浅谈Linux cgroup机制与YARN的CPU资源隔离
前言
在之前的这篇文章中,笔者已经讲解过了YARN是如何实现内存资源隔离的。但是只隔离内存还不够,我们在生产环境中经常可以发现有计算密集型任务争用NodeManager的CPU,以及个别Container消耗太多CPU资源导致其他系统服务抖动的情况。好在Hadoop 2.2版本之后,YARN通过利用Linux系统的cgroup机制支持了CPU资源隔离。本文先简单看看cgroup,然后分析一下YARN的CPU资源隔离的方案。
简单入门cgroup
cgroup(control group)机制在Linux Kernel 2.6.24引入,主要用来限制与隔离进程组的资源——包括CPU、内存、磁盘、网络等,也可以用于控制优先级、统计资源用量、挂起与恢复进程。
从用户的角度看,一个cgroup就是一组按某种资源控制的标准划分的进程(task)。cgroup被组织成树形结构,称为层级(hierarchy),使得子cgroup可以继承父cgroup的部分控制属性。同时每个层级又会与一个或多个子系统(subsystem)关联,子系统会在该层级的所有树节点上执行具体的资源控制操作。也就是说,子系统实际扮演着资源控制器的角色。
内核为每种资源都定义了子系统,功能各自不同,举例如下。
- cpu子系统:限制进程的CPU使用率;
- cpuacct子系统:统计进程的CPU使用报告;
- cpuset子系统:将进程绑定到指定的CPU或内存节点;
- memory子系统:限制进程的内存使用率,并统计进程的内存使用报告;
- blkio子系统:限制进程的块设备I/O速率;
- devices子系统:指定进程可以访问哪些设备;
- net_cls子系统:标记进程收发的数据包,进而用tc限制网络流量。
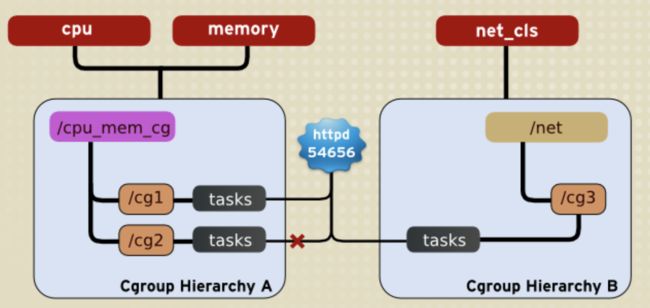
下图示出有两个层级的cgroup结构,其中层级A关联了cpu和memory两个子系统,层级B关联了net_cls子系统。注意图中的红色小叉,它表示同一个进程可以属于不同的层级,但是不能同时属于同一个层级的两个cgroup。
为了方便用户操作,cgroup通过VFS向用户提供文件系统接口(如同/proc一样)。执行mount -t cgroup命令可以查看已挂载的cgroup对应各个子系统的目录。这里系统版本是CentOS 7,cgroup的根目录是/sys/fs/cgroup;CentOS 6则是/cgroup。
~ mount -t cgroup
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_prio,net_cls)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct,cpu)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup可控制的方面很多,可以说是容器技术的鼻祖,在Docker、Kubernetes等框架中应用甚广。但YARN仅用它实现了CPU资源隔离,所以下面来认识一下CPU子系统。
cgroup的CPU子系统
在CPU子系统的根目录下创建一个新的cgroup目录,会自动生成一些文件。
~ cd /sys/fs/cgroup/cpu
~ mkdir cg_test
~ ls -1 cg_test
cgroup.clone_children
cgroup.event_control
cgroup.procs
cpuacct.stat
cpuacct.usage
cpuacct.usage_percpu
cpu.cfs_period_us
cpu.cfs_quota_us
cpu.rt_period_us
cpu.rt_runtime_us
cpu.shares
cpu.stat
notify_on_release
tasks
最主要的几个文件及它们的含义列举如下。
tasks
保存有该cgroup内包含的PID列表,可以动态增减。cpu.cfs_period_us
表示CPU时间片的调度周期,单位为微秒,默认值100000(即100毫秒)。其中CFS一词代表"Completely Fair Scheduler",即内核中的完全公平进程调度器。cpu.cfs_quota_us
表示给这个cgroup里的进程分配的CPU时间片的长度,单位为微秒,默认值-1(即不限制)。举个例子,如果cpu.cfs_period_us=100000,且cpu.cfs_quota_us=200000,就表示该cgroup的进程最多可以使用200%的CPU;如果cpu.cfs_quota_us=50000,就表示最多可以使用50%的CPU。cpu.shares
表示cgroup内进程占用CPU权重的相对比例,默认值1024。举个例子,组A的cpu.shares=1024,组B的cpu.shares=2048,那么当两个cgroup中的进程都满负载运行时,组B能占用的CPU资源就是组A的两倍。如果有一方负载较低时,另一方还可以利用空闲的CPU资源。可见,它是比上述两个参数更为弹性化的限制。cpu.stat
保存有该cgroup的CPU资源的统计信息,包含cgroup创建开始经过的CPU周期,以及被cgroup限制掉的CPU周期和时间长度。
cgroup的层级关系就靠目录结构表示。如果我们在cg_test目录下再新建cg_test_sub1、cg_test_sub2目录,那么这两个cgroup就是cg_test的子节点,以此类推。
来操作一下吧。先用Python跑一个死循环,然后top之,发现该进程占用100%的CPU。
~ echo 'while True: pass' | python &
[1] 15054
~ top
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
15054 root 20 0 123356 4476 1952 R 100.0 0.0 0:14.74 python
然后将刚才创建的cg_test组的cpu.cfs_quota_us值改为30000,并将该进程的PID写入tasks,再top之,就会看到它的CPU占用降低到了30%。
~ echo 30000 > /sys/fs/cgroup/cpu/cg_test/cpu.cfs_quota_us
~ echo 15054 > /sys/fs/cgroup/cpu/cg_test/tasks
~ top
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
15054 root 20 0 123356 4476 1952 R 29.9 0.0 1:54.17 python
YARN CPU资源隔离实现
要启用YARN的CPU资源隔离,就得在yarn-site.xml里设定以下两个参数。更加详细的设定(如cgroup层级和路径等)请参考官方文档。
yarn.nodemanager.container-executor.class: org.apache.hadoop.yarn.server.nodemanager.LinuxContainerExecutor
yarn.nodemanager.linux-container-executor.resources-handler.class: org.apache.hadoop.yarn.server.nodemanager.util.CgroupsLCEResourcesHandler
我们需要使用LinuxContainerExecutor来替代默认的DefaultContainerExecutor,因为前者会以YARN App提交者的身份执行创建和销毁Container的动作,并且支持cgroup机制。另外,还需要配置与它配套的支持cgroup的资源处理器类,即CgroupsLCEResourcesHandler。
接下来翻翻源码。在启动Container的LinuxContainerExecutor.launchContainer()方法中,调用了CgroupsLCEResourcesHandler.preExecute()方法初始化资源限制。
public void preExecute(ContainerId containerId, Resource containerResource)
throws IOException {
setupLimits(containerId, containerResource);
}
private void setupLimits(ContainerId containerId,
Resource containerResource) throws IOException {
String containerName = containerId.toString();
if (isCpuWeightEnabled()) {
int containerVCores = containerResource.getVirtualCores();
createCgroup(CONTROLLER_CPU, containerName);
int cpuShares = CPU_DEFAULT_WEIGHT * containerVCores;
updateCgroup(CONTROLLER_CPU, containerName, "shares",
String.valueOf(cpuShares));
if (strictResourceUsageMode) {
int nodeVCores =
conf.getInt(YarnConfiguration.NM_VCORES,
YarnConfiguration.DEFAULT_NM_VCORES);
if (nodeVCores != containerVCores) {
float containerCPU =
(containerVCores * yarnProcessors) / (float) nodeVCores;
int[] limits = getOverallLimits(containerCPU);
updateCgroup(CONTROLLER_CPU, containerName, CPU_PERIOD_US,
String.valueOf(limits[0]));
updateCgroup(CONTROLLER_CPU, containerName, CPU_QUOTA_US,
String.valueOf(limits[1]));
}
}
}
}
setupLimits()方法首先将单个Container申请的虚拟核心数记为containerVCores,然后调用createCgroup()方法创建包含Container名称的cgroup文件目录,也就是说一个Container对应一个cgroup。然后根据containerVCores设定这个cgroup的cpu.shares值(乘以默认值1024),即申请核心数越多,可占用的CPU资源比例越大。
接下来检查yarn.nodemanager.resource.percentage-physical-cpu-limit参数是否为true。若为true,表示启用了严格限制模式,需要设置cpu.cfs_period_us和cpu.cfs_quota_us。
使用containerVCores * yarnProcessors / nodeVCores推导出单个Container对应的物理核心数,其中yarnProcessors表示NodeManager所在节点的可用物理核心数(即总核心数乘以参数yarn.nodemanager.resource.percentage-physical-cpu-limit指定的百分比比例),nodeVCores表示单个NodeManager的虚拟核心数。
最后就是getOverallLimits()方法了。
int[] getOverallLimits(float yarnProcessors) {
int[] ret = new int[2];
if (yarnProcessors < 0.01f) {
throw new IllegalArgumentException("Number of processors can't be <= 0.");
}
int quotaUS = MAX_QUOTA_US;
int periodUS = (int) (MAX_QUOTA_US / yarnProcessors);
if (yarnProcessors < 1.0f) {
periodUS = MAX_QUOTA_US;
quotaUS = (int) (periodUS * yarnProcessors);
if (quotaUS < MIN_PERIOD_US) {
LOG
.warn("The quota calculated for the cgroup was too low. The minimum value is "
+ MIN_PERIOD_US + ", calculated value is " + quotaUS
+ ". Setting quota to minimum value.");
quotaUS = MIN_PERIOD_US;
}
}
// cfs_period_us can't be less than 1000 microseconds
// if the value of periodUS is less than 1000, we can't really use cgroups
// to limit cpu
if (periodUS < MIN_PERIOD_US) {
LOG
.warn("The period calculated for the cgroup was too low. The minimum value is "
+ MIN_PERIOD_US + ", calculated value is " + periodUS
+ ". Using all available CPU.");
periodUS = MAX_QUOTA_US;
quotaUS = -1;
}
ret[0] = periodUS;
ret[1] = quotaUS;
return ret;
}
可见,YARN采用了固定cpu.cfs_quota_us值(为1000000,即1秒),而改变cpu.cfs_period_us值的方式。cpu.cfs_period_us的值恰好是cpu.cfs_quota_us除以上面计算出来的单个Container对应的物理核心数,所以核心数越多的Container,cpu.cfs_period_us越小,可利用的CPU资源就越多。
最后再举个例子。假设NodeManager可用物理核心数为4(即总CPU资源为400%),虚拟核心数为6,根据上述算法,考虑3种情况。
- 启动4个Container,每个Container申请1*vCore——普通模式每个Container分配100%,严格模式每个Container分配67%;
- 启动2个Container,A申请2*vCore,B申请1*vCore——普通模式为A分配200%,B分配100%,严格模式为A分配133%,B分配67%。
- 启动4个Container,A组两个申请2*vCore,B组两个申请1*vCore——两种模式均为为A组分配133%,B分配67%。
由上面的分析我们可以看出,cpu.share方式相当于"soft limit",用于控制Container使用CPU资源的下限,并且更加灵活,总体资源利用率高,但无法完全避免不稳定因素。而cpu.cfs_period_us+cfs_quota_us方式相当于"hard limit",严格限制了Container使用CPU资源的上限,显然更加稳定,但是在低负载的场景下,CPU资源就会被浪费,鱼与熊掌不可兼得。
后记
写得还是挺乱的,主要是因为这块的内容本来就很乱…
写本文的契机还是来源于在Flink社区大群里解答的问题。
民那晚安。