spring ioc 容器的加载流程
1.目标:熟练使用spring,并分析其源码,了解其中的思想。这篇主要介绍spring ioc 容器的加载
2.前提条件:会使用debug
3.源码分析方法:Intellj idea debug 模式下源码追溯
通过ClassPathXmlApplicationContext 进行xml 件的读取,从每个堆栈中读取程序的运行信息
4.注意:由于Spring的类继承体系比较复杂,不能全部贴图,所以只将分析源码之后发现的最主要的类继承结构类图贴在下方。
5.关于Spring Ioc
Demo:我们从demo入手一步步进行代码追溯。
Spring Ioc Demo
1.定义数据访问接口IUserDao.java
public interface IUserDao {
public void InsertUser(String username,String password);
}
2.定义IUserDao.java实现类IUserDaoImpl.java
public class UserDaoImpl implements IUserDao {
@Override
public void InsertUser(String username, String password) {
System.out.println("----UserDaoImpl --addUser----");
}
}
3.定义业务逻辑接口UserService.java
public interface UserService {
public void addUser(String username,String password);
}
4.定义UserService.java实现类UserServiceImpl.java
public class UserServiceImpl implements UserService {
private IUserDao userDao; //set方法
public void setUserDao(IUserDao userDao) {
this.userDao = userDao;
}
@Override
public void addUser(String username,String password) {
userDao.InsertUser(username,password);
}
}
bean.xml配置文件
ApplicationContext 继承结构
1.顶层接口:ApplicationContext
2.ClassPathXmlApplicationContext实现类继承AbstractXmlApplication 抽象类
3.AbstractXmlApplication 继承AbstractRefreshableConfigApplicationContext
4.AbstractRefreshableConfigApplicationContext抽象类继承AbstractRefreshableApplicationContext
5.AbstractRefreshableApplicationContext 继承 AbstractApplicationContext
6.AbstractApplicationContext 实现ConfigurableApplicationContext 接口
7.ConfigurableApplicationContext 接口继承
ApplicationContext接口
总体来说继承实现结构较深,内部使用了大量适配器模式。
以ClassPathXmlApplicationContext为例,继承类图如下图所示: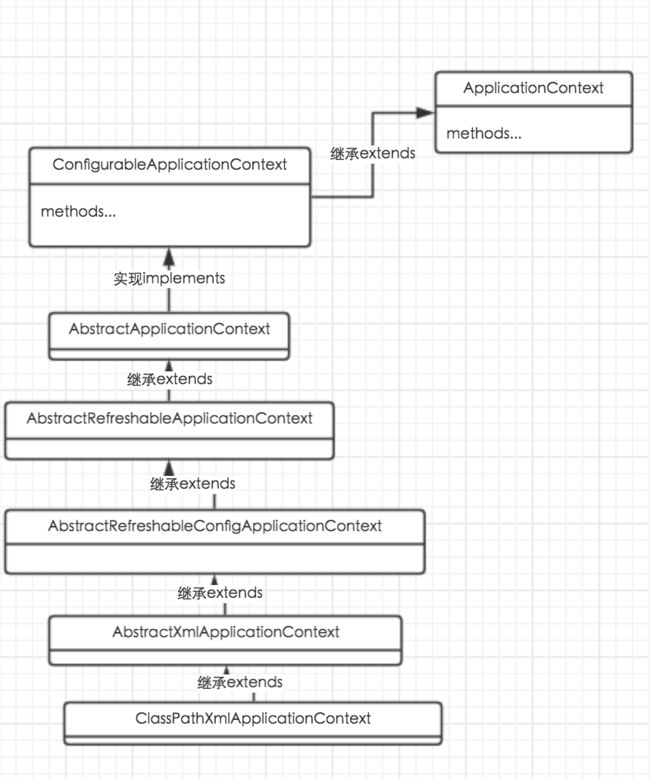
Spring Ioc容器加载过程源码详解
在开始之前,先介绍一个整体的概念。即spring ioc容器的加载,大体上经过以下几个过程:
资源文件定位、解析、注册、实例化
1.资源文件定位
其中资源文件定位,一般是在ApplicationContext的实现类里完成的,因为ApplicationContext接口继承ResourcePatternResolver 接口,ResourcePatternResolver接口继承ResourceLoader接口,ResourceLoader其中的getResource()方法,可以将外部的资源,读取为Resource类。
2.解析DefaultBeanDefinitionDocumentReader,
解析主要是在BeanDefinitionReader中完成的,最常用的实现类是XmlBeanDefinitionReader,其中的loadBeanDefinitions()方法,负责读取Resource,并完成后续的步骤。ApplicationContext完成资源文件定位之后,是将解析工作委托给XmlBeanDefinitionReader来完成的
解析这里涉及到很多步骤,最常见的情况,资源文件来自一个XML配置文件。首先是BeanDefinitionReader,将XML文件读取成w3c的Document文档。
DefaultBeanDefinitionDocumentReader对Document进行进一步解析。然后DefaultBeanDefinitionDocumentReader又委托给BeanDefinitionParserDelegate进行解析。如果是标准的xml namespace元素,会在Delegate内部完成解析,如果是非标准的xml namespace元素,则会委托合适的NamespaceHandler进行解析最终解析的结果都封装为BeanDefinitionHolder,至此解析就算完成。
后续会进行细致讲解。
3.注册
然后bean的注册是在BeanFactory里完成的,BeanFactory接口最常见的一个实现类是DefaultListableBeanFactory,它实现了BeanDefinitionRegistry接口,所以其中的registerBeanDefinition()方法,可以对BeanDefinition进行注册这里附带一提,最常见的XmlWebApplicationContext不是自己持有BeanDefinition的,它继承自AbstractRefreshableApplicationContext,其持有一个DefaultListableBeanFactory的字段,就是用它来保存BeanDefinition
所谓的注册,其实就是将BeanDefinition的name和实例,保存到一个Map中。刚才说到,最常用的实现DefaultListableBeanFactory,其中的字段就是beanDefinitionMap,是一个ConcurrentHashMap。
代码如下:
>1.DefaultListableBeanFactory继承实现关系
public class DefaultListableBeanFactory
extends
AbstractAutowireCapableBeanFactory
implements
ConfigurableListableBeanFactory,
BeanDefinitionRegistry,
Serializable {
// DefaultListableBeanFactory的实例中最终保存了所有注册的bean beanDefinitionMap
/** Map of bean definition objects, keyed by bean name */
private final Map beanDefinitionMap
= new ConcurrentHashMap(64);
//实现BeanDefinitionRegistry中定义的registerBeanDefinition()抽象方法
public void registerBeanDefinition(String beanName, BeanDefinition beanDefinition) throws BeanDefinitionStoreException {
}
>2.BeanDefinitionRegistry接口
public interface BeanDefinitionRegistry extends AliasRegistry {
//定义注册BeanDefinition实例的抽象方法
void registerBeanDefinition(String beanName, BeanDefinition beanDefinition) throws BeanDefinitionStoreException;
4.实例化
注册也完成之后,在BeanFactory的getBean()方法之中,会完成初始化,也就是依赖注入的过程
大体上的流程就是这样。
refresh()方法
1.目标:
这篇记录debug 追溯源码的过程,大概分三个篇幅,这是第一篇,现整体了解一下运行流程,定位资源加载,资源解析,bean 注册发生的位置。
2.记录结构:
1.调试栈截图
2.整体流程
3.bean.xml的处理
每段代码下面有相应的讲解
调试栈截图
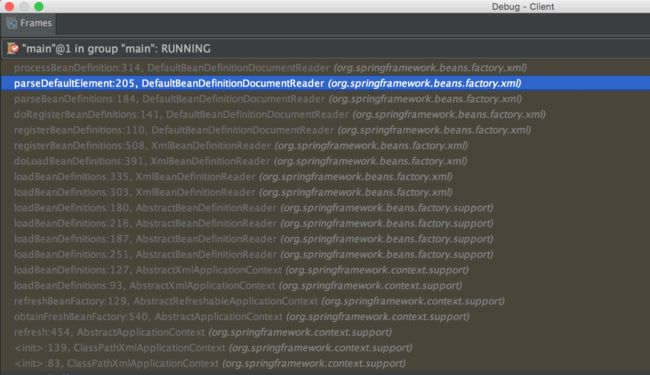
每个栈帧中方法的行号都有标明,按照行号追溯源码,然后配合教程能够快速学习。
整体流程
ioc容器实例化代码
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("bean.xml");
进入代码中一步步追溯,发现重要方法:refresh();
如下所示:
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
// Prepare this context for refreshing.
prepareRefresh();
//beanFactory实例化方法 单步调试入口
// Tell the subclass to refresh the internal bean factory.
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// Prepare the bean factory for use in this context.
prepareBeanFactory(beanFactory);
try {
// Allows post-processing of the bean factory in context subclasses.
postProcessBeanFactory(beanFactory);
// Invoke factory processors registered as beans in the context.
invokeBeanFactoryPostProcessors(beanFactory);
// Register bean processors that intercept bean creation.
registerBeanPostProcessors(beanFactory);
// Initialize message source for this context.
initMessageSource();
// Initialize event multicaster for this context.
initApplicationEventMulticaster();
// Initialize other special beans in specific context subclasses.
onRefresh();
// Check for listener beans and register them.
registerListeners();
// Instantiate all remaining (non-lazy-init) singletons.
finishBeanFactoryInitialization(beanFactory);
// Last step: publish corresponding event.
finishRefresh();
}
catch (BeansException ex) {
// Destroy already created singletons to avoid dangling resources.
destroyBeans();
// Reset 'active' flag.
cancelRefresh(ex);
// Propagate exception to caller.
throw ex;
}
}
}
首先这个方法是同步的,以避免重复刷新。然后刷新的每个步骤,都放在单独的方法里,比较清晰,可以按顺序一个个看
首先是prepareRefresh()方法
protected void prepareRefresh() {
this.startupDate = System.currentTimeMillis();
synchronized (this.activeMonitor) {
this.active = true;
}
if (logger.isInfoEnabled()) {
logger.info("Refreshing " + this);
}
// Initialize any placeholder property sources in the context environment
initPropertySources();
// Validate that all properties marked as required are resolvable
// see ConfigurablePropertyResolver#setRequiredProperties
this.environment.validateRequiredProperties();
}
这个方法里做的事情不多,记录了开始时间,输出日志,另外initPropertySources()方法和validateRequiredProperties()方法一般都没有做什么事。
然后是核心的obtainFreshBeanFactory()方法,这个方法是初始化BeanFactory,是整个refresh()方法的核心,其中完成了配置文件的加载、解析、注册,后面会专门详细说 。
这里要说明一下,ApplicationContext实现了BeanFactory接口,并实现了ResourceLoader、MessageSource等接口,可以认为是增强的BeanFactory。但是ApplicationContext并不自己重复实现BeanFactory定义的方法,而是委托给DefaultListableBeanFactory来实现。这种设计思路也是值得学习的。
后面的 prepareBeanFactory()、postProcessBeanFactory()、invokeBeanFactoryPostProcessors()、registerBeanPostProcessors()、initMessageSource()、initApplicationEventMulticaster()、onRefresh()、registerListeners()、finishBeanFactoryInitialization()、finishRefresh()等方法,是添加一些后处理器、广播、拦截器等,就不一个个细说了
其中的关键方法是finishBeanFactoryInitialization(),在这个方法中,会对刚才注册的Bean(不延迟加载的),进行实例化,所以也是一个核心方法。
bean.xml的处理
从整体上介绍完了流程,接下来就重点看obtainFreshBeanFactory()方法,上文说到,在这个方法里,完成了配置文件的加载、解析、注册
protected ConfigurableListableBeanFactory obtainFreshBeanFactory() {
refreshBeanFactory();
ConfigurableListableBeanFactory beanFactory = getBeanFactory();
if (logger.isDebugEnabled()) {
logger.debug("Bean factory for " + getDisplayName() + ": " + beanFactory);
}
return beanFactory;
}
这个方法做了2件事,首先通过refreshBeanFactory()方法,创建了DefaultListableBeanFactory的实例,并进行初始化。
protected final void refreshBeanFactory() throws BeansException {
if (hasBeanFactory()) {
destroyBeans();
closeBeanFactory();
}
try {
DefaultListableBeanFactory beanFactory = createBeanFactory();
beanFactory.setSerializationId(getId());
customizeBeanFactory(beanFactory);
loadBeanDefinitions(beanFactory);
synchronized (this.beanFactoryMonitor) {
this.beanFactory = beanFactory;
}
}
catch (IOException ex) {
throw new ApplicationContextException("I/O error parsing bean definition source for " + getDisplayName(), ex);
}
}
首先如果已经有BeanFactory实例,就先清空。然后通过createBeanFactory()方法,创建一个DefaultListableBeanFactory的实例
protected DefaultListableBeanFactory createBeanFactory() {
return new DefaultListableBeanFactory(getInternalParentBeanFactory());
}
接下来设置ID唯一标识
beanFactory.setSerializationId(getId());
然后允许用户进行一些自定义的配置
protected void customizeBeanFactory(DefaultListableBeanFactory beanFactory) {
if (this.allowBeanDefinitionOverriding != null) {
beanFactory.setAllowBeanDefinitionOverriding(this.allowBeanDefinitionOverriding);
}
if (this.allowCircularReferences != null) {
beanFactory.setAllowCircularReferences(this.allowCircularReferences);
}
beanFactory.setAutowireCandidateResolver(new QualifierAnnotationAutowireCandidateResolver());
}
最后,就是核心的loadBeanDefinitions()方法
protected void loadBeanDefinitions(DefaultListableBeanFactory beanFactory) throws BeansException, IOException {
// Create a new XmlBeanDefinitionReader for the given BeanFactory.
XmlBeanDefinitionReader beanDefinitionReader = new XmlBeanDefinitionReader(beanFactory);
// Configure the bean definition reader with this context's
// resource loading environment.
beanDefinitionReader.setEnvironment(this.getEnvironment());
beanDefinitionReader.setResourceLoader(this);
beanDefinitionReader.setEntityResolver(new ResourceEntityResolver(this));
// Allow a subclass to provide custom initialization of the reader,
// then proceed with actually loading the bean definitions.
initBeanDefinitionReader(beanDefinitionReader);
loadBeanDefinitions(beanDefinitionReader);
}
这里首先会创建一个XmlBeanDefinitionReader的实例,然后进行初始化。这个XmlBeanDefinitionReader中其实传递的BeanDefinitionRegistry类型的实例,为什么可以传递一个beanFactory呢,因为DefaultListableBeanFactory实现了BeanDefinitionRegistry接口,这里是多态的使用。
protected void loadBeanDefinitions(DefaultListableBeanFactory beanFactory) throws BeansException, IOException {
// Create a new XmlBeanDefinitionReader for the given BeanFactory.
XmlBeanDefinitionReader beanDefinitionReader = new XmlBeanDefinitionReader(beanFactory);
// Configure the bean definition reader with this context's
// resource loading environment.
beanDefinitionReader.setEnvironment(this.getEnvironment());
beanDefinitionReader.setResourceLoader(this);
beanDefinitionReader.setEntityResolver(new ResourceEntityResolver(this));
// Allow a subclass to provide custom initialization of the reader,
// then proceed with actually loading the bean definitions.
initBeanDefinitionReader(beanDefinitionReader);
}
这里要说明一下,ApplicationContext并不自己负责配置文件的加载、解析、注册,而是将这些工作委托给XmlBeanDefinitionReader来做。
loadBeanDefinitions(beanDefinitionReader);
这行代码,就是Bean定义读取实际发生的地方。这里的工作,主要是XmlBeanDefinitionReader来完成的,下一篇博客会详细介绍这个过程。
loadBeanDefinitions
loadBeanDefinitions: 源码阅读
入口是loadBeanDefinitions方法
protected void loadBeanDefinitions(XmlBeanDefinitionReader reader)
throws IOException {
String[] configLocations = getConfigLocations();
if (configLocations != null) {
for (String configLocation : configLocations) {
reader.loadBeanDefinitions(configLocation);
}
}
}
这是解析过程最外围的代码,首先要获取到配置文件的路径,这在之前已经完成了。
然后将每个配置文件的路径,作为参数传给BeanDefinitionReader的loadBeanDefinitions方法里
public int loadBeanDefinitions(String location) throws BeanDefinitionStoreException {
return loadBeanDefinitions(location, null);
}
这个方法又调用了重载方法
public int loadBeanDefinitions(String location, Set actualResources)
throws BeanDefinitionStoreException {
ResourceLoader resourceLoader = getResourceLoader();
if (resourceLoader == null) {
throw new BeanDefinitionStoreException(
"Cannot import bean definitions from location [" + location + "]: no ResourceLoader available");
}
if (resourceLoader instanceof ResourcePatternResolver) {
// Resource pattern matching available.
try {
Resource[] resources = ((ResourcePatternResolver) resourceLoader).getResources(location);
int loadCount = loadBeanDefinitions(resources);
if (actualResources != null) {
for (Resource resource : resources) {
actualResources.add(resource);
}
}
if (logger.isDebugEnabled()) {
logger.debug("Loaded " + loadCount + " bean definitions from location pattern [" + location + "]");
}
return loadCount;
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(
"Could not resolve bean definition resource pattern [" + location + "]", ex);
}
}
else {
// Can only load single resources by absolute URL.
Resource resource = resourceLoader.getResource(location);
int loadCount = loadBeanDefinitions(resource);
if (actualResources != null) {
actualResources.add(resource);
}
if (logger.isDebugEnabled()) {
logger.debug("Loaded " + loadCount + " bean definitions from location [" + location + "]");
}
return loadCount;
}
}
首先getResourceLoader()的实现的前提条件是因为XmlBeanDefinitionReader在实例化的时候已经确定了创建了实例ResourceLoader实例, 代码位于 AbstractBeanDefinitionReader
protected AbstractBeanDefinitionReader(BeanDefinitionRegistry registry) {
Assert.notNull(registry, "BeanDefinitionRegistry must not be null");
this.registry = registry;
// Determine ResourceLoader to use.
if (this.registry instanceof ResourceLoader) {
this.resourceLoader = (ResourceLoader) this.registry;
} else {
this.resourceLoader = new PathMatchingResourcePatternResolver();
}
// Inherit Environment if possible
if (this.registry instanceof EnvironmentCapable) {
this.environment = ((EnvironmentCapable)this.registry).getEnvironment();
} else {
this.environment = new StandardEnvironment();
}
}
这个方法比较长,BeanDefinitionReader不能直接加载配置文件,需要把配置文件封装成Resource,然后才能调用重载方法loadBeanDefinitions()。所以这个方法其实就是2段,第一部分是委托ResourceLoader将配置文件封装成Resource,第二部分是调用loadBeanDefinitions(),对Resource进行解析
而这里的ResourceLoader,就是前面的XmlWebApplicationContext,因为ApplicationContext接口,是继承自ResourceLoader接口的
Resource也是一个接口体系,在web环境下,这里就是ServletContextResource
接下来进入重载方法loadBeanDefinitions()
public int loadBeanDefinitions(Resource... resources) throws BeanDefinitionStoreException {
Assert.notNull(resources, "Resource array must not be null");
int counter = 0;
for (Resource resource : resources) {
counter += loadBeanDefinitions(resource);
}
return counter;
}
这里就不用说了,就是把每一个Resource作为参数,继续调用重载方法。读spring源码,会发现重载方法特别多。
public int loadBeanDefinitions(Resource resource) throws
BeanDefinitionStoreException {
return loadBeanDefinitions(new EncodedResource(resource));
}
还是重载方法,不过这里对传进来的Resource又进行了一次封装,变成了编码后的Resource。
public int loadBeanDefinitions(EncodedResource encodedResource)
throws BeanDefinitionStoreException {
Assert.notNull(encodedResource, "EncodedResource must not be null");
if (logger.isInfoEnabled()) {
logger.info("Loading XML bean definitions from " + encodedResource.getResource());
}
Set currentResources = this.resourcesCurrentlyBeingLoaded.get();
if (currentResources == null) {
currentResources = new HashSet(4);
this.resourcesCurrentlyBeingLoaded.set(currentResources);
}
if (!currentResources.add(encodedResource)) {
throw new BeanDefinitionStoreException(
"Detected cyclic loading of " + encodedResource + " - check your import definitions!");
}
try {
InputStream inputStream = encodedResource.getResource().getInputStream();
try {
InputSource inputSource = new InputSource(inputStream);
if (encodedResource.getEncoding() != null) {
inputSource.setEncoding(encodedResource.getEncoding());
}
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
}
finally {
inputStream.close();
}
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(
"IOException parsing XML document from " + encodedResource.getResource(), ex);
}
finally {
currentResources.remove(encodedResource);
if (currentResources.isEmpty()) {
this.resourcesCurrentlyBeingLoaded.remove();
}
}
}
这个就是loadBeanDefinitions()的最后一个重载方法,比较长,可以拆看来看。
Assert.notNull(encodedResource, "EncodedResource must not be null");
if (logger.isInfoEnabled()) {
logger.info("Loading XML bean definitions from " + encodedResource.getResource());
}
Set currentResources = this.resourcesCurrentlyBeingLoaded.get();
if (currentResources == null) {
currentResources = new HashSet(4);
this.resourcesCurrentlyBeingLoaded.set(currentResources);
}
if (!currentResources.add(encodedResource)) {
throw new BeanDefinitionStoreException(
"Detected cyclic loading of " + encodedResource + " - check your import definitions!");
}
这第一部分,是处理线程相关的工作,把当前正在解析的Resource,设置为当前Resource。
try {
InputStream inputStream = encodedResource.getResource().getInputStream();
try {
InputSource inputSource = new InputSource(inputStream);
if (encodedResource.getEncoding() != null) {
inputSource.setEncoding(encodedResource.getEncoding());
}
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
}
finally {
inputStream.close();
}
}
这里是第二部分,是核心,首先把Resource还原为InputStream,然后调用实际解析的方法doLoadBeanDefinitions()。可以看到,这种命名方式是很值得学习的,一种业务方法,比如parse(),可能需要做一些外围的工作,然后实际解析的方法,可以命名为doParse()。这种doXXX()的命名方法,在很多开源框架中都有应用,比如logback等。
接下来就看一下这个doLoadBeanDefinitions()方法
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)
throws BeanDefinitionStoreException {
try {
Document doc = doLoadDocument(inputSource, resource);return registerBeanDefinitions(doc, resource);
return registerBeanDefinitions(doc, resource);
}
catch (BeanDefinitionStoreException ex) {
throw ex;
}
catch (SAXParseException ex) {
throw new XmlBeanDefinitionStoreException(resource.getDescription(),
"Line " + ex.getLineNumber() + " in XML document from " + resource + " is invalid", ex);
}
catch (SAXException ex) {
throw new XmlBeanDefinitionStoreException(resource.getDescription(),
"XML document from " + resource + " is invalid", ex);
}
catch (ParserConfigurationException ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"Parser configuration exception parsing XML from " + resource, ex);
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"IOException parsing XML document from " + resource, ex);
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"Unexpected exception parsing XML document from " + resource, ex);
}
}
抛开异常处理:核心代码如下:
Document doc = doLoadDocument(inputSource, resource);
return registerBeanDefinitions(doc, resource);
doLoadDocument方法将InputStream读取成标准的Document对象,然后调用registerBeanDefinitions(),进行解析工作。
protected Document doLoadDocument(InputSource inputSource, Resource resource) throws Exception {
return this.documentLoader.loadDocument(inputSource,
getEntityResolver(), this.errorHandler,
getValidationModeForResource(resource),
isNamespaceAware());
}
接下来就看一下这个核心方法registerBeanDefinitions
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
//创建的其实是DefaultBeanDefinitionDocumentReader 的实例,利用反射创建的。
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
documentReader.setEnvironment(this.getEnvironment());
int countBefore = getRegistry().getBeanDefinitionCount();
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
return getRegistry().getBeanDefinitionCount() - countBefore;
}
这里注意两点 :
1.Document对象
首先这个Document对象,是W3C定义的标准XML对象,跟spring无关。其次这个registerBeanDefinitions方法,我觉得命名有点误导性。因为这个时候实际上解析还没有开始,怎么直接就注册了呢。比较好的命名,我觉得可以是parseAndRegisterBeanDefinitions()。
2.documentReader的创建时使用反射创建的,代码如下
protected BeanDefinitionDocumentReader
createBeanDefinitionDocumentReader() {
return BeanDefinitionDocumentReader.class.cast(BeanUtils.
instantiateClass(this.documentReaderClass));
}
instantiateClass方法中传入了一个Class类型的参数。追溯发现下述代码:
private Class documentReaderClass =
DefaultBeanDefinitionDocumentReader.class;
所以创建的documentReaderClass是DefaultBeanDefinitionDocumentReader类的实例。
接下来就进入BeanDefinitionDocumentReader 中定义的registerBeanDefinitions()方法看看
public void registerBeanDefinitions(Document doc, XmlReaderContext readerContext) {
this.readerContext = readerContext;
logger.debug("Loading bean definitions");
Element root = doc.getDocumentElement();
doRegisterBeanDefinitions(root);
}
处理完外围事务之后,进入doRegisterBeanDefinitions()方法,这种命名规范,上文已经介绍过了
protected void doRegisterBeanDefinitions(Element root) {
String profileSpec = root.getAttribute(PROFILE_ATTRIBUTE);
if (StringUtils.hasText(profileSpec)) {
Assert.state(this.environment != null, "environment property must not be null");
String[] specifiedProfiles = StringUtils.tokenizeToStringArray(profileSpec, BeanDefinitionParserDelegate.MULTI_VALUE_ATTRIBUTE_DELIMITERS);
if (!this.environment.acceptsProfiles(specifiedProfiles)) {
return;
}
}
// any nested elements will cause recursion in this method. In
// order to propagate and preserve default-* attributes correctly,
// keep track of the current (parent) delegate, which may be null. Create
// the new (child) delegate with a reference to the parent for fallback purposes,
// then ultimately reset this.delegate back to its original (parent) reference.
// this behavior emulates a stack of delegates without actually necessitating one.
BeanDefinitionParserDelegate parent = this.delegate;
this.delegate = createHelper(readerContext, root, parent);
preProcessXml(root);
parseBeanDefinitions(root, this.delegate);
postProcessXml(root);
this.delegate = parent;
}
这个方法也比较长,拆开来看
String profileSpec = root.getAttribute(PROFILE_ATTRIBUTE);
if (StringUtils.hasText(profileSpec)) {
Assert.state(this.environment != null, "environment property must not be null");
String[] specifiedProfiles = StringUtils.tokenizeToStringArray(profileSpec, BeanDefinitionParserDelegate.MULTI_VALUE_ATTRIBUTE_DELIMITERS);
if (!this.environment.acceptsProfiles(specifiedProfiles)) {
return;
}
}
如果配置文件中元素,配有profile属性,就会进入这一段,不过一般都是不会的
BeanDefinitionParserDelegate parent = this.delegate;
this.delegate = createHelper(readerContext, root, parent);
preProcessXml(root);
parseBeanDefinitions(root, this.delegate);
postProcessXml(root);
this.delegate = parent;
然后这里创建了BeanDefinitionParserDelegate对象,preProcessXml()和postProcessXml()都是空方法,核心就是parseBeanDefinitions()方法。这里又把BeanDefinition解析和注册的工作,委托给了BeanDefinitionParserDelegate对象,在parseBeanDefinitions()方法中完成
总的来说,解析工作的委托链是这样的:ClassPathXmlApplicationContext,XmlBeanDefinitionReader,DefaultBeanDefinitionDocumentReader,BeanDefinitionParserDelegate
ClassPathXmlApplicationContext作为最外围的组件,发起解析的请求
XmlBeanDefinitionReader将配置文件路径封装为Resource,读取出w3c定义的Document对象,然后委托给DefaultBeanDefinitionDocumentReader
DefaultBeanDefinitionDocumentReader就开始做实际的解析工作了,但是涉及到bean的具体解析,它还是会继续委托给BeanDefinitionParserDelegate来做。
接下来在parseBeanDefinitions()方法中发生了什么,以及BeanDefinitionParserDelegate类完成的工作,在下一篇博客中继续介绍。
loadBeanDefinitions
BeanDefinition的解析,已经走到了DefaultBeanDefinitionDocumentR
eader里,这时候配置文件已经被加载,并解析成w3c的Document对象。这篇博客就接着介绍,DefaultBeanDefinitionDocumentReader和BeanDefinitionParserDelegate类,是怎么协同完成bean的解析和注册的。
BeanDefinitionParserDelegate parent = this.delegate;
this.delegate = createHelper(readerContext, root, parent);
preProcessXml(root);
parseBeanDefinitions(root, this.delegate);
postProcessXml(root);
this.delegate = parent;
这段代码,创建了一个BeanDefinitionParserDelegate组件,然后就是preProcessXml()、parseBeanDefinitions()、postProcessXml()方法
其中preProcessXml()和postProcessXml()默认是空方法,接下来就看下parseBeanDefinitions()方法
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
if (delegate.isDefaultNamespace(root)) {
NodeList nl = root.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element) {
Element ele = (Element) node;
if (delegate.isDefaultNamespace(ele)) {
parseDefaultElement(ele, delegate);
}
else {
delegate.parseCustomElement(ele);
}
}
}
}
else {
delegate.parseCustomElement(root);
}
}
从这个方法开始,BeanDefinitionParserDelegate就开始发挥作用了,判断当前解析元素是否属于默认的命名空间,如果是的话,就调用parseDefaultElement()方法,否则调用delegate上parseCustomElement()方法
public boolean isDefaultNamespace(String namespaceUri) {
return (!StringUtils.hasLength(namespaceUri) || BEANS_NAMESPACE_URI.equals(namespaceUri));
}
public boolean isDefaultNamespace(Node node) {
return isDefaultNamespace(getNamespaceURI(node));
}
只有http://www.springframework.org/schema/beans,会被认为是默认的命名空间。也就是说,beans、bean这些元素,会认为属于默认的命名空间,而像task:scheduled这些,就认为不属于默认命名空间。
根节点beans的一个子节点bean,是属于默认命名空间的,所以会进入parseDefaultElement()方法
private void parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate) {
if (delegate.nodeNameEquals(ele, IMPORT_ELEMENT)) {
importBeanDefinitionResource(ele);
}
else if (delegate.nodeNameEquals(ele, ALIAS_ELEMENT)) {
processAliasRegistration(ele);
}
else if (delegate.nodeNameEquals(ele, BEAN_ELEMENT)) {
processBeanDefinition(ele, delegate);
}
else if (delegate.nodeNameEquals(ele, NESTED_BEANS_ELEMENT)) {
// recurse
doRegisterBeanDefinitions(ele);
}
}
这里可能会有4种情况,import、alias、bean、beans,分别有一个方法与之对应,这里解析的是bean元素,所以会进入processBeanDefinition()方法
protected void processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) {
BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele);
if (bdHolder != null) {
bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder);
try {
// Register the final decorated instance.
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());
}
catch (BeanDefinitionStoreException ex) {
getReaderContext().error("Failed to register bean definition with name '" +
bdHolder.getBeanName() + "'", ele, ex);
}
// Send registration event.
getReaderContext().fireComponentRegistered(new BeanComponentDefinition(bdHolder));
}
}
这里主要有3个步骤,先是委托delegate对bean进行解析,然后委托delegate对bean进行装饰,最后由一个工具类来完成BeanDefinition的注册
可以看出来,DefaultBeanDefinitionDocumentReader不负责任何具体的bean解析,它面向的是xml Document对象,根据其元素的命名空间和名称,起一个类似路由的作用(不过,命名空间的判断,也是委托给delegate来做的)。所以这个类的命名,是比较贴切的,突出了其面向Document的特性。具体的工作,是由BeanDefinitionParserDelegate来完成的
下面就看下parseBeanDefinitionElement()方法
public BeanDefinitionHolder parseBeanDefinitionElement(Element ele, BeanDefinition containingBean) {
String id = ele.getAttribute(ID_ATTRIBUTE);
String nameAttr = ele.getAttribute(NAME_ATTRIBUTE);
List aliases = new ArrayList();
if (StringUtils.hasLength(nameAttr)) {
String[] nameArr = StringUtils.tokenizeToStringArray(nameAttr, MULTI_VALUE_ATTRIBUTE_DELIMITERS);
aliases.addAll(Arrays.asList(nameArr));
}
String beanName = id;
if (!StringUtils.hasText(beanName) && !aliases.isEmpty()) {
beanName = aliases.remove(0);
if (logger.isDebugEnabled()) {
logger.debug("No XML 'id' specified - using '" + beanName +
"' as bean name and " + aliases + " as aliases");
}
}
if (containingBean == null) {
checkNameUniqueness(beanName, aliases, ele);
}
AbstractBeanDefinition beanDefinition = parseBeanDefinitionElement(ele, beanName, containingBean);
if (beanDefinition != null) {
if (!StringUtils.hasText(beanName)) {
try {
if (containingBean != null) {
beanName = BeanDefinitionReaderUtils.generateBeanName(
beanDefinition, this.readerContext.getRegistry(), true);
}
else {
beanName = this.readerContext.generateBeanName(beanDefinition);
// Register an alias for the plain bean class name, if still possible,
// if the generator returned the class name plus a suffix.
// This is expected for Spring 1.2/2.0 backwards compatibility.
String beanClassName = beanDefinition.getBeanClassName();
if (beanClassName != null &&
beanName.startsWith(beanClassName) && beanName.length() > beanClassName.length() && !this.readerContext.getRegistry().isBeanNameInUse(beanClassName)) {
aliases.add(beanClassName);
}
}
if (logger.isDebugEnabled()) {
logger.debug("Neither XML 'id' nor 'name' specified - " +
"using generated bean name [" + beanName + "]");
}
}
catch (Exception ex) {
error(ex.getMessage(), ele);
return null;
}
}
String[] aliasesArray = StringUtils.toStringArray(aliases);
return new BeanDefinitionHolder(beanDefinition, beanName, aliasesArray);
}
return null;
}
这个方法很长,可以分成三段来看
String id = ele.getAttribute(ID_ATTRIBUTE);
String nameAttr = ele.getAttribute(NAME_ATTRIBUTE);
List aliases = new ArrayList();
if (StringUtils.hasLength(nameAttr)) {
String[] nameArr = StringUtils.tokenizeToStringArray(nameAttr, MULTI_VALUE_ATTRIBUTE_DELIMITERS);
aliases.addAll(Arrays.asList(nameArr));
}
String beanName = id;
if (!StringUtils.hasText(beanName) && !aliases.isEmpty()) {
beanName = aliases.remove(0);
if (logger.isDebugEnabled()) {
logger.debug("No XML 'id' specified - using '" + beanName +
"' as bean name and " + aliases + " as aliases");
}
}
if (containingBean == null) {
checkNameUniqueness(beanName, aliases, ele);
}
这一段,主要是处理一些跟alias,id等标识相关的东西
AbstractBeanDefinition beanDefinition = parseBeanDefinitionElement(ele, beanName, containingBean);
这一行是核心,进行实际的解析
if (beanDefinition != null) {
if (!StringUtils.hasText(beanName)) {
try {
if (containingBean != null) {
beanName = BeanDefinitionReaderUtils.generateBeanName(
beanDefinition, this.readerContext.getRegistry(), true);
}
else {
beanName = this.readerContext.generateBeanName(beanDefinition);
// Register an alias for the plain bean class name, if still possible,
// if the generator returned the class name plus a suffix.
// This is expected for Spring 1.2/2.0 backwards compatibility.
String beanClassName = beanDefinition.getBeanClassName();
if (beanClassName != null &&
beanName.startsWith(beanClassName) && beanName.length() > beanClassName.length() &&
!this.readerContext.getRegistry().isBeanNameInUse(beanClassName)) {
aliases.add(beanClassName);
}
}
if (logger.isDebugEnabled()) {
logger.debug("Neither XML 'id' nor 'name' specified - " +
"using generated bean name [" + beanName + "]");
}
}
catch (Exception ex) {
error(ex.getMessage(), ele);
return null;
}
}
String[] aliasesArray = StringUtils.toStringArray(aliases);
return new BeanDefinitionHolder(beanDefinition, beanName, aliasesArray);
}
这段是后置处理,对beanName进行处理
前置处理和后置处理,不是核心,就不细看了,重点看下核心的那一行调用
public AbstractBeanDefinition parseBeanDefinitionElement(
Element ele, String beanName, BeanDefinition containingBean) {
this.parseState.push(new BeanEntry(beanName));
String className = null;
if (ele.hasAttribute(CLASS_ATTRIBUTE)) {
className = ele.getAttribute(CLASS_ATTRIBUTE).trim();
}
try {
String parent = null;
if (ele.hasAttribute(PARENT_ATTRIBUTE)) {
parent = ele.getAttribute(PARENT_ATTRIBUTE);
}
AbstractBeanDefinition bd = createBeanDefinition(className, parent);
parseBeanDefinitionAttributes(ele, beanName, containingBean, bd);
bd.setDescription(DomUtils.getChildElementValueByTagName(ele, DESCRIPTION_ELEMENT));
parseMetaElements(ele, bd);
parseLookupOverrideSubElements(ele, bd.getMethodOverrides());
parseReplacedMethodSubElements(ele, bd.getMethodOverrides());
parseConstructorArgElements(ele, bd);
parsePropertyElements(ele, bd);
parseQualifierElements(ele, bd);
bd.setResource(this.readerContext.getResource());
bd.setSource(extractSource(ele));
return bd;
}
catch (ClassNotFoundException ex) {
error("Bean class [" + className + "] not found", ele, ex);
}
catch (NoClassDefFoundError err) {
error("Class that bean class [" + className + "] depends on not found", ele, err);
}
catch (Throwable ex) {
error("Unexpected failure during bean definition parsing", ele, ex);
}
finally {
this.parseState.pop();
}
return null;
}
这个方法也挺长的,拆开看看
this.parseState.push(new BeanEntry(beanName));
String className = null;
if (ele.hasAttribute(CLASS_ATTRIBUTE)) {
className = ele.getAttribute(CLASS_ATTRIBUTE).trim();
}
这段是从配置中抽取出类名。接下来的长长一段,把异常处理先抛开,看看实际的业务
String parent = null;
if (ele.hasAttribute(PARENT_ATTRIBUTE)) {
parent = ele.getAttribute(PARENT_ATTRIBUTE);
}
AbstractBeanDefinition bd = createBeanDefinition(className, parent);
parseBeanDefinitionAttributes(ele, beanName, containingBean, bd);
bd.setDescription(DomUtils.getChildElementValueByTagName(ele, DESCRIPTION_ELEMENT));
parseMetaElements(ele, bd);
parseLookupOverrideSubElements(ele, bd.getMethodOverrides());
parseReplacedMethodSubElements(ele, bd.getMethodOverrides());
parseConstructorArgElements(ele, bd);
parsePropertyElements(ele, bd);
parseQualifierElements(ele, bd);
bd.setResource(this.readerContext.getResource());
bd.setSource(extractSource(ele));
return bd;
这里每个方法的命名,就说明了是要干什么,可以一个个跟进去看,本文就不细说了。总之,经过这里的解析,就得到了一个完整的BeanDefinitionHolder。只是说明一下,如果在配置文件里,没有对一些属性进行设置,比如autowire-candidate等,那么这个解析生成的BeanDefinition,都会得到一个默认值
然后,对这个Bean做一些必要的装饰
public BeanDefinitionHolder decorateBeanDefinitionIfRequired(
Element ele, BeanDefinitionHolder definitionHolder, BeanDefinition containingBd) {
BeanDefinitionHolder finalDefinition = definitionHolder;
// Decorate based on custom attributes first.
NamedNodeMap attributes = ele.getAttributes();
for (int i = 0; i < attributes.getLength(); i++) {
Node node = attributes.item(i);
finalDefinition = decorateIfRequired(node, finalDefinition, containingBd);
}
// Decorate based on custom nested elements.
NodeList children = ele.getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
Node node = children.item(i);
if (node.getNodeType() == Node.ELEMENT_NODE) {
finalDefinition = decorateIfRequired(node, finalDefinition, containingBd);
}
}
return finalDefinition;
}
持续单步调试,代码继续运行到DefaultBeanDefinitionDocumentReader中的processBeanDefinition中的registerBeanDefinition()
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder,
getReaderContext().getRegistry());
单步进入代码发现BeanDefinitionReaderUtils静态方法registerBeanDefinition()
public static void registerBeanDefinition(
BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)
throws BeanDefinitionStoreException {
// Register bean definition under primary name.
String beanName = definitionHolder.getBeanName();
// 其实调用的是DefaultListableBeanFactory中的registerBeanDefinition方法
registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition());
// Register aliases for bean name, if any.
String[] aliases = definitionHolder.getAliases();
if (aliases != null) {
for (String aliase : aliases) {
registry.registerAlias(beanName, aliase);
}
}
}
解释一下其实调用的是DefaultListableBeanFactory中的registerBeanDefinition方法这句话,因为DefaultListableBeanFactory实现BeanDefinitionRegistry接口,BeanDefinitionRegistry接口中定义了registerBeanDefinition()方法
看下DefaultListableBeanFactory中registerBeanDefinition()实例方法的具体实现:
public void registerBeanDefinition(String beanName, BeanDefinition beanDefinition)
throws BeanDefinitionStoreException {
Assert.hasText(beanName, "Bean name must not be empty");
Assert.notNull(beanDefinition, "BeanDefinition must not be null");
if (beanDefinition instanceof AbstractBeanDefinition) {
try {
((AbstractBeanDefinition) beanDefinition).validate();
}
catch (BeanDefinitionValidationException ex) {
throw new BeanDefinitionStoreException(beanDefinition.getResourceDescription(), beanName,
"Validation of bean definition failed", ex);
}
}
synchronized (this.beanDefinitionMap) {
Object oldBeanDefinition = this.beanDefinitionMap.get(beanName);
if (oldBeanDefinition != null) {
if (!this.allowBeanDefinitionOverriding) {
throw new BeanDefinitionStoreException(beanDefinition.getResourceDescription(), beanName,
"Cannot register bean definition [" + beanDefinition + "] for bean '" + beanName +
"': There is already [" + oldBeanDefinition + "] bound.");
}
else {
if (this.logger.isInfoEnabled()) {
this.logger.info("Overriding bean definition for bean '" + beanName +
"': replacing [" + oldBeanDefinition + "] with [" + beanDefinition + "]");
}
}
}
else {
this.beanDefinitionNames.add(beanName);
this.frozenBeanDefinitionNames = null;
}
this.beanDefinitionMap.put(beanName, beanDefinition);
resetBeanDefinition(beanName);
}
}
代码追溯之后发现这个方法里,最关键的是以下2行:
this.beanDefinitionNames.add(beanName);
this.beanDefinitionMap.put(beanName, beanDefinition);
前者是把beanName放到队列里,后者是把BeanDefinition放到map中,到此注册就完成了。在后面实例化的时候,就是把beanDefinitionMap中的BeanDefinition取出来,逐一实例化
BeanFactory准备完毕之后,代码又回到了ClassPathXmlApplicationContext里
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
// Prepare this context for refreshing.
prepareRefresh();
// Tell the subclass to refresh the internal bean factory.
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// Prepare the bean factory for use in this context.
prepareBeanFactory(beanFactory);
try {
// Allows post-processing of the bean factory in context subclasses.
postProcessBeanFactory(beanFactory);
// Invoke factory processors registered as beans in the context.
invokeBeanFactoryPostProcessors(beanFactory);
// Register bean processors that intercept bean creation.
registerBeanPostProcessors(beanFactory);
// Initialize message source for this context.
initMessageSource();
// Initialize event multicaster for this context.
initApplicationEventMulticaster();
// Initialize other special beans in specific context subclasses.
onRefresh();
// Check for listener beans and register them.
registerListeners();
// Instantiate all remaining (non-lazy-init) singletons.
finishBeanFactoryInitialization(beanFactory);
// Last step: publish corresponding event.
finishRefresh();
}
catch (BeansException ex) {
// Destroy already created singletons to avoid dangling resources.
destroyBeans();
// Reset 'active' flag.
cancelRefresh(ex);
// Propagate exception to caller.
throw ex;
}
}
}
也就是obtainFreshBeanFactory()方法执行之后,再进行下面的步骤。
总结来说,ApplicationContext将解析配置文件的工作委托给BeanDefinitionReader,然后BeanDefinitionReader将配置文件读取为xml的Document文档之后,又委托给BeanDefinitionDocumentReader
BeanDefinitionDocumentReader这个组件是根据xml元素的命名空间和元素名,起到一个路由的作用,实际的解析工作,是委托给BeanDefinitionParserDelegate来完成的
BeanDefinitionParserDelegate的解析工作完成以后,会返回BeanDefinitionHolder给BeanDefinitionDocumentReader,在这里,会委托给DefaultListableBeanFactory完成bean的注册
XmlBeanDefinitionReader(计数、解析XML文档),BeanDefinitionDocumentReader(依赖xml文档,进行解析和注册),BeanDefinitionParserDelegate(实际的解析工作)。可以看出,在解析bean的过程中,这3个组件的分工是比较清晰的,各司其职,这种设计思想值得学习
到此为止,bean的解析、注册、spring ioc 容器的实例化过程就基本分析结束了。