python爬虫 -11- selenium(简单介绍,爬取京东,爬取去哪儿网)
selenium
简单使用
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("http://baidu.com")

进行关键字搜素
kw = driver.find_element_by_id("kw")
kw.send_keys("Python")
su = driver.get_element_by_id("su")
su.click()
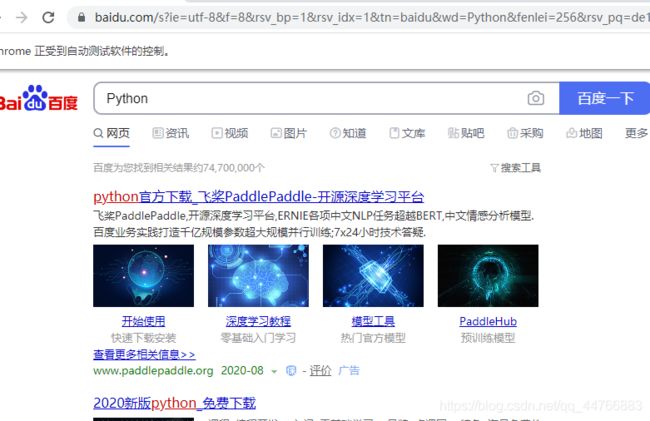
获取标题
h3_list = driver.find_elements_by_tag_name("h3")
for h3 in h3_list:
print(h3.text)
输出
python官方下载_飞桨PaddlePaddle-开源深度学习平台
2020新版python_免费下载
python-python下载免费
python_万和-打造Python全栈开发工程师
python编程_在家就能让孩子学习编程的教育平台
Welcome to Python.org官方
Python(计算机程序设计语言)_百度百科
python官网 - Download Python | Python.org
Python 基础教程 | 菜鸟教程
Python还能火多久?
Python教程 - 廖雪峰的官方网站
你都用 Python 来做什么? - 知乎
Python3 * 和 ** 运算符_极客点儿-CSDN博客_python **
Python基础教程,Python入门教程(非常详细)
Python-薯条编程-在线教程-小班授课高薪就业培训
运行js
driver.execute_script("alert('123')")
driver.execute_script("window.scrollTo(300, document.body.scrollHeight)")
启动浏览器
from selenium import webdriver
# 启动chrome浏览器
driver = webdriver.Chrome()
# 指定chromedriver的路径并启动Chrome
driver = webdriver.Chrome(executable_path='/home/user/chromedirver')
#启动chrome-headless
from selenium.webdriver.chrome.options import Options
option = Options()
option.add_argument('--headless')
driver = webdriver.Chrome(chrome_options=option)
# 启动phantomjs
driver = webdriver.PhantomJs()
chrome-headless是无界面版的chrome,它替代了停止维护的phantomjs.
控制浏览器
# 访问某个url
driver.get('https://www.baidu.com')
# 刷新
driver.refersh()
# 前进
driver.forward()
# 后退
driver.back()
#退出
driver.quit()
# 当前的url
driver.current_url
# 截图
driver.save_screenshot('/tmp/test.png')
元素查找
18个find函数
# 根据元素的class属性的值查找
driver.find_element_by_class_name
# 用CSS选择器查找
driver.find_element_by_css_selector
# 根据元素的ID
driver.find_element_by_id
# 根据链接内的文本查找
find_element_by_link_text
# 根据元素的name属性查找
find_element_by_name
# 根据链接内的文本是否包含指定的查找文字
find_element_by_partial_link_text
# 根据标签名查找
find_element_by_tag_name
# 根据xpath表达示查找
find_element_by_xpath
执行js
# 将网页滚动到最底部
driver.execute_script('window.scrollTo(0, document.body.scrollHeight)')
# 执行异步的js函数
driver.execute_async_script('send_xml_request()')
等待,wait
-
隐式等待
# 查找某个(某些)元素,如果没有立即查找到,则等待10秒 driver.implicityly_wait(10) -
显式等待
from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.by import By # 查找一个按钮 # 最长等待10秒,直到找到查找条件中指定的元素 sort_btn = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.XPATH, './/div[@class="f-sort"]/a[2]')) )这两个等待,显示等待通常更符合我们的程序逻辑。当我们对页面的加载方式还不太确定的时候,也可以隐式等待。
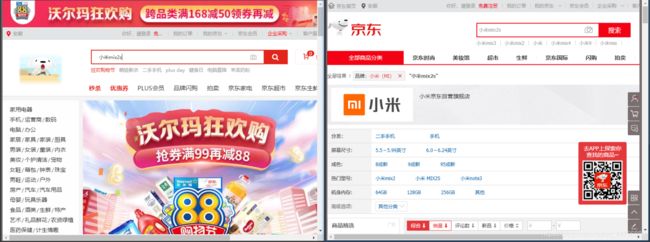
爬取京东
import sys
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.chrome.options import Options
import pyexcel
if __name__ == '__main__':
keyword = '小米mix2s'
if len(sys.argv) > 1:
keyword = sys.argv[1]
# 设置不打开浏览器
options = Options()
options.add_argument("--headless")
driver = webdriver.Chrome(chrome_options=options)
driver.get("https://www.jd.com/")
# 输入关键字
kw = driver.find_element_by_id("key")
kw.send_keys(keyword)
kw.send_keys(Keys.ENTER)
# 截个图
driver.save_screenshot("1.png")
# 销量进行排序
time.sleep(2)
sort_btn = driver.find_element_by_xpath(".//div[@class='f-sort']/a[2]")
sort_btn.click()
driver.save_screenshot("2.png")
has_next = True
rows = []
while has_next:
time.sleep(3)
curr_page = driver.find_element_by_xpath("//div[contains(@class,'page')]//a[@class='curr']").text
print("----------------current page is %s----------------" % curr_page)
# 先获取整个商品区域的尺寸坐标
goods_list = driver.find_element_by_id("J_goodsList")
# 根据区域的大小决定往下滑动多少
y = goods_list.rect["y"] + goods_list.rect["height"]
driver.execute_script("window.scrollTo(0, %s)" % y)
# 获取所有的商品节点
products = driver.find_elements_by_class_name("gl-item")
for product in products:
row = {}
sku = product.get_attribute("data-sku")
row["price"] = product.find_element_by_css_selector(f"strong.J_{sku}").text
row["name"] = product.find_element_by_css_selector("div.p-name>a>em").text
row["comments"] = product.find_element_by_id(f"J_comment_{sku}").text
try:
row["shop"] = product.find_element_by_css_selector("div.p-shop>span>a").text
except NoSuchElementException as e:
row["shop"] = ""
rows.append(row)
print(row)
next_page = driver.find_element_by_css_selector("a.pn-next")
if "disabled" in next_page.get_attribute("class"):
has_next = False
else:
next_page.click()
pyexcel.save_as(records=rows, dest_file_name=f"{keyword}.xls")
# 退出
driver.quit()
结果:两张png图片和一个excel表格

抓取去哪儿网
import sys
import time
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
if __name__ == "__main__":
start_name = "北京"
dest_name = "青岛"
if len(sys.argv) > 1:
start_name = sys.argv[1]
dest_name = sys.argv[2]
driver = webdriver.Chrome()
driver.get("https://www.qunar.com/?ex_track=auto_4e0d874a")
# 起始地
start = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.XPATH, "//input[@name='fromCity']"))
)
start.clear()
start.send_keys(start_name)
time.sleep(0.5)
start.send_keys(Keys.ENTER)
# 目的地
dest = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.XPATH, "//input[@name='toCity']"))
)
# dest = driver.find_element_by_xpath("//input[@name='toCity']")
dest.send_keys(dest_name)
time.sleep(0.5)
dest.send_keys(Keys.ENTER)
search = driver.find_element_by_css_selector("button.button-search")
search.click()
# 获取航班数据
flights = WebDriverWait(driver, 10).until(
EC.presence_of_all_elements_located(By.XPATH, "//div[@class='m-airfly-lst']/div[@class='b-airfly']")
)
for flight in flights:
f_data = {}
airlines = flight.find_elements_by_xpath(".//div[@class='d-air']")
f_data["airlines"] = [airlines.text for airlines in airlines]
f_data["depart"] = flight.find_element_by_xpath(".//div[@class='sep-lf']").text
f_data["duration"] = flight.find_element_by_xpath(".//div[@class='sep-ct']").text
f_data["dest"] = flight.find_element_by_xpath(".//div[@class='sep-rt']").text
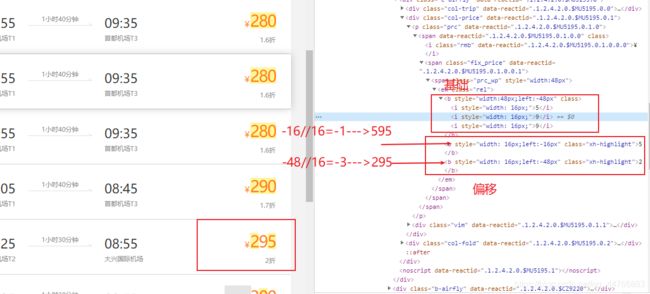
# 对价格的处理,价格有一个基础值和真实值的偏移
fake_price = list(flight.find_element_by_xpath(".//span[@class='prc_wp']/em/b[1]").text)
covers = flight.find_elements_by_xpath(".//span[@class='prc_wp']/em/b[position()>1]")
for c in covers:
index = int(c.value_of_css_property('left')[:-2]) // c.size['width']
fake_price[index] = c.text
f_data["price"] = "".join(fake_price)
真实价格的计算