spark通过textFile读取hdfs数据分区数量规则
作者:越走越远的风
链接:https://www.jianshu.com/p/e33671341f0d
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
话不多说,直接上代码
val conf = new SparkConf().setAppName("ScalaWordCount").setMaster("local[*]")
val sc = new SparkContext(conf);
val rdd = sc.textFile("E:\\fandf\\testData\\partition")
rdd.collect()
sc.stop()
首先是不指定分区数量,查看textFile源码

查看defaultMinPartitions方法,defaultParallelism默认为电脑核数,我这里是8,因此defaultMinPartitions为2

然后来看hadoopfile方法,返回了一个hadoopRDD,将minPartitions返回
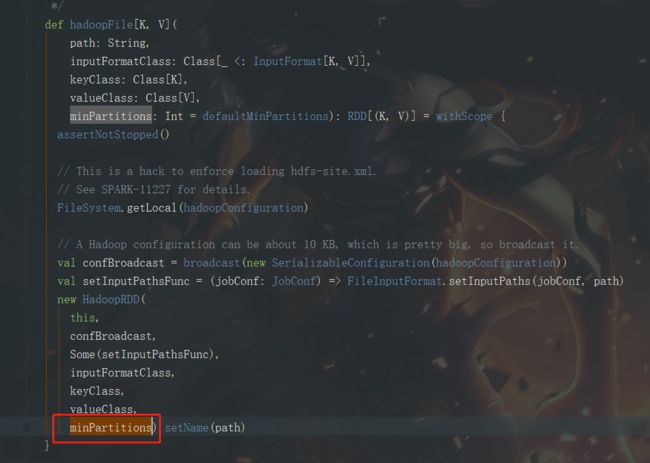
在实现rdd.collect()时,会触发action,hadoopRDD会调用方法getPartitions来决定分区数量(getPartitions为RDD.scala类定义的抽象方法,每一个具体的RDD都是继承RDD重写getPartitions方法,来根据自己的规则决定分区数量)

此时可以看到minPartitions为2,继续跟踪源码,查看inputFormat的getSplits方法

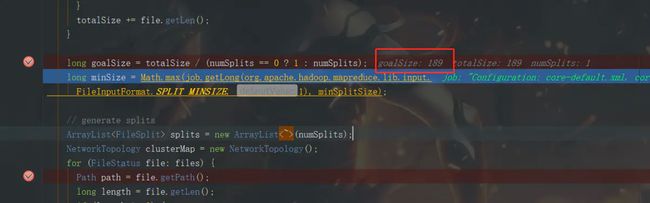
这里的totalSize为189,是我sc.textFile("E:\\fandf\\testData\\partition")指定目录下的所有文件字节的和

goalSize = 189/2 = 94,这里的goalSize为切片大小,下面开始依次处理文件

首先是a.txt文件,文件长度为17个字节,blockSize我自己设置为32M,查看computeSplitSize方法

则这里splitSize的值为17
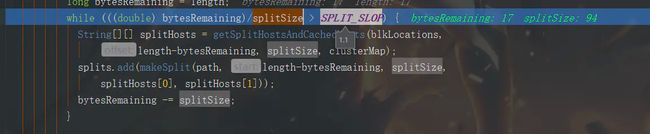
查看该方法,说明在切片大小的1.1倍以内的文件都不会切分,这里不会切分,b.txt大小为7个字节,和a.txt一样,我们直接跳过,看c.txt文件
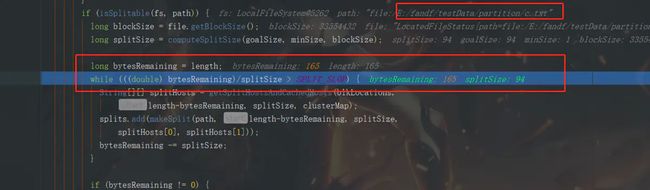
c文件长度为165字节,这里要走下面的while循环逻辑了

这里将c文件切分成了两个文件,165-94=71,切分剩下的第二个文件不满足while循环,进入下面的分支
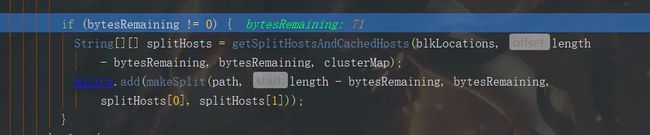
然后我们来看看最终切分数量

最终切分成了四个分区,第三个文件通过偏移量被切分成了两个
好了,接下来我们测试下指定最小分区数量,对代码做如下修改
val rdd = sc.textFile("E:\\fandf\\testData\\partition", 1)
那么最小分区数量为1,goalSize则为totalSize,因此有几个文件,就有几个分区
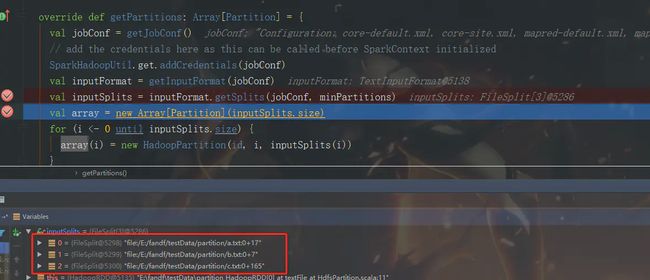
如果指定最小分区数量是四呢?
我们可以推测一下,文件总大小是189字节,189/4=47,则a,b文件会生成两个分区,c文件大小为165,会被切分成偏移量为0+47,47+47,94+47,141+24四个分区,我们看下运行结果
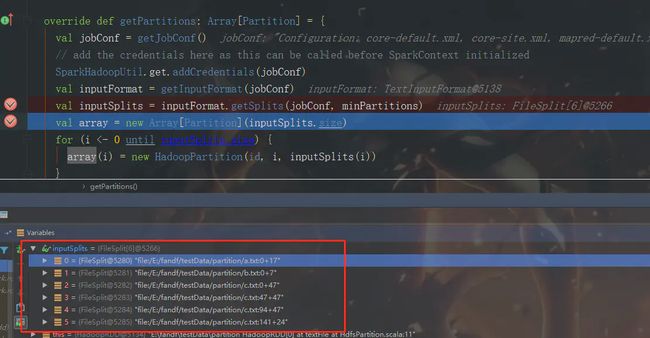
果然是生成了2+4,6个分区。
接下来总结一下分区数量规则:
1.如果textFile指定分区数量为0或者1的话,defaultMinPartitions值为1,则有多少个文件,就会有多少个分区。
2.如果不指定默认分区数量,则默认分区数量为2,则会根据所有文件字节大小totalSize除以分区数量partitons的值goalSize,然后比较goalSize和hdfs指定分块大小(这里是32M)作比较,以较小的最为goalSize作为切分大小,对每个文件进行切分,若文件大于大于goalSize,则会生成该文件大小/goalSize + 1个分区。
3.如果指定分区数量大于等于2,则默认分区数量为指定值,生成分区数量规则同2中的规则。
思考一下,为什么要这样子分区呢?
我的理解是,可能有的文件很小,有的文件很大,这样处理的话,能尽量使每个分区中的文件大小均匀一点。
作者:越走越远的风
链接:https://www.jianshu.com/p/e33671341f0d
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。