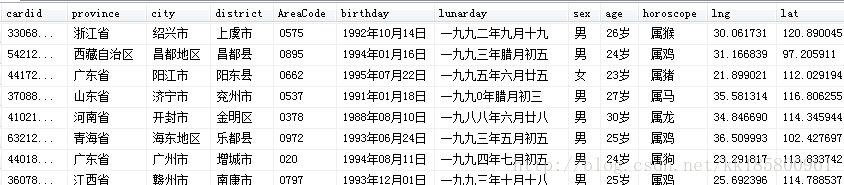
Python selenium 身份证信息在线解析爬取
当做笔记:
身份证地区查询,网络上的查询网站也比较多。现在查询数据库中的身份证,识别其中的信息。主要通过该网站:http://www.gpsspg.com/sfz/
脚本:
#-*- coding: utf-8 -*-
# python 3.5.0
import sqlalchemy
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
class IDCARD(object):
def __init__(self,d):
self._engine = sqlalchemy.create_engine("mssql+pymssql://%s:%s@%s/%s" %(d['user'],d['pwd'],d['inst'],d['db']))
self._loginurl = "http://www.gpsspg.com/sfz/"
#self._chromedriver = 'D:/Python35/selenium/webdriver/chromedriver.exe'
#self._driver = webdriver.Chrome(self._chromedriver)
#后台模拟,不必模拟打开浏览器
self._chromedriver = 'D:/Python35/mypy/phantomjs/bin/phantomjs.exe'
self._driver = webdriver.PhantomJS(self._chromedriver)
#从数据库中查询身份证返回到 list
def get_data_from_db(self):
sql = """SELECT identityCard FROM [dbo].[ClientInfoAll]"""
list = (pd.read_sql_query(sql, self._engine))['identityCard'].tolist()
return list
#打开查询页面
def set_url(self,cardid):
self._loginurl = r"http://www.gpsspg.com/sfz/?q=%s" % cardid
self._driver.get(self._loginurl)
#解析页面保存数据到 df
def get_date(self,cardid,df):
province, city ,district, AreaCode, birthday, lunarday, sex, age, horoscope, lng, lat = (None,)*11
table = self._driver.find_element_by_xpath("//table[@class='tabs']/tbody")
id = table.find_element_by_xpath(".//tr[1]/td[2]").text.strip()
if cardid == id:
district = table.find_element_by_xpath(".//tr[2]/td[2]").text.strip()+' '
province = district.split(' ')[0]
city = district.split(' ')[1]
district = district.split(' ')[2]
AreaCode = table.find_element_by_xpath(".//tr[2]/td[4]").text.strip()
birthday = table.find_element_by_xpath(".//tr[3]/td[2]").text.strip()
lunarday = table.find_element_by_xpath(".//tr[3]/td[4]").text.strip()
horoscope = table.find_element_by_xpath(".//tr[4]/td[2]").text.strip()
sex = horoscope.split('(')[0]
age = horoscope.replace(')','(').split('(')[1]
horoscope = horoscope.split(')')[1]
lat = table.find_element_by_xpath(".//tr[4]/td[4]").text.strip()+','
lng = lat.split(',')[0]
lat = lat.split(',')[1]
df.loc[df.shape[0]+1] = {'cardid':cardid,'province':province,'city':city,'district':district,'AreaCode':AreaCode
,'birthday':birthday,'lunarday':lunarday,'sex':sex,'age':age,'horoscope':horoscope,'lng':lng,'lat':lat}
#若网页打开太慢,强制中断则没有数据,也可以把 df 移到此函数,每查询一个身份证保存一次。
#遍历身份证保存df到数据库
def get_alldata(self):
list_idcards = self.get_data_from_db()
print(type(list_idcards[10]))
df = pd.DataFrame(columns = ['cardid','province','city','district','AreaCode','birthday','lunarday','sex','age','horoscope','lng','lat'])
for idcard in list_idcards:
print("当前:%s" % idcard)
self.set_url(idcard)
self.get_date(idcard,df)
df.to_sql('newidcard', self._engine, if_exists='replace',index=False) #注意:此处直接替换(replace)当前表 newidcard
if __name__ == "__main__":
conn = {'user':'账号','pwd':'密码','inst':'实例','db':'数据库'}
idcard = IDCARD(conn)
idcard.get_alldata()