Android基础(数据结构)
目录
一,数组
二,链表
三,Map
四, Set
五,Tree
今晚不想写公司项目了,头晕晕的,整理下数据结构吧:
数据结构:简单说就是指一组数据的存储结构,算法就是操作数据的方法。
首先,需要明白数据结构的继承关系,数据结构一切都源于Collection接口和Map接口~
Collection继承接口Iterable:顾名思义迭代,该接口只是返回了迭代器对象Iterator
数据结构包括:数组、链表、栈、队列、散列表、二叉树、堆、调表、图、树;
算法包括:递归、排序、查找、搜索、哈希算法、贪心算法、分治算法、回溯算法、动态规划、字符串匹配算法。
说下继承关系List--->Collection-->Iterable
接口Iterable:顾名思义迭代,该接口只是返回了迭代器对象Iterator
一,数组
1,数组分配在一块连续的数据空间上,元素有序可重复,所以在分配空间时必须要确定它的大小。
2,优点是查询快,因为有角标/索引;缺点是增删慢,因为空间是固定的,增删需要复制数组中的元素。
3,用到的最多的是数组容器ArrayList,方法有:add(Object o),addAll(Object o),boolean contains(Object o),size(),remove()可传item,index等,clear(),indexOf(),lastIndexOf();
4,add方法和remove方法:
先扩容,再赋值。
public boolean add(E e) {
ensureCapacityInternal(size + 1); // 数组赋值操作
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
//1,先判断elementData的内容是否为空,如果是空的,就设置一个最小容量
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
//最小容量是默认值(10)和size + 1中的最大值
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
//2,开始扩容
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// 如果数组的新容量大于当前数据的大小,就需要扩容
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
//扩容函数
private void grow(int minCapacity) {
// 1.5倍扩容
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// 复制数组元素
elementData = Arrays.copyOf(elementData, newCapacity);
}
注意,当在指定位置 i 插入元素时,同样会扩容,并且位置i之后的元素都要通过复制的方法依次后移。所以增删效率低。
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1);
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null;
return oldValue;
}
5,get方法
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
E elementData(int index) {
return (E) elementData[index];
}
4,平时会用到的:
数组转ArrayList:
ArrayList
二,链表
1,链表是一块动态的空间,可以随意的改变长短,初始化时不需要确定大小。由一系列结点(链表中每一个元素称为结点)组成,每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个(上一个)结点地址的指针域。
2,增删快,因为只需要修改指针,不需要移动复制元素;查询慢,因为没有角标,只能从第一个元素开始查。
3,LinkedList:
数据结构是一个双向链表,元素有序可重复,内部结构有前驱和后继,不是连续的。
如图:两个指针一个指向前一个元素,一个指向后一个元素,单链表比这个少了一个指向前一个元素的指针。

private static class Node {
E item;// 数据
Node next;// 前一个节点
Node prev;// 后一个节点
Node(Node prev, E element, Node next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
方法有add(),contains(),remove,push(进栈),pop(出站)
首先看add方法和remove方法:
public boolean add(E e) {
//连接最后一个
linkLast(e);
return true;
}
void linkLast(E e) {
final Node l = last;
//创建一个节点,头指针指向last,后指针为空
final Node newNode = new Node<>(l, e, null);
last = newNode;
//如果last为空说明链表是空的,说明新增的节点是头结点;
//如果非空则把之前的last的后指针指向该节点。
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
public E remove(int index) {
// 检查index是否为0或是否越界
checkElementIndex(index);
return unlink(node(index));
}
//根据index查到对应的节点
Node node(int index) {
// size >> 1其实就是size/2
//如果index小于size/2,则从链表的第一个节点开始遍历到index然后返回节点;
//如果index大于size/2,则从链表最后一个节点开始倒叙遍历到index然后返回节点。
if (index < (size >> 1)) {
Node x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
//断开节点
E unlink(Node x) {
final E element = x.item;
final Node next = x.next;
final Node prev = x.prev;
//先判断是不是头结点,是的话那下个节点作为头结点;
//不是的话前一个节点的尾指针就指向后一个节点,这个节点前指针指向空
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
//判断是不是尾结点,是的话那前一个节点作为尾结点;
//不是的话那后一个节点的前指针指向前一个节点,这个节点的后指针指向空
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
再看下get方法:
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}三,Map
参考链接:https://blog.csdn.net/zhengwangzw/article/details/104889549
1,hashMap的原理
HashMap 是基于哈希表的 Map 接口的非同步实现。此实现提供所有可选的映射操作,并允许使用 null 值和 null 键。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。HashMap实际上是一个“链表散列”的数据结构,即数组和链表/红黑树的结合体,数组中的每一项又是一个链表。当新建一个 HashMap 的时候,就会初始化一个数组。数组默认长度是16,负载因子是0.75,当元素的个数大于数组长度*0.75时,数组会扩容。如果初始化时传入了初始大小k,那数组的长度就为 大于k的那个2的整数次方。数组用来确定桶的位置。
为什么采用红黑树:
因为链表较多时,时间复杂度最坏为O(lgn),但链表为O(n)。
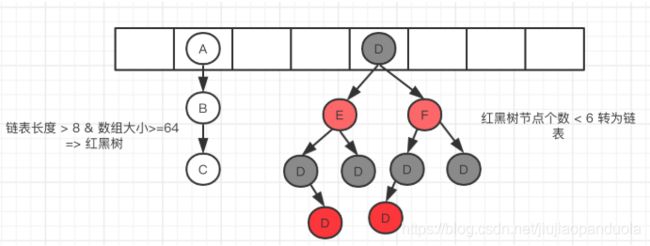
HashMap是基于hashing的原理,使用put(k,v)存储对象到HashMap中,使用get(k)从HashMap中获取对象。
2,hashMap的put方法
当put时会先对key调用hashCode()方法,得到hash值后会通过hash&(length-1)得到这个元素在数组中的下标index(桶的位置);
如果发生了hash碰撞(计算得到的hash值相等,也就是该位置已经有元素了),那就继续判断key是否相等,相等的话就覆盖,不相等的话那就放到链表最后(Java1.8前的版本是放到最前)。如果拉链过长,查询的性能会下降,所以在Java8中添加了红黑树结构,当一个桶的长度超过8时,就将其转为红黑树链表,如果小于6,再重新转换为普通链表。

当get时,HashMap会使用key对象的hashCode找到在数组中的位置(桶的位置),然后调用keys.equals()方法去找到在链表中的正确节点,最终找到值。
3,hash函数怎么设计的?
hash函数是先拿到key的hashcode,是32位的int值,然后让hashcode的高16位和低16位进行异或操作,这样设计可以尽可能降低hash碰撞,越分散越好,再就是位运算比较高效。
static final int hash(Object key){
int h;
//key为null时hash为0
return (key == null) ? 0 : (h=key.hashCode()) ^ (h>>>16);
}4,为什么高16位和低16位异或能降低hash碰撞?为什么不能直接采用hashCode?
因为key.hashCode()函数调用的是key键值类型自带的哈希函数,返回int型散列值。int值范围为-2147483648~2147483647(2的31次方),只要哈希函数映射的比较均匀松散,一般不会出现碰撞的,但是对内存来说,这么大的数组是放不下的。所以采用了取模运算:
bucketIndex = indexFor(hash, table.length);
static int indexFor(int h, int length) {
//与运算比%要高效
return h & (length-1);
}顺便说一下,这也正好解释了为什么HashMap的数组长度要取2的整数幂。因为这样(数组长度-1)正好相当于一个“低位掩码”。“与”操作的结果就是散列值的高位全部归零,只保留低位值,用来做数组下标访问。以初始长度16为例,16-1=15。2进制表示是00000000 00000000 00001111。和某散列值做“与”操作如下,结果就是截取了最低的四位值。
看下图:
第一行取得了key的hashcode;
第二行进行高16位和低16位的异或运算(相同为0,不同为1),这样前16位肯定都为1,这样就是为了混合原始哈希码的高位和低位,以此来加大低位的随机性。而且混合后的低位掺杂了高位的部分特征,这样高位的信息也被变相保留下来;
第三行进行(n-1)和hash的与运算(都为1才为1,其余情况为0),这里n表示默认初始长度16.
5,Hashtable 与 HashMap 的简单比较
HashTable 基于 Dictionary 类,而 HashMap 是基于 AbstractMap。Dictionary 是任何可将键映射到相应值的类的抽象父类,而 AbstractMap 是基于 Map 接口的实现,它以最大限度地减少实现此接口所需的工作。
HashMap 的 key 和 value 都允许为 null,而 Hashtable 的 key 和 value 都不允许为 null。HashMap 遇到 key 为 null 的时候,调用 putForNullKey 方法进行处理,而对 value 没有处理;Hashtable遇到 null,直接返回 NullPointerException。
Hashtable 方法是同步,而HashMap则不是。Hashtable 中的几乎所有的 public 的方法都是 synchronized 的,而有些方法也是在内部通过 synchronized 代码块来实现。所以有人一般都建议如果是涉及到多线程同步时采用 HashTable,没有涉及就采用 HashMap。
除了HashTable,还可以解决线程不安全的方法有:在 Collections 类中存在一个静态方法:synchronizedMap(),该方法创建了一个线程安全的 Map 对象,并把它作为一个封装的对象来返回。也可以使用ConcurrentHashMap,ConcurrentHashMap成员变量使用volatile 修饰,免除了指令重排序,同时保证内存可见性,另外使用CAS操作和synchronized结合实现赋值操作,多线程操作只会锁住当前操作索引的节点,如线程A只锁住A节点所在的链表,线程B智锁珠B节点所在的链表,互不干扰,这也叫分段锁。
6,HashMap有序吗?
因为hash值是随机插入的,所以无序!但LinkedHashMap是有序的!TreeMap也是有序的!
LinkedHashMap内部维护了一个单链表,有头尾节点,同时LinkedHashMap节点Entry内部除了继承HashMap的Node属性,还有before 和 after用于标识前置节点和后置节点。可以实现按插入的顺序或访问顺序排序。著名的LruCache算法(最近最少使用算法)就是通过LinkedHashMap来存缓存的。
TreeMap是按照Key的自然顺序或者Comprator的顺序进行排序,内部是通过红黑树来实现。所以要么key所属的类实现Comparable接口,或者自定义一个实现了Comparator接口的比较器,传给TreeMap用户key的比较。
7,简单介绍下LruCache算法
7.1,简要说下:LruCache内部维护了一个以访问顺序排序的LinkedHashMap,当put时,就会在集合中添加元素到队尾,并调用trimToSize()判断缓存是否已满,如果满了就无限循环删除头元素,即最近最少访问的元素,直到缓存小于最大值;当get时会调用LinkedHashMap的get方法获取对应集合的元素,同时更新该元素到队尾。
7.2,在构造方法中传入缓存的最大值,初始化LinkedHashMap,new LinkedHashMap
LruCache的成员变量有:
public class LruCache {
private final LinkedHashMap map;
private int size; //当前cache的大小
private int maxSize; //cache最大大小
private int putCount; //put的次数
private int createCount; //create的次数
private int evictionCount; //驱逐剔除的次数
private int hitCount; //命中的次数
private int missCount; //未命中次数
//...
}
7.3,当put时:采用synchronize同步代码块,将插入次数加1,更新缓存大小,最重要的是调用trimToSize()方法来判断缓存是否已满,如果满了就要死循环无限删除队首的元素,直到缓存大小小于最大值。
public void trimToSize(int maxSize) {
while (true) {
K key;
V value;
synchronized (this) {
//如果map为空并且缓存size不等于0或者缓存size小于0,抛出异常
if (size < 0 || (map.isEmpty() && size != 0)) {
throw new IllegalStateException(getClass().getName()
+ ".sizeOf() is reporting inconsistent results!");
}
//如果缓存大小size小于最大缓存,或者map为空,则不需要再删除缓存对象,跳出循环
if (size <= maxSize || map.isEmpty()) {
break;
}
//迭代器获取第一个对象,即队头的元素,近期最少访问的元素
Map.Entry toEvict = map.entrySet().iterator().next();
key = toEvict.getKey();
value = toEvict.getValue();
//删除该对象,并更新缓存大小
map.remove(key);
size -= safeSizeOf(key, value);
evictionCount++;
}
entryRemoved(true, key, value, null);
}
}
7.4,当get时:调用LinkedHashMap的get方法获取对应的集合元素,同时更新该元素到队尾。
7.5,LruCache的应用:ImageLoader
ImageLoaderTask这里继承自AsyncTask,是ImageLoader的内部类
很显然,ImageLoader类最关键在LruCache对象mBitmapLruCache上,这里用了Set集合来使异步加载线程ImageLoaderTask是唯一的。
ImageLoader主要逻辑是从内存LruCache对象中加载bitmap数据,如果没有,就网络加载数据变为Bitmap,然后存入LruCache对象mBitmapLruCache中。网络加载完的时候在异步线程中ImageLoaderTask把bitmap数据显示到ImageView。
四, Set
Set:无序(存入和取出的顺序不一定相同),不能重复,非线程安全的。直接继承Collection
HashSet :
数据结构是哈希表,存储的元素时哈希值,常数阶。
HashSet内部使用HashMap的key存储元素,以此来保证元素不重复;
HashSet是无序的,因为HashMap的key是无序的;
HashSet中允许有一个null元素,因为HashMap允许key为null;
若保证不添加相同元素,需重写对象(如Person类)的两个方法:hasncode(),equals()。
方法有:add,remove(Object o),contain(Object o),iteartor(),size(),isEmpty(),clear(),注意,没有get方法!!
五,Tree
树:树的数据元素间具有层次关系的非线性的结构。
前序遍历:中左右;后序遍历:左右中;
二叉树:
BinaryNode(T data , BinaryNode
TreeSet :
数据结构是树 对数阶log(n) 。
若保证不添加相同元素,元素的类(如Person类)需实现Comparable接口,并重写compareTo方法。
Map:key-value 键值对,key不能重复,value可以重复,通过key可以获得value
HashMap:数据结构是hashTable。
HashTree:树结构,按照key值排序,但key的类需实现Comparable接口