腾讯Deep CNNS卷积加速架构
[转载]深度卷积网络大提速及其问题
已有 4882 次阅读 2015-1-21 08:53 |个人分类:人工智能|系统分类:观点评述|文章来源:转载
Geoffrey Hinton的努力,使得深度学习(Deep Learning,DL)成为实现机器智能的核心技术。然而,深度学习的一些坑,如大型神经网络的计算负载、训练性能,并不那么容易克服。现在,深度学习的爱好者可以通过Facebook的福利消除这一障碍:日前,Facebook人工智能研究院(FAIR)宣布开源了一组深度学习软件库,是针对Torch机器学习框架的插件,基于NVIDIA的GPU,大大提升了神经网络的性能,可以用于计算机视觉和自然语言处理(NLP)等场景。
那么,具体而言,Facebook开源深度学习软件库有哪些内容?它会是谁的菜?它能做什么?我们应当如何利用它?
开源代码&工具
-
Torch
-
iTorch
-
fbcunn
-
fbnn
-
fbcuda
-
fblualib
谁能受益
根据Facebook的说法,如果您想训练用于图像识别、自然语言处理或其他应用程序的大规模的深度学习系统(特别是卷积网络),fbcunn会很有帮助。如果您已经是一个Torch用户,效果更佳——我们知道,Torch作为一个协助机器学习技术开发的开源环境,一直以来是很多人工智能项目的核心,不管是在学校研究或者是类似 Google、Twitter 和Intel这样的公司,都采用这一框架。
开源之后,深度学习生态链上可以有更多的玩家。FAIR研究员、软件工程师Soumith Chintala表示,开源的AI工具能够帮助研究实验室和新兴创业公司免去了从零开始研究的复杂道路,把更多的精力和时间都投入到改善现有的算法中,同时开源的AI工具也将成为Facebook和创业团队之间的催化剂。
能做什么
Facebook表示,其开源优化的深学习模块,加快了基于Torch的深度学习项目的运行速度,允许我们在更短的时间训练规模更大的神经网络加快我们的研究项目。
开源的包括用于大型卷积网(ConvNets)的GPU优化模块,以及那些在自然语言处理领域常用的网络。Facebook的ConvNets模块包括一个快速的基于FFT的卷积层,采用基于NVIDIA的cuFFT库构建的自定义CUDA内核。
除此之外,还包括许多其他基于CUDA的模块和容器(container)。
基于FFT的卷积层
本次发布的最重要部分包括基于FFT的卷积层代码,因为在训练ConvNets中卷曲占用了大部分的计算时间。由于提高这些模型的训练时间转化为更快的研发,Facebook已经花了相当大的工程努力提高GPU卷积层。这项工作成效显着,达到目前公布的最快代码的23.5倍。
上面的热力图可视化地显示了采用Facebook的ConvolutionFFT相对于采用NVIDIA的CuDNN完成一个训练的相对速度,红色代表Facebook慢,绿色代表Facebook更快,颜色增强代表加速的幅度。
对于小尺寸的内核(3×3),增速适中,最高速度比CuDNN快1.84倍。
对于较大尺寸的内核,从(5×5)开始,增速相当可观。
更大尺寸的内核(13x13),最高速度为比CuDNN快23.5倍。(更多的技术细节,请您阅读Facebook的Arxiv论文。)
多GPU之上的并行化
从工程方面,Facebook一直努力实现在多GPU上并行训练神经网络模型的能力。Facebook致力于最小化并行的开销,同时也使研究人员极易使用,通过数据并行和模型并行模块(fbcunn的一部分)。当研究人员把它们的模型推到这些易于使用的容器,代码自动调度模型在多个GPU上最大化加速。Facebook使用多GPU在Imagenet上训练一个ConvNet的一个例子已经展示了这一点。
fbcunn是什么
这个库包含Facebook用于GPU的高度工程化深度学习模块,以加快深度学习的速度。它插入到Torch7的框架之中,通过luarocks无缝安装,并且与Torch的NN封装完全兼容。
总体来说,Facebook发布了用于Convnets和一般神经网络的快速NN模块:
-
快速空间卷积模块,使用FFT加速卷积。
-
快速Temporal卷积,速度相比Torch的cunn实现快1.5倍至10倍。
-
nn.DataParallel和nn.ModelParallel容器。将您的模型插入,在多个GPU上加速效果立竿见影。
-
采用FFT/ IFFT为NN模块。
-
用于神经语言模块(Neural Language Models)和文字嵌入的快速LookupTable。比在Torch/ NN下快很多。
-
Hierarchical SoftMax模块,使得现在分类百万类成为实际可行的策略。
-
特征映射上的LP和Max Pooling (用于MaxOut)。
-
更多的好东西。
示例:
-
在Torch-7中使用多GPU训练基于分类的imagenet(展示FFT卷积以及ModelParallel容器)
fbcunn如何使用
-
DataParallel和ModelParallel这两个模块超级简单易用。这个unit-test同时作为例子和测试。examples/imagenet下面还有ModelParallel的例子。
m = nn.DataParallel():add(nn.SpatialConvolution(...)):add(nn.ReLU())-- see, so simple
-
卷积模块更加简单易用。它们与NN的API完全兼容。
CONV= nn.SpatialConvolutionCuFFT(...)-- fast spatial convolutions!
CONV= nn.TemporalConvolutionFB(...)-- fast temporal convolutions!
-
LookupTable和Hierarchical SoftMax分别被命名为nn.LookupTableGPU和nn.HSM,也是超级简单易用。它们的使用,以及fbcunn的安装步骤、API文档等更多的细节,您都可以在这个链接的完整的文档和规范中找到答案:http://facebook.github.io/fbcunn/fbcunn/。
编后语
极客们说,人工智能是世界的未来,深度学习算法是让机器拥有智能的最佳途径。我们看到,从的相册处理到无人驾驶汽车,深度学习的模型已经在逐步应用。尽管目前的技术成果距离S.W.Hawking和Elon Musk所担忧的“机器政变”还非常遥远,但在硬件加速技术的支撑和开源社区的贡献之下,深度学习算法的普及应用门槛确实大大降低,模式识别、NLP变得更加简单,我们没有理由不加以学习和利用。
深度卷积神经网络CNNs的多GPU并行框架及其应用
【编者按】深度卷积神经网络有着广泛的应用场景,本文对深度卷积神经网络Deep CNNs的多GPU模型并行和数据并行框架做了详细的分享,通过多个Worker Group实现了数据并行,同一Worker Group内多个Worker实现模型并行。框架中实现了三阶段并行流水线掩盖I/O、CPU处理时间;设计并实现了模型并行引擎,提升了模型并行计算执行效率;通过Transfer Layer解决了数据存储访问效率问题。此框架显著提升了深度卷积神经网络训练速度,解决了当前硬件条件下训练大模型的难题。
以下为原文:
将深度卷积神经网络(Convolutional Neural Networks, 简称CNNs)用于图像识别在研究领域吸引着越来越多目光。由于卷积神经网络结构非常适合模型并行的训练,因此以模型并行+数据并行的方式来加速Deep CNNs训练,可预期取得较大收获。Deep CNNs的单机多GPU模型并行和数据并行框架是腾讯深度学习平台的一部分,腾讯深度学习平台技术团队实现了模型并行和数据并行技术加速Deep CNNs训练,证实模型拆分对减少单GPU上显存占用有效,并且在加速比指标上得到显著收益,同时可以以较快速度训练更大的深度卷积神经网络,提升模型准确率。
1.CNNs模型并行导论1.1.典型应用分析:图像识别
图像识别是深度卷积神经网络获得成功的一个典型应用范例。图1揭示了一个具有5个卷积层和3个全连接层的深度卷积神经网络,该模型可应用于图像分类。
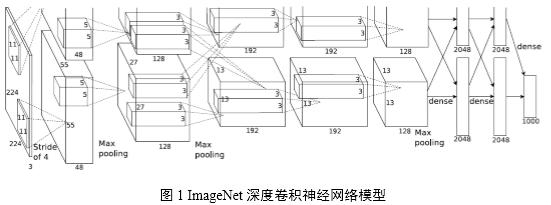
使用GPU训练深度卷积神经网络可取得良好的效果[1][2],自2012年使用Deep CNNs模型在ImageNet图像分类挑战中取得突破性成绩,2013年的最佳分类结果也是由Deep CNNs模型取得。基于此,腾讯深度学习平台技术团队期望引入Deep CNNs来解决或优化图像分类问题和图像特征提取问题,以提升在相应用例场景中的效果。
1.2.现有系统的问题
在将CNN应用于图像相关领域的算法研究以及CNN训练平台搭建的实践过程中,受限于单个GPU上的显存大小(例如:服务器采购的显卡Tesla K20c可用显存为4.8GB,ImageNet 2012论文[1]中用到的网络占用显存大约3.9GB),在尝试调整参数和网络规模的实验中,往往难以存储下更大规模的深度卷积神经网络模型,使得包含较多参数的网络不能在单GPU上训练,需要通过多GPU模型并行技术,拆分模型到多个GPU上存储和训练来解决。
随着训练数据集扩充、模型复杂度增加,即使采用GPU加速,在实验过程中也存在着严重的性能不足,往往需要十余天时间才能达到模型的收敛,不能满足对于训练大规模网络、开展更多试验的需求
考虑到上述问题,在腾讯深度学习平台的Deep CNNs多GPU并行训练框架中,通过设计模型拆分方法、模型并行执行引擎和优化访存性能的Transfer Layer,并吸收在数据并行方面设计经验,实现了多GPU加速的模型并行和数据并行版本。
本文描述多GPU加速深度卷积神经网络训练系统的模型并行和数据并行实现方法及其性能优化,依托多GPU的强大协同并行计算能力,结合目标Deep CNNs模型在训练中的并行特点,实现快速高效的深度卷积神经网络训练。
1.3.框架设计目标
多GPU模型并行+数据并行期望达到下述目标:充分利用Deep CNNs模型的可并行特点,结合SGD(Stochastic Gradient Descent,随机梯度下降)训练的数据并行特性,加速模型训练过程;突破显存大小限制,使得训练超过单GPU显存的模型成为可能,并预期通过训练更复杂的网络来获得更好的模型效果。
上述目标完成后,系统可以更快地训练图1中目标Deep CNNs模型。模型拆分到不同GPU上可减少对单GPU显存占用,适用于训练更深层次、更多参数的卷积神经网络。
1.4.挑战
在图像识别应用中,深度卷积神经网络模型的卷积层计算量大,全连接层参数多。因此,如何划分计算资源,通过模型并行和数据并行两个数据/计算组织层次上来加速训练是框架设计首要解决的问题。
图像作为输入数据,其数据量庞大,且需要预处理过程,因此在Batch训练时磁盘I/O、数据预处理工作也要消耗一定时间。经典的用计算时间掩盖I/O时间的方法是引入流水线,因此如何设计一套有效的流水线方法来掩盖I/O时间和CPU处理时间,以使得整体耗时只取决于实际GPU训练时间,是一个重要问题。
模型并行是将一个完整Deep CNNs网络的计算拆分到多个GPU上来执行而采取的并行手段,结合并行资源对模型各并行部分进行合理调度以达到模型并行加速效果是实现模型并行的关键步骤。
多GPU系统通过UVA(Unified Virtual Address,统一虚拟地址)技术,允许一颗GPU在kernel计算时访问其他GPU的设备内存(即显存),但由于远程设备存储访问速度远远低于本地存储访问速度,实际性能不佳。因此在跨GPU的邻接层数据访问时,需要关注如何高效利用设备间数据拷贝,使所有计算数据本地化。
2.系统概述
如何模型并行?
模型并行是:适当拆分模型到不同的计算单元上利用任务可并行性达到整个模型在计算过程中并行化效果。
如图2所示,揭示了从单GPU训练到多GPU模型并行训练的相异之处,主要在于:在使用单GPU训练的场景下,模型不进行拆分,GPU显存上存储整个模型;模型并行的场景下,将模型拆分到多个GPU上存储,因此在训练过程中每个GPU上实际只负责训练模型的一部分,通过执行引擎的调度在一个WorkerGroup内完成对整个模型的训练。
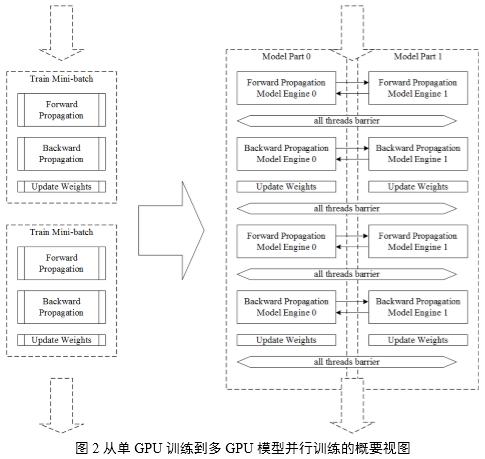
多GPU并行系统从功能上划分为用于读取和分发数据的Training Data Dispatcher和用于做模型并行训练的GPU Worker,如图3所示。训练数据从磁盘文件读取到CPU主存再拷贝到GPU显存,故此设计在各Worker计算每batch数据时,由Training Data Dispatcher从文件中读取并分发下一batch数据,以达到用计算时间掩盖I/O时间的设计目标。
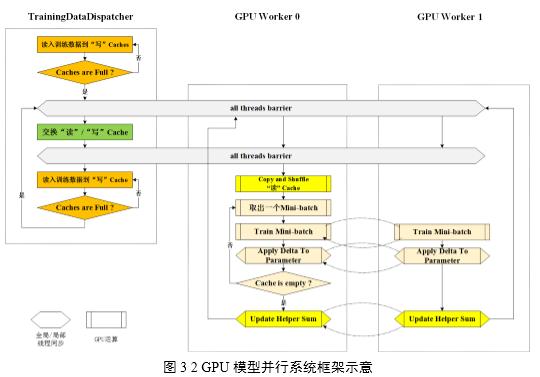
3.训练数据处理的并行加速
基于mini-batch的训练,现有技术方案在训练深度卷积神经网络时,每次从数据文件中读入和处理1个batch数据,在GPU计算某一batch时由CPU预读取和预处理下一batch。但是随着训练集图片像素数增大,读取和处理时间随之增加,由于采用多GPU技术加速了单个batch计算时间,数据处理的性能问题随之而来,需要减少数据处理的用时,以使最终加速效果取决于计算用时。
如图4所示,总体看来,在深度卷积神经网络训练过程中始终是在执行一条三阶段并行的流水线:计算本次batch数据——处理下次batch数据——读入再下次batch数据。

4.GPU Worker: 模型并行的承载体
数据并行以划分Worker Group为基本组织形式,模型并行以在Worker Group内划分Worker为基本组织形式,并行训练的调度资源来源于CPU线程,计算资源来源于GPU卡。由于GPU卡通常意义上被看成是一种加速卡或协处理器卡,必须在基于CPU的主机上下文中被调用来做计算,因此遵循1个CPU线程绑定1张GPU卡能够发挥多GPU共同参与计算时的并行性效能。

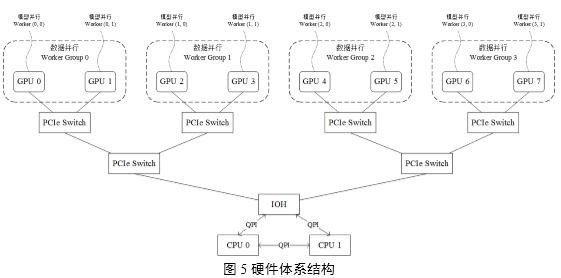
在实际生产环境中,安装多GPU服务器的硬件体系结构如图5所示,示例中揭示了一个8 GPU节点服务器的硬件配置,每两个GPU Slot连接在一个GPU专用PCI槽位上再通过PCIe Switch将GPU Slot 0,1,2,3连接在一颗CPU上,GPU Slot 4,5,6,7连接在另一颗CPU上,两颗CPU通过IOH(Input Output Hub)连接。
5.CNNs网络的模型划分5.1.基本模型划分方法
模型并行的来源是Deep CNNs网络只在特定层(如输入层、全连接层)与其他层有全面的连接,而其他较为独立的直线连接关系即可作为模型的可并行部分。将模型的可并行部分拆分到多个GPU上,同时利用多个GPU的计算能力各执行子模型的计算,可以大大加快模型的单次前向-后向训练时间。

DeepCNNs网络的层次模型实际上是一张有向无环图(DAG图),分配到每个模型并行Worker上的层集合,是有向无环图的拓扑排序子集,所有子集组成整个网络的1组模型。
5.2“十字形”模型划分方法
考虑极端情景:需要训练超大规模Deep CNNs模型,或者使用计算能力相对较强、显存较小(一般在1GB~3GB)的桌面级GeForce系列GPU,则利用模型本身的并行性这种基本的模型划分方法将不再适用。需要将模型再做拆分以保证单个GPU都能存储下对应的子模型。
如图7所示,描述了将模型按“十字形”划分到4 Worker上训练的情景,不仅拆分了模型的可并行部分,也虽然这样的划分在Worker 0和Worker2之间,Worker 1和Worker 3之间达到并行加速效果,却能使得整个模型得以存储在4 GPU上。这种模型划分方法能够适用于训练超大规模网络等特殊模型的需求。

6.CNNs网络的模型并行工作引擎
每个模型并行Worker上以一个模型并行执行引擎负责调度本Worker上子模型的执行过程。执行引擎控制所有Worker上的子模型完成前向和后向计算,各自对子模型完成参数更新后,到达主线程同步点,开始下一mini-batch训练。
多GPU模型并行和数据并行的Deep CNNs模型replicas及划分结构如图8所示,在使用4 GPU的场景下,划分了2组Worker Group用于数据并行;每个Worker Group内划分2个Worker用于模型并行。

7.在图像识别上的应用7.1.模型训练实验性能
实验环境为一台搭载8核心Intel(R) Xeon(R) CPUE5-2640 v2 @ 2.00GHz的服务器,内存为48GB,服务器安装了4块NVIDIATesla K20c GPU,单GPU显存大小为4.8GB。
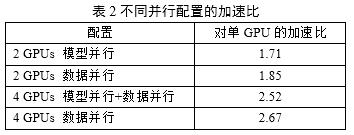
训练同样的Deep CNNs模型,相比于单GPU,使用多GPU结合不同并行模式的加速效果如下表所示:
7.2.模型收敛性
对于目标Deep CNNs模型,在单GPU训练时(对照实验)显存占用量为3.99GB;使用2 GPU模型并行训练时单个GPU上显存占用量为2.15GB,并且在训练相同迭代时训练集、测试集错误率效果都与对照实验完全相同;抽样比照参数一致性,被抽样的参数(同对照实验相比)也都是一样。
尝试更改Deep CNNs模型,训练一个更大的网络,增加滤波器数目,减小步长,增加中间卷积层feature map数目,训练时所需显存将达到9GB以上,使用单个Tesla K20c GPU(4.8GB显存)无法开展训练实验;而多GPU模型并行训练实验中该模型的错误率对比图1模型降低2%。
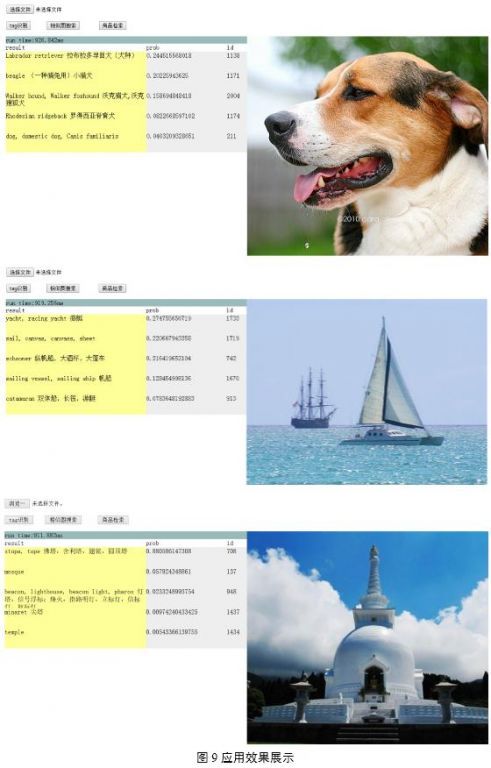
7.3.效果展示
图9为图像标签识别的示例,通过对两千多类物体的图像进行训练,可实现对常见物体的自动识别。
8.结论与展望
本文描述了深度卷积神经网络Deep CNNs的多GPU模型并行和数据并行框架,通过多个Worker Group实现了数据并行,同一Worker Group内多个Worker实现模型并行。框架中实现了三阶段并行流水线掩盖I/O、CPU处理时间;设计并实现了模型并行引擎,提升了模型并行计算执行效率;通过Transfer Layer解决了数据存储访问效率问题。此框架显著提升了深度卷积神经网络训练速度,解决了当前硬件条件下训练大模型的难题。
深度卷积神经网络有着广泛的应用场景:在图像应用方面,Deep CNNs可应用于相似图片检索、图片的自动标注和人脸识别等。在广告图片特征提取方面,考虑Deep CNNs能够很好地学习到图像特征,我们尝试将其用于广告点击率预估(Click-Through Rate Prediction, pCTR)模型中。
原文链接: 深度卷积神经网络CNNs的多GPU并行框架及其在图像识别的应用 (责编魏伟)
引自:http://yuedu.163.com/news_reader/#/~/source?id=426f1ed9-b19b-44f5-bcad-9f58930fc65e_1&cid=2c4021a19c0046b39a55e5cd2141e495_1
新浪科技讯 北京时间1月17日午间消息,Facebook周五宣布开放部分深度学习技术的源代码,以此推进整个行业的发展以及这项技术的普及。
深度学习已经成为机器学习领域最热门的词汇之一。这项技术是在吉奥夫-辛顿(Geoff Hinton)的努力下普及开来的,他目前任职于谷歌,之前还曾在微软研究院工作。除此之外,Yann LeCun等计算机研究人员也都希望寻找更好的方式,帮助电脑学会识别物体和语音。
Facebook同样在这一领域开展了一些工作。该公司周五宣布,将对围绕Torch7机器学习计算架构开展的一些项目进行开源。Torch长期以来都是很多机器学习和人工智能项目的核心,不仅是学术界,就连谷歌、Twitter和英特尔等企业也都使用这一架构。
Facebook周五推出了一些优化工具,加快了基于Torch的深度学习项目的运行速度。其中一项允许开发者使用多个GPU平行训练他们的网络。另外一项改进则可以大幅加快“卷积神经网络”的训练速度,达到目前公布的最快代码的23倍。卷积神经网络是很多深度学习系统的核心所在。
另外,Facebook还额外推出了多款工具,为Torch的其他部分赋予更快的速度。其中部分比较温和,但Facebook很多项目的速度都比默认工具快了3至10倍。
不过,真正重要的在于,深度学习技术正逐步在我们日常使用的很多软件中发挥作用。
例如,Google+ Photos就使用这项技术帮助用户寻找自己图库中的照片。在上周的CES上,英伟达也在主题演讲中谈到了如何利用深度学习帮助车载摄像头对物体进行分类,从而推进无人驾驶汽车的研究。(书聿)
转载本文请联系原作者获取授权,同时请注明本文来自王小平科学网博客。
链接地址:http://blog.sciencenet.cn/blog-1225851-861388.html
上一篇:[转载]Hadoop 2.0 上深度学习的解决方案
下一篇:[转载]Yann LeCun有关深度卷积网络研究新进展
收藏分享