京东广告推荐机器学习系统实践
【转】http://bigdata.it168.com/a2016/0913/2915/000002915998.shtml
包勇军,2014年4月加入京东数字营销业务部,参与组建并带领模型团队,自主研发出京东大规模机器学习平台,同时还负责京东电商广告深度学习算法应用和优化的工作。
大家好,我是来自京东的包勇军,我今天分享的主题是《京东电商广告和推荐的机器学习系统实践》,介绍下我们部门在广告和推荐系统中应用机器学习算法的实践经验,包括浅层模型和深度学习算法的应用,正好也涵盖了我们这两年的工作。大纲如下:

介绍具体工作之前,先跟大家简单介绍一下我们部门的业务背景。我们是京东数据营销业务部,主要负责京东的广告、推荐以及站外引流。包括有京东主站PC端和移动端流量,站外ADX流量以及SEM流量。这些流量接入到我们的系统之后,经过商品和广告召回,再进行排序,基本所有的推荐系统或广告系统都是这样一个流程。
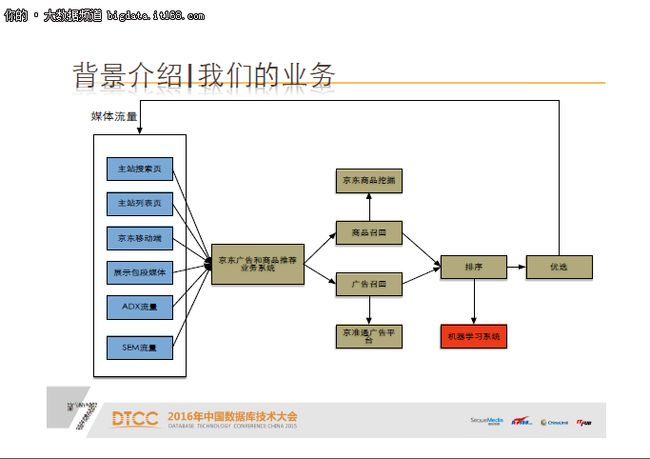
在这里需要解释下,今天讲的机器学习主要应用在排序阶段,主要内容就是机器学习在我们的排序算法中的应用实践。

我们系统的特点主要有两个,一是实时在线,二是广告和推荐的混合系统。这个系统不止是广告系统,也不止是推荐系统,而是两者的混合。它对外暴露有实时在线服务接口,目前处理的日请求达到200亿次。接下来我们先看看浅层模型时代的工作。
首先讲讲浅层模型时代机器学习系统的核心问题。

我总结下来核心问题总共有五个,分别是模型算法,日志流、训练系统、特征系统跟评估。浅层模型算法这块,相对来说研究的比较透彻,比较固定,我们的分享主要集中在实现层面。算法一般用的比较多的就是lr,因为广告和推荐系统的应用场景就是大规模稀疏性特征建模,所以lr比较适合。

由于浅层算法变化较少,所以算法的主要优化都集中在特征上。可能平时看到的以LR为主要算法的机器学习团队里,大部分人都在做人工的特征挖掘。算法层面,还有一些研究在自动学习组合特征的算法,比如Fm/ffm,gbdt+lr等,我们用的是FM。

FM的好处就是,可以通过因式分解减少数据稀疏性,从而有效学习特征组合。原来的模型特征组合可能是N方的规模。N个特征,N乘N就是N的平方,通过因式分解可以把每个特征表示成向量,特征组合通过特征向量的点积来完成,整个模型大小就变成了N×K,K是向量大小,但平时使用时要注意资源消耗问题,假如K是8,这个模型可能会膨胀8倍,所以不能单纯追求效果,要综合平衡收益和资源。

前面讲到浅层模型的主要优化方向是特征,那特征系统的主要问题是什么呢?最主要的经常遇到的就是线上线下特征一致性问题。这就是说,离线试验模型拿到的样本跟线上预估模型特征有很大diff。根据我们之前的经验,修复这个bug,速度涨了10%,京东广告部门的点击率也有了大幅度提升,所以说在业务指标上能带来数量级的提升。
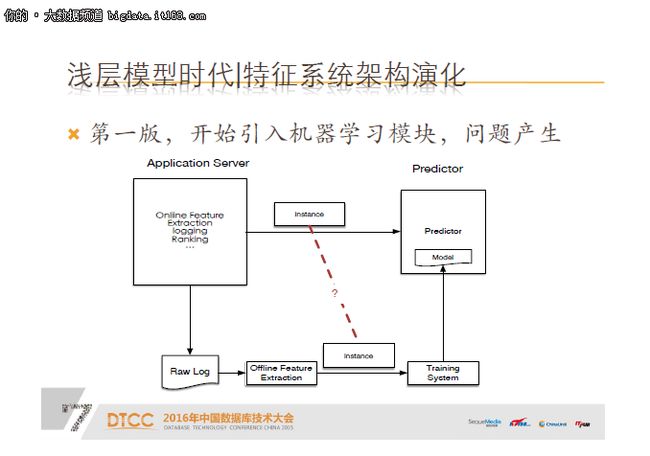
浅层模型时代的特征系统架构演化,通常来说,第一版的业务模块已经逐渐成熟,已经进入机器学习优化阶段。因为机器学习算法都是离线的,很自然的就会开发一个离线特征抽取模块,可以看到一个很明显的diff,也就是说离线跟在线是不同的代码,样本之间有很大不同。
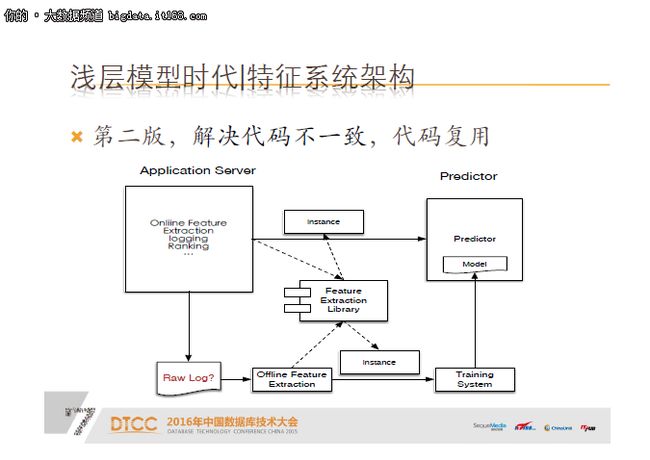
为了解决这个问题,我们可能会设计一个通用的library,线上线下同一份代码,虽然解决了代码不一致,但实际上问题并没有真正解决,离线拿到的训练数据是落下来的日志,这个日志和在线数据源实际是不同的,在线是从数据库或词典,经过一些复杂的业务逻辑处理,最终落下来的,两者之间实际上处理过程是不同的,所以线上跟线下数据源还是有很大不同的。
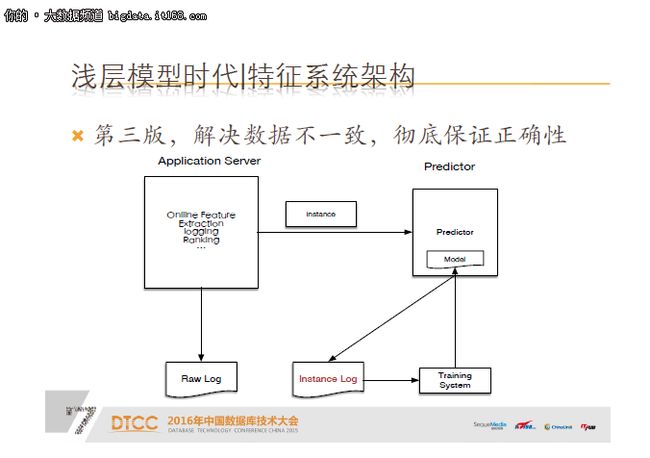
我们最终的解决方案是,把线上处理完的特征直接落下来给离线训练使用,彻底保证一致性。

这三种方案介绍完之后,各自的优缺点是什么呢?第一版是初级阶段的选择,不展开。其实,第二版方案之所以会存在,是因为第二版的开发迭代效率很高。因为策略调研都是是离线研究人员驱动,先有离线代码后有在线代码,特征优化可以回溯历史数据,周期短。至于第三种方案,加一个特征获取训练数据需要上线到生成环境,可能一个累计一个月的时间,才能把数据补充完整,然后进行训练模型,时间成本会很高。尽管有这样的问题,但从我们历史上踩过的很多坑来看,我们还是建议采用第三种方案。用在线代码推动特征升级,对开发能力可能有一定要求,虽然牺牲了一些开发效率,但最终能够保证策略效果。

接下来,我们讲一下浅层模型时代的效果评估,评估大家经常遇到的问题就是评估结论不可信。比如,某一天,算法工程师说,我这个算法升级离线评估涨了很多,于是开始花费大量人力推动工程化上线的工作,但上线之后,确发现业务指标并没有涨,回头再看,发现离线的评估数据有问题,或者是评估工具出了问题。所以,我们最终提出的方案是用在线系统评估离线指标,解决线上实现和线下评估脱节的问题,一般来说,大部分团队可能对评估这块的规范化不是很重视,经常是一些离线的工具互相拷贝。
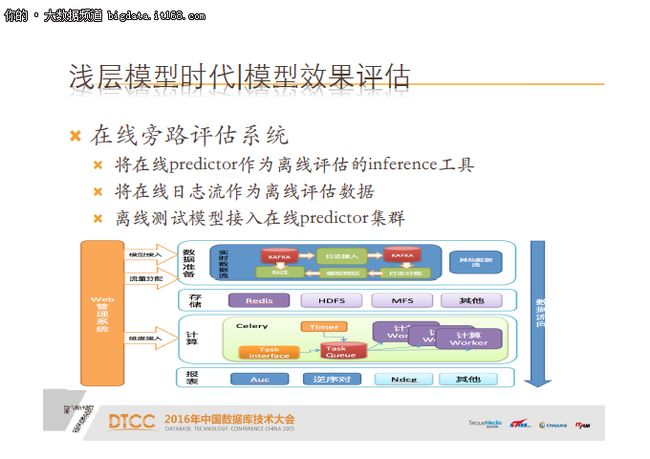
我们的方案叫在线旁路评估系统,第一将在线predictor服务直接作为离线inference工具,第二将在线日志流作为离线评估数据。离线测试模型接入在线predictor集群,经过各指标的计算,做一个报表呈现。引入该系统之后的架构图如下所示:
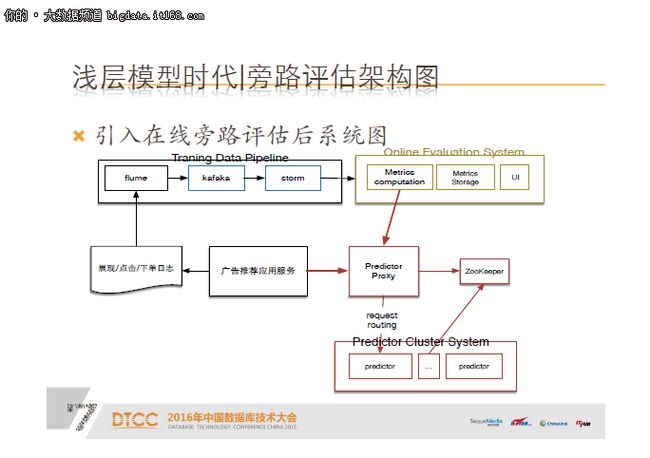
红线标注的地方可以看到,评估和在线应用服务都共用一个集群,precitor集群,在这之中我们加了proxy作为服务的接入接口,这个方案的收益如下所示:

最大的收益就是结论可比可信了,整个迭代效率得到了很大提升,避免了数据diff跟工具bug的干扰。所以,如果某个算法工程师说,现在他的算法效果很好,我们就可以把这个他的离线模型推到我们的评估平台上,我们可以自动给出所有评估指标,AUC或预估分布一目了然,然后跟基线做对比,好坏就很清楚了。这个旁路评估还解决了大家平时可能不太注意,经常会犯的问题,就是在线实时服务模型中的评估穿越问题。
我跟大家解释一下穿越问题,一般的模型评估大家通常是把数据拆分,比如分成10份,8份拿来做训练,一份做validation,另一份拿来做测试。然后我再看一下训练模型的测试效果,如果效果好,我认为泛化效果好,但在实时服务模型中,这种评估是有问题的,大家可以看下面的两张图:
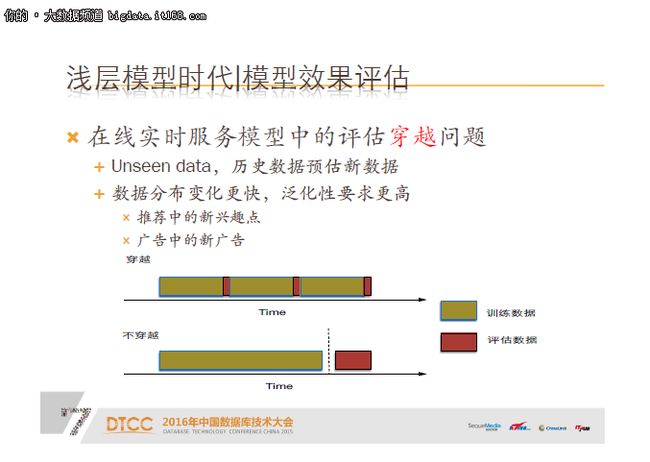
第一张图是穿越方式,第二张图是不穿越的方式。大家可以看到在时间维度上,不穿越是指在时间维度上,把训练数据跟评估数据完全切割开,原因是在线实时服务模型中,数据变化非常快,所以泛化性要求会更高。比如广告中的新广告,或者推荐中的新兴趣点,实际上是拿截止昨天的所有历史数据训练模型来预估今天的新数据,相当于拿历史数据预估新数据。假如是这种穿越的评估方式,实际上是拿历史数据预估历史数据。所以在线实时服务模型对泛化性要求更高,如果用穿越的方式评估,往往得到的数据会非常不靠谱,就会导致离线效果不错,上线之后效果很不好,这就是穿越问题。

讲完了评估,来看训练系统,这部分的相关论文比较多。总结一下,浅层模型训练系统的核心问题就是,大数据的效率问题。那这个问题怎么解决,我总结了如下几个方案:分别是采样,分布式训练,增量算法,Online learning算法。我们用的训练系统是VW,VW是微软的一个研发人员开源的分布式训练平台,我们对此进行了升级定制。另外业界目前研究比较多的是Online learning,它的好处在于时效性比较好,因为原来的假设实际上分布是静态的,Online learning的假设分布实际上是变化的,因为它是Online的方式,所以相当于state track。我们也在某些产品上线了nline learning算法。那问题是什么呢?问题是增加了系统复杂度,需要增加了实时计算系统,另外更新频繁,从架构层面来说,增加了和其他数据流系统的耦合。所以经常遇到的问题就是,某一天业务指标大跌,其他部门可能会找过来说,你这个模型的更新时间点是什么,你就会被动的卷入到这种很琐碎的查问题的事情中。而且,特征跟算法升级非常麻烦,原因是Online learning模型一直在更新,一旦特征算法升级之后,这种模型结构就会完全变掉,就要重新训练这个模型。

再讲讲多目标优化,刚才提到的这个系统实际上是广告和推荐的混合系统。在2014年,我们主要的优化方向是广告收入,就是eCpm=pCtr*bid,pCtr是通过机器学习进行点击率预估,到2015年我们的目标就变了。

我们的目标变成了广告收入加GMV,除了挣钱以外,我们很重视用户体验,也重视对公司贡献的整体价值。所以RankingFunction就变成了pCtr1*(a*pValue+b*pGmv),这个方案变成了三个模型,系统变得复杂了。多模型方案的问题实际上就是,分目标优化,策略升级不同步。比如pCtr优化以后,评估下来涨了1%,但由于模型跟模型之间不同步,所以上线之后,跟PValue和PGmv一结合,因为另外两个没有优化,所以线上收益可能就变成了千分之一,导致效果非常不显著。
另一个问题就是点击后的数据,实际上非常稀疏,所以Gmv预估非常不准。我们采用的One model方案实际上就是多目标优化。

收入跟GMV一起建模放在一个模型里,这样整体架构会非常简单。保证策略同步,优化一个模型,可以一并优化其他模型。另外,训练数据会更充分,不但有一跳的标志,还有二跳的标志,有点击有GMV标注,该算法是Pairwise和Pointwise算法的结合,就是Combine regression and rank。可以看一下Loss, Rank Loss保证了不同label的序关系,在rare events场景里,还能提升regression的效果。Regression Loss拟合绝对值,保持分布稳定,用于广告的二价计费。自上线之后,点击跟GMV就得到了大幅度的提升,而且整体架构非常简单。

浅层模型时代讲的偏多的是系统实现的工作,虽然是浅层模型,但实际上在深度学习阶段,工具还是继续复用的。从浅层模型过渡到深度学习,大家肯定有过这样的思考,为什么引入深度学习?

首先LR是线性模型,但它怎么做非线性建模呢?我们会通过加特征,或者各种特征组合的方式来做。通过增加模型维度,把低维线性不可分问题变为高维可分。一些特征组合比如FM或GBDT+LR,实际上是一个深度为2或深度为3的模型。而我们都知道,在大数据的背景下,DNN实际上是一个更通用的算法,它的工具和研究也会更多。
第二个原因是原来的算法优化更多的是手工方式,主要依赖于人工堆特征。深度学习实际上是通过算法方式来做,把人工特征工程变成了Feature Learning的过程,算法优化也由人工驱动变成了数据和算法驱动。这就是引入深度学习两个最大的收益,那么在推荐系统或者广告系统中引入深度学习面临的问题是什么?

第一个就是现有算法如何平滑过渡,我们做了一年多的工作,怎么把之前的特征和效果平滑的过渡过来,离散特征如何建模,其实做推荐的应该都知道,像这种特征是离散的值,并且规模大到billion级别,DNN算法实际稠密的矩阵预算,向量的大小是有限的,把亿级别的向量纳入其中进行训练,工程实现是一个很难的问题。我们用到的稀疏连续离散特征的建模方法,有如下两种:

一是离散特征数值化方法,把特征的离散值映射到连续型的数值空间,这其中有两种方法,一是Embedding方法,相关文章比较多大家可以搜一下,另外一个是稀疏样本转稠密向量表示,还有一个方法是CNN方法,就是把文本转为图像,通过CNN的方法来进行学习。
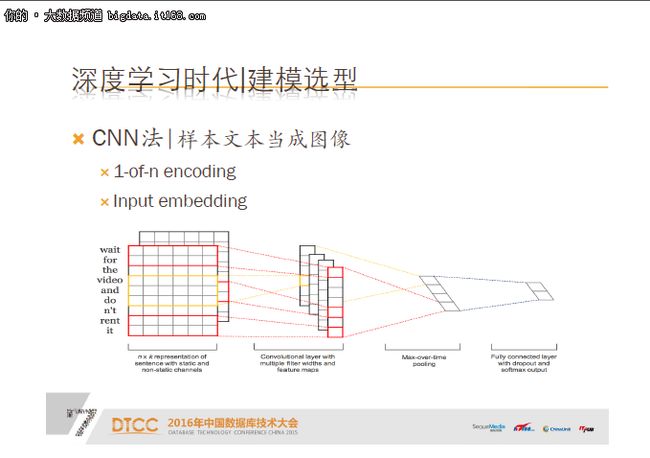
文本转图像的方式就是把样本的文本当图像处理,比如1-of-n encoding方案,就是把文本的one hot表示矩阵当做图来处理,或者第二个方案embedding的方式,把文本word的embedding向量组成矩阵,可以看一下第二个图,每个单词都表示成向量,这个向量可能是通过其他方式渠道来的也可以是随机初始化的,经过卷积,再进行pooling等步骤,就是CNN的文本转图像的方法。

CNN方法的效果还是比较明显的,离线评估指标有明显的提升,但问题是,在线开销非常大,评估下来大概对比浅层模型有10倍的机器开销。在线需要做大量的优化,整体的性价比会非常低。
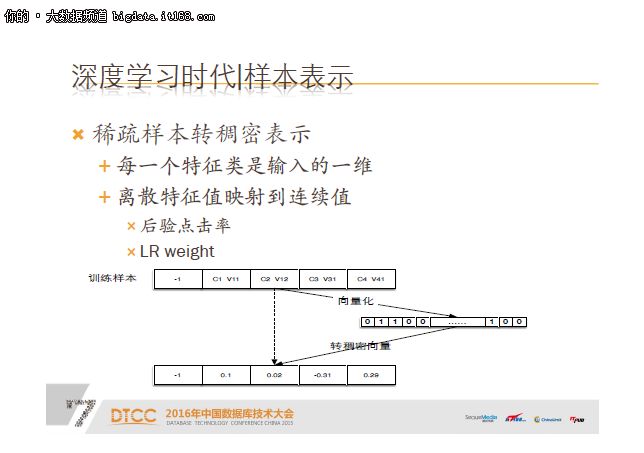
看图,训练样本label 之后,有四个特征,C1是特征类,V1是特征取值,C1比如说用户的地域,V1就是具体的城市,比如北京或者上海。这个向量化之后是一个巨大的稀疏向量。稀疏样本转稠密表示的方法思路是,每一个特征类作为稠密向量的一维,然后把特征类的特征取值映射到连续值。特征取值可以是后验点击率,或者直接用之前LR预先训练的特征权重,
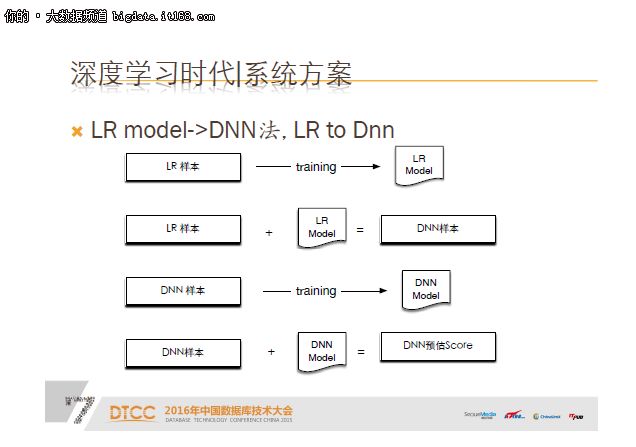
总结一下,用LR模型作为特征连续值的方法,我们叫LR to DNN的方法,步骤是把LR样本先训练得到LR模型,把LR样本用LR model转换,把原来离散的向量变成连续值,得到连续的稠密向量,DNN就能够处理了,把DNN样本进行训练,得到DNN model。这个方法的效果如何呢?

效果对比之前浅层的FM模型,AUC涨了2%。问题就是权重非常不稳定,因为第一层的输入来源是LR model,实际上跟DNN model是分开训练的,所以LR跟DNN之间的权重关系会非常不稳定,LR一波动,DNN层的效果就会跟着波动。另一个问题是,当我做进一步优化时,比如加特征,基本上是不可能的,原因就是在LR层加一个特征,要先验证LR模型的效果,上线落日志,落日志之后再训练DNN model,整个周期会非常长,为了解决LR和DNN分开训练的问题,我们用了一个新算法:
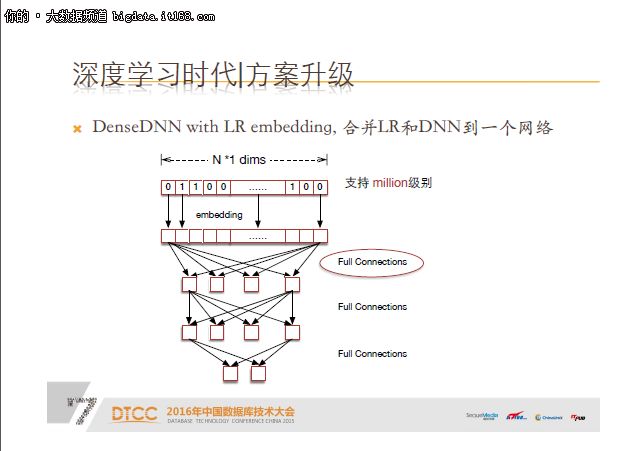
DenseDNN with LR embedding,把LR和DNN合并到同一个网络里进行训练。大家看如上的示意图,第一层还是LR样本,就是0/1表示的巨大向量,经过embedding的过程,把离散值映射成连续值,经过全连接然后到目标,训练时这个梯度还会反向传播到embedding,LR和DNN的参数会同步更新。
该方法的问题在于第二步跟第三步之间实际上是全连接,所以输入的向量大小实际上不能太大,只能到million级别。假如是1000万到100维的全连接,整个空间可以达到10亿的参数规模,这个训练基本是不可行的。
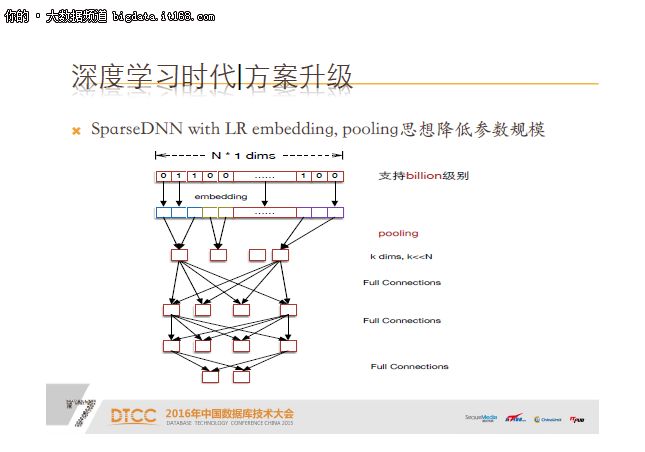
我们提出了进一步优化思路,叫SparseDNN with LR embedding,具体做法就是在embedding后追加pooling,仔细看这个图跟前面一张图很接近,唯一的区别就是增加了pooling层。pooling实际上是很快的,我们基于pooling的思想把相同类别的特征合并,到这层后,10亿可能就降了几百维的规模。 这个算法,实际上跟前面的LR to DNN算法是完全兼容的, LR to DNN的LR层实际上是特征值的累加操作。SparseDNN整个算法包括LR层,在一个网络里训练,并且支持的参数规模更大了,可以达到billion的级别,解决了稀疏性特征的问题。

对比Lr to Dnn,SparseDNN AUC累计提升2%到3%,而且无权重波动,系统稳定;Training together,无各种穿越问题;此外,One model统一结构,系统简单,更易继续优化扩展,离散特征和连续特征都能接入到一个网络中,我们还纳入了图像的embedding,行为的embedding接入。

我们研究了很多开源的框架,包括caffe,torch,petuum,DMTK,tensorflow等等,之所以不使用开源框架,是因为开源框架针对我们的应用存在一些问题,我们有10亿的稀疏特征,150亿样本,网络通讯完全支撑不住;多机支持上,GPU不能解决IO负载大的问题,另外,开源系统都是针对图像和语音领域,参数规模小,普遍采用的AllReduce方案,模型全量同步,每次模型分发都对所有结点进行分发,所以一下子就被打满了,通讯开销非常大。还有,对稀疏性支持,大规模稀疏矩阵运算也不能很好的支持。

所以,我们基于开源框架,自研了分布式训练系统,Theano+ParameterServer架构,尽量复用现有的开源框架,我们深度定制了Theano以支持大规模稀疏矩阵运算,ParameterServer作为参数交换机制。在系统性能方面,10亿稀疏特征,5层神经网络,150亿样本,4小时就可以完成训练。最后的系统,就是这样的效果。
今天的分享到此结束,谢谢大家!