Spark Core(十三)Job触发流程原理与源码、Stage划分与提交原理分析
Job触发流程原理与源码原理Spark在执行我们编写的代码的时候,当遇到Action的时候,就会触发一次Job,因为所有的Action方法在链式调用runJob方法的时候,最后一个runJob方法中总DAGSchedule的runJob方法,而DAGSchedule是初始化SparkContext的时候事先创建好的。- 以
foreach方法来阐述Job的触发流程




DAGScheduler原理与源码分析DAGScheduler是一个高级调度,面向阶段(Stage)调度,它主要负责Stage的划分,生成DAG图,以及怎么生成任务集。首先DAGScheduler会将Job划分成多个Stage,然后将这些Stage封装成TaskSet,然后提交给TaskScheduler,然后TaskSchedule将这些封装成LaunchTask发送给对应的Executor去执行Stage划分的原理就是由最后一个RDD向前推倒,如果是窄依赖,那么当前的RDD与它的父RDD都归属同一个Stage,如果为宽依赖,那么当前RDD所以依赖的父RDD就是一个新的Stage,这个新的Stage最开始的RDD就是当前RDD的父RDD。所以Stage的划分是以宽依赖为界限,遇到宽依赖就会创建新的Stage。


Stage划分源码SparkContext的runJob方法

DAGScheduler的runJob方法

DAGScheduler的submitJob方法

DAGSchedulerEventProcessLoop类的doOnReceive方法,该方法接受各种消息并进行处理

DAGSchedule类里的handleJobSubmitted方法


DAGSchedule类里的newResultStage方法,该方法作用是获取ResultStage所依赖的父Stage,封装Stage并加入到内存缓冲中,刷新Job里的Stage,返回Stage。

DAGSchedule类里的getParentStagesAndId方法,该方法作用就是获取ResultStage所依赖的父Stage,为ResultStage生成一个自增的Id,返回第一个StageId和父Stage集合

DAGSchedule类里的getParentStages方法,该方法的作用就是将Stage一级一级的编织好,并返回。原理就是利用Action操作之前的最后一个RDD为基础,遍历其所有依赖,遇到宽依赖就返回Stage并添加到父Stage中,Stage与Stage之间的依赖是直接依赖,遇到窄依赖就添加到栈中继续向前遍历,直到找出每个RDD之间的所有宽依赖为止。

DAGSchedule类里的getShuffleMapStage方法,该方法的作用就是生成当前宽依赖的Stage,并提前把当前宽依赖对应的RDD对应的所有宽依赖找出来,然后创建对应的Stage并加入到缓冲中,提高程序的运行效率。

DAGSchedule类里的getAncestorShuffleDependencies方法,该方法就是找出RDD所有的宽依赖,为上层函数创建Stage提供参数

DAGSchedule类里的newOrUsedShuffleStage方法,该方法的作用就是递归调用newShuffleMapStage,并判断该Stage是否已经被计算过了,如果计算过就将计算结果复制到新的Stage,如果没有就注册到mapOutputTracker为存储元数据占位置

Stage提交原理DAGSchedule类里的submitStage方法,该方法的作用就是一级一级的提交Stage,提交的顺序是父Stage先提交

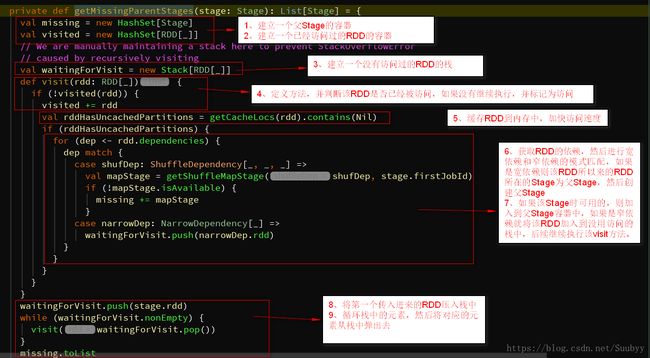
DAGSchedule类里的getMissingParentStages方法,该方法的作用就是根据Stage获取他的父Stage,其实也就是DAGScheduler的Stage划分,其实主要靠的是RDD的依赖关系来划分Stage,当RDD遇到也shuffle操作的时候就会生成一个新的Stage,即Stage就是以shuffle开始的,也就是说Stage中最开始的那个RDD的依赖是shuffleDepency,若某RDD为窄依赖,那么它和它依赖的父RDD是在同一个Stage中的,若为宽依赖,那么依赖的父RDD就会在另一个Stage中。
DAGSchedule类里的submitMissingTasks方法。/** Called when stage's parents are available and we can now do its task. */ private def submitMissingTasks(stage: Stage, jobId: Int) { logDebug("submitMissingTasks(" + stage + ")") // 清空等待状态的Partition的容器 stage.pendingPartitions.clear() //获取所有需要计算的分区id的集合 val partitionsToCompute: Seq[Int] = stage.findMissingPartitions() //修正累加器 if (stage.internalAccumulators.isEmpty || stage.numPartitions == partitionsToCompute.size) { stage.resetInternalAccumulators() } //获取执行这个Stage的时候使用与此Stage相关联的活跃的Job的调度池,作业组等一下参数 val properties = jobIdToActiveJob(jobId).properties //将该Stage加入到运行Stage的队列中 runningStages += stage //判断当前Stage是ShuffleMapStage还是ResultStage,并封装stage的一些信息,得到stage与分区数的映射关系,也就是一个Stage对应多少个分区需要计算,因为每个Stage包含多个Task,而Task都需要到Partition上去执行,所以叫计算出Stage对应多少个分区 stage match { case s: ShuffleMapStage => outputCommitCoordinator.stageStart(stage = s.id, maxPartitionId = s.numPartitions - 1) case s: ResultStage => outputCommitCoordinator.stageStart( stage = s.id, maxPartitionId = s.rdd.partitions.length - 1) } //计算Task的最佳位置,得到每个分区对应的位置,也就是分区的数据位于集群的哪台机器上 val taskIdToLocations: Map[Int, Seq[TaskLocation]] = try { stage match { case s: ShuffleMapStage => //getPreferredLocs(stage.rdd, id)这个方法就是计算出Task的最佳位置算法, //该算法的原理其实就是从Stage的最后一个RDD开始,首先从缓存中找出每个RDD的 //Partition以及父RDD的Partition是否被缓存了, //如果缓存中没有,那么寻找当前RDD的Partition以及RDD的父RDD的Partition是否checkpoint。 //如果都没有那么就由TaskScheduler决定去哪个节点上执行 //id:为Partition的索引id。 //getPreferredLocs(stage.rdd, id)):获取与当前RDD相关联的Partition的位置信息 partitionsToCompute.map { id => (id, getPreferredLocs(stage.rdd, id))}.toMap case s: ResultStage => val job = s.activeJob.get //getPreferredLocs(stage.rdd, id)这个方法就是计算出Task的最佳位置算法 partitionsToCompute.map { id => val p = s.partitions(id) (id, getPreferredLocs(stage.rdd, p)) }.toMap } } catch { case NonFatal(e) => stage.makeNewStageAttempt(partitionsToCompute.size) listenerBus.post(SparkListenerStageSubmitted(stage.latestInfo, properties)) abortStage(stage, s"Task creation failed: $e\n${e.getStackTraceString}", Some(e)) runningStages -= stage return } //把上边的stage需要计算的分区与每个分区对应的物理位置进行重新封装,放在StageInfo中 stage.makeNewStageAttempt(partitionsToCompute.size, taskIdToLocations.values.toSeq) listenerBus.post(SparkListenerStageSubmitted(stage.latestInfo, properties)) // 序列化StageInfo,以便在Driver与Worker机器上传输 var taskBinary: Broadcast[Array[Byte]] = null try { val taskBinaryBytes: Array[Byte] = stage match { case stage: ShuffleMapStage => closureSerializer.serialize((stage.rdd, stage.shuffleDep): AnyRef).array() case stage: ResultStage => closureSerializer.serialize((stage.rdd, stage.func): AnyRef).array() } taskBinary = sc.broadcast(taskBinaryBytes) } catch { // In the case of a failure during serialization, abort the stage. case e: NotSerializableException => abortStage(stage, "Task not serializable: " + e.toString, Some(e)) runningStages -= stage // Abort execution return case NonFatal(e) => abortStage(stage, s"Task serialization failed: $e\n${e.getStackTraceString}", Some(e)) runningStages -= stage return } //为Stage创建指定数量的Task。首先封装StageSet,ShuffleMapStage对应的是ShuffleMapTask,ResultStage对应的是ResultTask val tasks: Seq[Task[_]] = try { stage match { case stage: ShuffleMapStage => //为每一个Partition创建一个Task,给每个Task计算最佳位置 partitionsToCompute.map { id => //为每个Task计算最佳位置 val locs = taskIdToLocations(id)//Task的最佳位置 val part = stage.rdd.partitions(id)//RDD对应的Partition //如果是ShuffleMapStage就为当前Partition创建ShuffleMapTask new ShuffleMapTask(stage.id, stage.latestInfo.attemptId, taskBinary, part, locs, stage.internalAccumulators) } case stage: ResultStage => val job = stage.activeJob.get //为每一个Partition创建Task partitionsToCompute.map { id => //p:Partition的索引,表示从哪个Partition获取数据 val p: Int = stage.partitions(id) //RDD对应的Partition val part = stage.rdd.partitions(p) //为每个Task计算最佳位置 val locs = taskIdToLocations(id) //如果是ResultStage,就会为当前Partition创建ResultStage //taskBinary:是RDD与ShuffleDependency的广播变量序列化以后的结果, //该结果被发送到Executor以后在进行反序列化,然后在执行Task。 new ResultTask(stage.id, stage.latestInfo.attemptId, taskBinary, part, locs, id, stage.internalAccumulators) } } } catch { case NonFatal(e) => abortStage(stage, s"Task creation failed: $e\n${e.getStackTraceString}", Some(e)) runningStages -= stage return } //提价Task给TaskScheduler if (tasks.size > 0) { logInfo("Submitting " + tasks.size + " missing tasks from " + stage + " (" + stage.rdd + ")") stage.pendingPartitions ++= tasks.map(_.partitionId) logDebug("New pending partitions: " + stage.pendingPartitions) //一个Stage对应多个Task,将一个Stage里的Task创建TaskSet,然后交由TaskScheduler提交到Executor上去执行 taskScheduler.submitTasks(new TaskSet( tasks.toArray, stage.id, stage.latestInfo.attemptId, jobId, properties)) stage.latestInfo.submissionTime = Some(clock.getTimeMillis()) } else { // Because we posted SparkListenerStageSubmitted earlier, we should mark // the stage as completed here in case there are no tasks to run markStageAsFinished(stage, None) val debugString = stage match { case stage: ShuffleMapStage => s"Stage ${stage} is actually done; " + s"(available: ${stage.isAvailable}," + s"available outputs: ${stage.numAvailableOutputs}," + s"partitions: ${stage.numPartitions})" case stage : ResultStage => s"Stage ${stage} is actually done; (partitions: ${stage.numPartitions})" } logDebug(debugString) } }列表内容