目录下,打包job-server-tests
sbt job-server-tests/package上传jar包,作为一个app,名为test
curl --data-binary @/usr/spark-jobserver-0.6.2/job-server-tests/target/scala-2.10/job-server-tests_2.10-0.6.2.jar master:8090/jars/test临时context方式(作业执行完成后删除context)
异步方式提交任务
jobserver会创建自己的SparkContext,会返回一个jobID供随后的查询
# curl -d "input.string = a b c a b see" 'localhost:8090/jobs?appName=test&classPath=spark.jobserver.WordCountExample'
{
"status": "STARTED",
"result": {
"jobId": "2e943174-63e3-41f2-bf4e-e56ff85169a9",
"context": "6d262fce-spark.jobserver.WordCountExample"
}
}通过jobid查询结果
# curl master:8090/jobs/2e943174-63e3-41f2-bf4e-e56ff85169a9
{
"duration": "0.278 secs",
"classPath": "spark.jobserver.WordCountExample",
"startTime": "2017-07-19T01:05:12.863-04:00",
"context": "6d262fce-spark.jobserver.WordCountExample",
"result": {
"a": 2,
"b": 2,
"see": 1,
"c": 1
},
"status": "FINISHED",
"jobId": "2e943174-63e3-41f2-bf4e-e56ff85169a9"
}同步方式提交任务(添加sync参数,值为true)
curl -d "input.string = a b c a b see" 'master:8090/jobs?appName=test&classPath=spark.jobserver.WordCountExample&sync=true'{
"result": {
"a": 2,
"b": 2,
"see": 1,
"c": 1
}
}常驻context方式
创建一个常驻context,集群为其分配资源,一直处于运行状态(jobserver重启会终止context,释放资源)
curl -d "" 'master:8090/contexts/test-context?num-cpu-cores=4&memory-per-node=512m'在context中执行任务(同步)
curl -d "input.string = a b c a b see" "localhost:8090/jobs?appName=test&classPath=spark.jobserver.WordCountExample&context=test-context&sync=true"