python爬虫 -10- 新片场案列(scrapy的使用)
创建项目
scrapy startproject xpc
创建requirements.txt
在xpc目录下创建requirements.txt文件
scrapy
redis
requests
pymysql
创建完成后,输入以下导入模块
pip install -r requirement.txt
初始化爬虫
scrapy genspider discovery xinpianchang.com
爬取逻辑
import scrapy
from scrapy import Request
import json
import random
import re
from items import PostItem, CommentItem, ComposerItem, CopyrightItem
from scrapy_redis.spiders import RedisSpider
def my_strip(info):
if info:
return info.strip()
return ""
cookies = {
'Authorization': 'A26F51084B88500BF4B885427B4B8858B394B885B7E7169365C9'
}
def gen_session_id():
return "".join(random.sample([chr(i) for i in range(97, 97 + 26)], 26))
def convert_int(s):
if type(s) is str:
return int(s.replace(",", ""))
return 0
class DiscoverySpider(scrapy.Spider):
name = 'discovery'
allowed_domains = ['xinpianchang.com', 'openapi-vtom.vmovier.com', 'app.xinpianchang.com']
start_urls = ['https://www.xinpianchang.com/channel/index/type-/sort-like/duration_type-0/resolution_type-/page-1']
# 翻页计数器
page_count = 0
# def start_requests(self):
# for url in self.start_urls:
# c = cookies.copy()
# c.update(PHPSESSID=gen_session_id(),
# channel_page="apU%3D") # 第20页
# request = Request(url, cookies=c, dont_filter=True)
# yield request
def parse(self, response):
self.page_count += 1
if self.page_count >= 50:
self.page_count = 0
cookies.update(PHPSESSID=gen_session_id())
post_list = response.xpath("//ul['video-list']/li")
url = "https://www.xinpianchang.com/a%s?from=ArticleList"
for post in post_list:
pid = post.xpath("./@data-articleid").get()
request = response.follow(url % pid, self.parse_post)
request.meta["pid"] = pid
request.meta["thumbnail"] = post.xpath("./a/img/@_src").get()
yield request
pages = response.xpath("//div[@class='page']/a/@href").extract()
for page in pages[1:]:
next_page = f"https://www.xinpianchang.com{page}"
yield response.follow(next_page, self.parse, cookies=cookies)
# 解析每个视频的信息
def parse_post(self, response):
pid = response.meta["pid"]
post = PostItem()
post["pid"] = pid
post["thumbnail"] = response.meta["thumbnail"]
post["title"] = response.xpath("//div[@class='title-wrap']/h3/text()").get()
cates = response.xpath("//span[contains(@class, 'cate')]//text()").extract()
post["category"] = "".join([cate.strip() for cate in cates])
post["created_at"] = response.xpath("//span[contains(@class, 'update-time')]/i/text()").get()
post["play_counts"] = response.xpath("//i[contains(@class, 'play-counts')]/@data-curplaycounts").get()
post["like_counts"] = response.xpath("//span[contains(@class, 'like-counts')]/@data-counts").get()
tags = response.xpath("//div[contains(@class, 'tag-wrapper')]/a/text()").extract()
post["tag"] = "-".join([tag.strip() for tag in tags])
desc = response.xpath("//p[contains(@class, 'desc')]/text()").get()
post["description"] = my_strip(desc)
# 视频
vid = response.xpath(
"//div[@class='filmplay-data-btn fs_12']//a[@class='collection-star hollow-star']/@data-vid").get()
video_url = f"https://openapi-vtom.vmovier.com/v3/video/{vid}?expand=resource&usage=xpc_web&appKey=61a2f329348b3bf77"
request = Request(video_url, callback=self.parse_video)
request.meta["post"] = post
yield request
# 评论
comment_url = f"https://app.xinpianchang.com/comments?resource_id={pid}&type=article&page=1&per_page=24"
request = Request(comment_url, callback=self.parse_comment)
request.meta["pid"] = pid
yield request
# 创作者
creator_url = response.xpath("//ul[@class='creator-list']/li/a/@href").extract()
for url in creator_url:
if url.startswith("/article"):
continue
cid = url[2:url.index("?")]
url = f"https://www.xinpianchang.com{url}"
request = response.follow(url, callback=self.parse_composer)
request.meta["dont_merge_cookies"] = True
request.meta["cid"] = cid
yield request
# 解析视频信息请求
def parse_video(self, response):
post = response.meta["post"]
result = json.loads(response.text)
post["video"] = result["data"]["resource"]["progressive"][0]["url"]
post["preview"] = result["data"]["video"]["cover"]
yield post
# 解析评论信息请求
def parse_comment(self, response):
result = json.loads(response.text)
for c in result["data"]["list"]:
comment = CommentItem()
comment["uname"] = c["userInfo"]["username"]
comment["avatar"] = c["userInfo"]["avatar"]
comment["uid"] = c["userInfo"]["id"]
comment["comment_id"] = c["id"]
comment["pid"] = c["resource_id"]
comment["content"] = c["content"]
comment["created_at"] = c["addtime"]
comment["like_counts"] = c["count_approve"]
if c["referid"]:
comment["referid"] = c["referid"]
yield comment
next_page = result["data"]["next_page_url"]
if next_page:
next_page = f"https://app.xinpianchang.com{next_page}"
yield response.follow(next_page, self.parse_comment)
# 解析创作者请求
def parse_composer(self, response):
banner, = re.findall("background-image:url\((.+?)\)",
response.xpath("//div[@class='banner-wrap']/@style").get())
composer = ComposerItem()
composer["banner"] = banner
composer["cid"] = response.meta["cid"]
composer["name"] = my_strip(response.xpath("//p[contains(@class,'creator-name')]/text()").get())
composer["intro"] = my_strip(response.xpath("//p[contains(@class,'creator-desc')]/text()").get())
composer["like_counts"] = convert_int(response.xpath("//span[contains(@class,'like-counts')]/text()").get())
composer["fans_counts"] = convert_int(response.xpath("//span[contains(@class,'fans-counts')]/text()").get())
composer["follow_counts"] = convert_int(
response.xpath("//span[@class='follow-wrap']/span[contains(@class,'fw_600')]/text()").get())
location = response.xpath("//span[contains(@class, 'icon-location')]/following-sibling::span[1]/text()").get()
if location:
composer["location"] = location.replace("\xa0", "")
else:
composer["location"] = ""
composer["career"] = response.xpath(
"//span[contains(@class, 'icon-career')]/following-sibling::span[1]/text()").get()
yield composer
item
import scrapy
from scrapy import Field
class PostItem(scrapy.Item):
"""保存视频信息的item"""
table_name = 'posts'
pid = Field()
title = Field()
thumbnail = Field()
preview = Field()
video = Field()
video_format = Field()
duration = Field()
category = Field()
created_at = Field()
play_counts = Field()
like_counts = Field()
description = Field()
tag = Field()
class CommentItem(scrapy.Item):
table_name = 'comments'
comment_id = Field()
pid = Field()
uid = Field()
avatar = Field()
uname = Field()
created_at = Field()
content = Field()
like_counts = Field()
referid = Field()
class ComposerItem(scrapy.Item):
table_name = 'composers'
cid = Field()
banner = Field()
avatar = Field()
verified = Field()
name = Field()
intro = Field()
like_counts = Field()
fans_counts = Field()
follow_counts = Field()
location = Field()
career = Field()
class CopyrightItem(scrapy.Item):
table_name = 'copyrights'
pcid = Field()
pid = Field()
cid = Field()
roles = Field()
pipelines
存储在mysql中
import pymysql
# 保存在mysql中
class MysqlPipeline:
# 开始调用一次
def open_spider(self, spider):
self.conn = pymysql.connect(
host="127.0.0.1",
port=3306,
db="spider",
user="jiang",
password="jiang",
charset="utf8"
)
self.cur = self.conn.cursor()
# 关闭调用一次
def close_spider(self, spider):
self.cur.close()
slice.conn.close()
# 每产生一个调用一次
def process_item(self, item, spider):
# keys = item.keys()
# values = list(item.values) # 是一个元组-->集合
keys, values = zip(*item.items())
sql = "insert into {}({}) values({}) ON DUPLICATE KEY UPDATE {}".format(
item.table_name,
','.join(keys),
','.join(['%s']*len(keys)),
",".join(["`{}`=%s".format(key) for key in keys])
)
self.cur.execute(sql, values*2)
self.conn.commit()
# 输出语句
print(self.cur._last_executed)
return item
settings
ITEM_PIPELINES = {
'xpc.pipelines.MysqlPipeline': 300,
}
middleware
动态ip代理
from collections import defaultdict
from scrapy import signals
from scrapy.exceptions import NotConfigured
import random
import redis
from twisted.internet.error import ConnectionRefusedError, TimeoutError
class RandomProxyMiddleware(object):
def __init__(self, settings):
# 初始化变量和配置
self.r = redis.Redis(host="host", password="password")
self.proxy_key = settings.get("PROXY_REDIS_KEY")
self.proxy_stats_key = self.proxy_key+"_stats"
self.state = defaultdict(int)
self.max_failed = 3
@property
def proxies(self):
proxies_b = self.r.lrange(self.proxy_key, 0, -1)
proxies = []
for proxy_b in proxies_b:
proxies.append(bytes.decode(proxy_b))
print("proxy是:", proxies)
return proxies
@classmethod
def from_crawler(cls, crawler):
# 1.创建中间件对象
if not crawler.settings.getbool("HTTPPROXY_ENABLED"):
raise NotConfigured
return cls(crawler.settings)
def process_request(self, request, spider):
# 3.为每个request对象分配一个随机的ip代理
if self.proxies and not request.meta.get("proxy"):
request.meta["proxy"] = random.choice(self.proxies)
def process_response(self, request, response, spider):
# 4.请求成功,调用process_response
cur_proxy = request.meta.get("proxy")
# 判断是否被对方封禁
if response.status in (401, 403):
print(f"{cur_proxy} got wrong code {self.state[cur_proxy]} times")
# 给相应的IP失败次数+1
# self.state[cur_proxy] += 1
self.r.hincrby(self.proxy_stats_key, cur_proxy, 1)
# 当某个IP的失败次数累计到一定数量
failed_times = self.r.hget(self.proxy_stats_key, cur_proxy) or 0
if int(failed_times) >= self.max_failed:
print("got wrong http code {%s} when use %s" % (response.status, request.get("proxy")))
# 可以认为该IP已经被对方封禁了,从代理池中将该IP删除
self.remove_proxy(cur_proxy)
del request.meta["proxy"]
# 重新请求重新安排调度下载
return request
return response
def process_exception(self, request, exception, spider):
# 4.请求失败,调用process_exception
cur_proxy = request.meta.get("proxy")
# 如果本次请求使用了代理,并且网络请求报错,认为该IP出现问题了
if cur_proxy and isinstance(exception, (ConnectionRefusedError, TimeoutError)):
print(f"error occur where use proxy {exception} {cur_proxy}")
self.remove_proxy(cur_proxy)
del request.meta["proxy"]
return request
def remove_proxy(self, proxy):
"""在代理IP列表中删除指定代理"""
if proxy in self.proxies:
self.r.lrem(self.proxy_key, 1, proxy)
print("remove %s from proxy list" % proxy)
settings
DOWNLOADER_MIDDLEWARES = {
'xpc.middlewares.RandomProxyMiddleware': 749,
}
# 代理ip
PROXY_REDIS_KEY = "discovery:proxy"
scrapy-redis的使用
pip install scrapy-redis
settings中配置
# Enables scheduling storing requests queue in redis.
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# Ensure all spiders share same duplicates filter through redis.
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# REDIS_URL = 'redis://ip:6379'
REDIS_HOST = 'host'
REDIS_PORT = 6379
REDIS_PARAMS = {
'password': 'pass',
}

会根据redis中的数据进行继续爬取
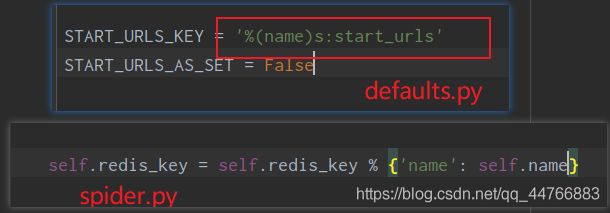
使用RedisSpider
from scrapy_redis.spiders import RedisSpider

会根据redis中的url,自动进行抓取,是不需要start_urls的,我们只要在redis中的discovety:start_urls中增加一条url数据。(lpush diccovery:start_urls url)。
这样我们就可以使用运行多个爬虫,只要一有url,一起进行爬取
看一下源码,我们不需要手动创建key