尝尝鲜|Spark 3.1自适应执行计划
读本文前,应该先读读昨天的文章
Spark join种类(>3种)及join选择依据
每个框架产生都是为了解决一类问题,每个模块的优化也是为了解决一定的场景下的性能瓶颈。浪尖今天分享的关于Spark 3.1之后的自适应执行计划,主要针对以下几个场景,并且有百度率先研发的,不过社区之前一直没有采纳,spark 3.0的预发布版本参数也是不全,到了Spark 3.1的beta版已经可用,浪尖已经完成了测试。
1.解决场景
Spark Adative好几年前就开始提了,现在网络上流行的spark自适应执行计划也坑了不少人,因为spark官方并没有将自适应执行计划合并到主分支。目前来看,自适应正式引入应该是在spark 3.0的预发布版本,但是这个spark 3.0的两个预发布版本浪尖亲测自适应执行计划问题比较多,而且参数不全。可用的版本是2020.5月的master分支,编译之后的3.1.0-SNAPSHOT版本。
Spark 原有的DAG策略是静态生成的,一旦代码编译好,DAG策略就不会变了。Spark Adative自适应查询计划是动态的根据exchange划分查询stage,并且根据前面stage物化的统计数据优化后续查询stage的执行策略,进而提示性能。
算是增加了代价计算和查询stage根据计算的cost动态生成的策略。
应用场景,可以从百度提交的spark 自适应执行引擎,给出的测试案例总结以下三点:
1. sortMergeJoin转化为BroadcastHashJoin
该策略在BI场景下比较实用,因为一条查询中出现的join比较多,而且往往会有各种子查询和filter操作。将SortMergeJoin转化为BroadcastHashJoin,据测试说可以提升50%-200%的性能。
下图就是一个将SortMergeJoin转化为BroadCastJoin优化作用场景,经过一轮sortMergejoin之后,再进行join时,一侧的数据只有46.9KB,所以这种场景下使用自适应查询计划比较划算,将小表转化为broadcast,然后在executor进行本地的hashjoin
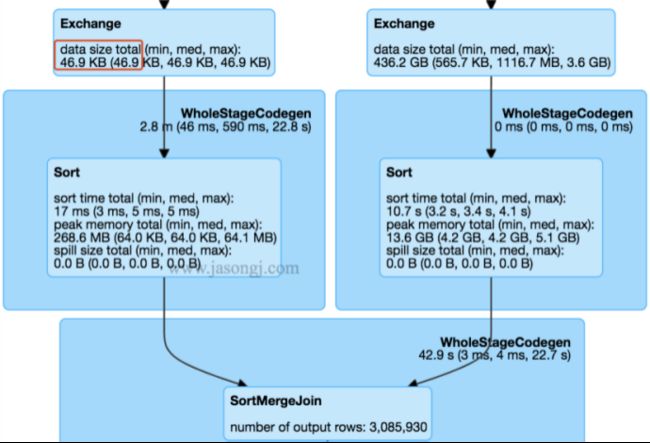
2. Spark长任务或者将Spark以服务的方式运行
长任务定义是任务执行超过一个小时。以spark作为服务,企业中的应用场景也比较多,比如使用spark-shell或者spark-sql客户端,使用thriftserver,或者使用zeppelin,livy或者百度的BigSql服务。
这些场景下,所有的spark job都共享相同的分区数,但是task有大有小,会使得小任务产生很多小文件,假设开启了spark 自适应执行计划及配置一些task信息,比如数据大小,行数,最大或者最小分区数等,可以带来50%-100%的性能提升。
3. GraphFrame任务
最后一种情况是应用程序使用GraphFrame,在这种情况下,假设用户拥有一个二维图,具有10亿条边,在GraphFrame中使用求连通性的算法。启用spark 自适应执行计划后,应用程序的持续时间从58分钟减少到32分钟,将性能提高了近100%。
2.Spark 3.1 版本实现逻辑
自适应查询计划在spark 源码中的类是AdaptiveSparkPlanExec。
AdaptiveSparkPlanExec是自适应执行查询计划的根节点。AdaptiveSparkPlanExec会按照Exchange节点将查询计划分成不同的stages,然后按照依赖的顺序执行这些stages。查询stage会在其完成的时候物化。当一个stage结束,根据其物化输出的统计信息,优化查询语法树的剩余部分。
Stage动态划分的逻辑也很简单。为了划分stage,spark会从下至上遍历查询语法树。当遇到exchange节点 同时如果该exchange节点的所有子查询stage都已经物化,spark会为该exchange节点创建一个新的query stage。一旦创建了新的查询stage,提交执行,异步物化。
当一个查询stage完成物化输出,剩余的query查询就会重新优化和根据最新的所有已经完成的stage的统计信息重新设计执行计划。也即是会重新遍历query语法树,在可能的情况下创建新的stage。
3.Spark 3.1 自适应引擎的配置
Spark 目前的master分支关于自适应执行计划的参数是最全的,3.0.0的预发布版本都不全。下面是浪尖整理的关于Spark 3.1版本的关于自适应执行计划的参数及其解释。
1.开启自适应查询引擎
spark.sql.adaptive.enabled
默认值是false。设置为true的话,就是开启了Spark SQL自适应查询引擎。所谓自适应查询引擎,实际上就是在运行时,通过一些统计指标来动态优化Spark sql的执行计划。
2.强制开启自适应查询引擎
spark.sql.adaptive.forceApply
默认值是false。当query查询中没有子查询和Exchange的时候,不会使用自适应执行计划的。所以,为了使用自适应执行计划,除了开启enabled配置外,还要配置该参数为true。
3.查询引擎开启时日志等级
spark.sql.adaptive.logLevel
默认是debug。可选"TRACE", "DEBUG", "INFO", "WARN", "ERROR"。含义是使用自适应查询计划,计划变化之后自适应引擎打的日志等级。
4.分区大小控制
spark.sql.adaptive.advisoryPartitionSizeInBytes
默认值64MB。这个参数控制着开启自适应执行优化之后每个分区的大小。在两种情况下,有用:
合并小分区。
分割倾斜的分区。
5.开启合并shuffle分区
spark.sql.adaptive.coalescePartitions.enabled
默认值是true。根据spark.sql.adaptive.advisoryPartitionSizeInBytes参数设置的分区大小,合并连续的shuffle分区,避免产生过多小task。
6.分区合并后的最小值
spark.sql.adaptive.coalescePartitions.minPartitionNum
默认值是大家熟悉的spark的默认defaultParallelism。不保证合并后的shuffle分区数一定比这个参数设置的值小,是一个推荐值。
7.分区合并的初始值
spark.sql.adaptive.coalescePartitions.initialPartitionNum
默认值是spark.sql.shuffle.partitions 。合并之前shuffle分区数的初始值。
8.是否以批量形式拉取block数据
spark.sql.adaptive.fetchShuffleBlocksInBatch
默认值是true。当获取连续的shuffle分区的时候,对于同一个map的shuffle block可以批量获取,而不是一个接一个的获取,来提升io提升性能。但是要明白,一个map shuffle输出一般对于一个reduce只有个block块,那么这种情况要发生只会发生在自适应执行计划开启,且开启了自适应合并shuffle分区功能。
9.开启本地shufflereader
spark.sql.adaptive.localShuffleReader.enabled
默认值是true。开启自适应执行计划后,该值设为true,spark会使用本地的shuffle reader去读取shuffle数据,这种情况只会发生在没有shuffle重分区的情况。比如,sort-merge join转化为了broadcast-hash join。
10.数据倾斜自动处理
spark.sql.adaptive.skewJoin.enabled
默认值是true。在自适应执行计划开启后,该值为true,spark会动态的处理 sort-merge join的数据倾斜,处理的方式是分区分割,或者分区复制。
11.分区倾斜比例因子
spark.sql.adaptive.skewJoin.skewedPartitionFactor
默认值是10.假如一个分区数据条数大于了所有分区数据的条数中位数乘以该因子,同时该分区以bytes为单位的大小也大于spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes,则视为分区数据倾斜了。
12.分区倾斜bytes阈值
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes
默认值是256MB,该分区以bytes为单位的值大于该值,同时分区数据条数大于了所有分区数据的条数中位数乘以spark.sql.adaptive.skewJoin.skewedPartitionFactor因子,则视为分区数据倾斜了。
13.非空分区因子
spark.sql.adaptive.nonEmptyPartitionRatioForBroadcastJoin
默认值是0.2 。假如参与join的非空分区占比小于该比例,那么该表不会被作为broadcast表去使用,不将表的数据量作为比较依据。但是join的另一张表依然可以用来作为广播表。
从配置中可以看出,自适应执行计划针对以下几个场景:
SortMergeJoin转化为BroadcastHashJoin。
分区合并。适合shuffle之后小分区特多场景
小分区数据倾斜的解决。
4. Spark 3.1案例
首先将Spark 源码clone下来,master分支版本就是3.1.0-SNAPSHOT,然后将Spark 源码install到你本地maven的.m2目录下,就可以直接在你工程里引入3.1.0-SNAPSHOT版本的Spark 依赖了。
mvn clean install -DskipTests
整个过程看你的网速和电脑性能了,几十分钟到若干小时吧。
主要引入的依赖有以下几个:
org.scala-lang scala-library ${scala.version} org.apache.spark spark-core_2.12 ${spark.version} org.apache.spark spark-sql_2.12 ${spark.version} org.apache.spark spark-unsafe_2.12 ${spark.version} org.apache.spark spark-tags_2.12 ${spark.version} org.apache.spark spark-catalyst_2.12 ${spark.version} org.apache.spark spark-hive_2.12 ${spark.version}
假如你maven install成功之后版本就是3.1.0-SNAPSHOT。也可以直接关注公众号,输入 3.1 获得浪尖编译的jar,直接可以加到测试的工程里。
环境要求比较简单 :java版本要求 1.8,scala版本 2.12.10.
首先准备数据集:
val sparkConf = new SparkConf()sparkConf.setMaster("local[*]")// sparkConf.set("spark.default.parallelism","4")sparkConf.set("spark.sql.shuffle.partitions","4")
sparkConf.setAppName(this.getClass.getCanonicalName)val spark = SparkSession .builder() .appName(this.getClass.getCanonicalName) .config(sparkConf)
.getOrCreate()
def createTable(spark:SparkSession): Unit ={
import spark.implicits._ val testData = spark.sparkContext.parallelize( (1 to 100).map(i => TestData(i, i.toString))).toDF()
testData.createOrReplaceTempView("testData") val testData2 = spark.sparkContext.parallelize( TestData2(1, 1) :: TestData2(1, 2) :: TestData2(2, 1) :: TestData2(2, 2) :: TestData2(3, 1) :: TestData2(3, 2) :: Nil, 2).toDF() testData2.createOrReplaceTempView("testData2")}
下面就是将SortMergeJoin转化为BroadcastHashJoin的案例。
def changeMerge2Broadcast(spark:SparkSession): Unit ={ val query = "SELECT * FROM testData join testData2 ON testData.key = testData2.a where value = '1'"
spark.sql(query).explain() val conf = SQLConf.get conf.setConfString(SQLConf.ADAPTIVE_EXECUTION_ENABLED.key,"true") conf.setConfString(SQLConf.ADAPTIVE_EXECUTION_FORCE_APPLY.key,"true") conf.setConfString(SQLConf.AUTO_BROADCASTJOIN_THRESHOLD.key , "80") conf.setConfString(SQLConf.ADAPTIVE_EXECUTION_LOG_LEVEL.key,"ERROR") val df2 = spark.sql(query)
df2.collect()}
首先是配置没有变更之前的执行计划输出为:

为了查看Spark 将执行计划由SortMergeJoin转化为BroadCastHashJoin的过程,可以将SparkConf配置中的日志等级设置为ERROR,默认debug。然后就可以直接通过log查看转化过程:
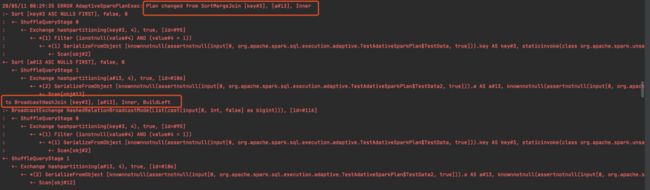
5. 总结
其实,别看代码少,本地做这个案例需要的知识点还比较多的。
乍一看,肯定看不出来什么门道的,案例代码少只需要几个配置,但是这属于细思极恐的案例。
问题一:
浪尖在创建SparkSession的时候特意指定了Spark SQL的shuffle分区为4。
sparkConf.set("spark.sql.shuffle.partitions","4")
请问这是为什么?
问题二:
采用下面的df创建表,跑一下案例,看看会有什么效果。
importspark.implicits._(1 to 100).map(i => TestData(i, i.toString)).toDF()Seq(TestData2(1, 1) , TestData2(1, 2), TestData2(2, 1) , TestData2(2, 2) , TestData2(3, 1), TestData2(3, 2)).toDF()
答案自己测测,或者多读读配置就好了。
推荐阅读:
戳破 | hive on spark 调优点
Hadoop YARN:调度性能优化实践
干货 | 实践Hadoop MapReduce 任务的性能翻倍之路
