openRefine使用报告
一、openrefine简介
无论是现今的大数据还是企业内部的小数据,都存在一些普遍的问题,如数据格式不对需要转换,一个单元格内包含多个含义的内容,包含重复项等等,虽然我们也可以使用excel解决,但是excel天生有诸多限制,比如其为直接对数据进行操作,容易导致误操作;数据量大会处理缓慢;透视表功能太过简单;无法进行高级的数据分类分析。而OpenRefine很好的解决了以上问题。
数据清洗Data Cleaning:是尝试通过移除空的数据行或重复的数据行、过滤数据行、聚集或转换数据值、分开多值单元等,以半自动化的方式修复错误数据的过程。数据清洗是一个反复的过程,不可能在几天内完成,只有不断的发现问题,解决问题。对于是否过滤,是否修正一般要求客户确认。
IDTs:Interactive Data Transformation tools,交互数据转换工具,它可以对大数据进行快速、廉价的操作,使用单个的集成接口。
OpenRefine就是这样的IDT工具,可以观察和操纵数据的工具。它类似于传统Excel的表格处理软件,但是工作方式更像是数据库,以列和字段的方式工作,而不是以单元格的方式工作。这意味着OpenRefine不仅适合对新的行数据进行编码,而且功能还极为强大。
二、下载及安装
openrefine的下载:从http://OpenRefine.org上下载软件
安装:安装比较简单,选好安装目录,按提示安装即可,要知道openrefine是基于java环境的,要保证电脑上有最新的Java环境;默认情况下,openrefine会分配1G内存给java,想要处理大数据,可以扩展内存。
三、初识openrefine
1.创建一个新项目
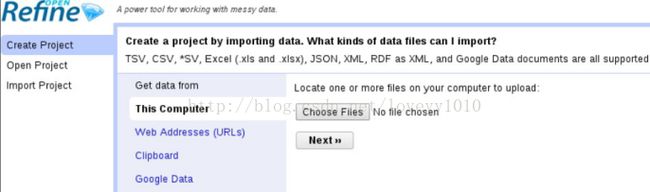
以下是部分OpenRefine支持的文件格式:
●csv、tsv及其他*sv
●xls/xlsx、cdf、ods
●JSON
●XML
●行文本格式(比如log文件)
如果你需要打开其他格式文件,你可以通过OpenRefine扩展功能打开。
创建OpenRefine项目十分简单,只需要三步:选择文件、预览数据内容、确认创建。让我们通过点击“创建项目”标签页、选择数据集、点击下一步来创建新项目。
2.操纵列
列是OpenRefine中的基本元素:其是具有同一属性的成千上万的值的集合,可以按照很多方法查看处理。
列在OpenRefine中的操作有隐藏和展开(View菜单)、按需要转换、移动以及重命名和删除(Edit菜单)。
通过操纵列可以更加直观方便的观察数据,分析数据,操作数据。
3.项目操作历史
这是OpenRefine一个特别有用的功能,可以在项目创建后保存所有的操作步骤。这也就意味着你不需要害怕做数据变换尝试:你可以随意按照自己的想法变换数据,因为一旦你发觉做错了(即使是几个月前做的),你也可以撤销该操作以恢复数据。
只有对数据有实际影响的操作才会出现在项目历史操作表中。数据透视比如:交换行列视角、在一页中改变显示数目、隐藏或展开列并不改变原来数据,所以也就不会出现在操作历史表中。
操作历史也可以以JSON格式导出,可以点击Undo / Redo页中的Extract…
4.导出项目
大部分弹出的选项能够让你将数据导出为常用格式,比如csv、tsv、excel和open document格式、还有不常用的RDF格式。
还可以导出openrefine的压缩包(Export project),将文件发布到互联网上(HTML table)。自定义导出设置(Custom tabular exporter and templating)等
5.获取更大的运行内存
Windows
Windows平台,你可以在OpenRefine的文件夹中找到openrefine.l4j.ini文件,找到以-Xmx(对于JAVA来说表示最大内存数)开始的那行,默认情况下分配内存为1024M。稍稍改大点,比如2048M。保存后下次你打开OpenRefine就能够生效。
Mac
对于Mac平台就有点复杂,因为Mac电脑的操作系统将配置文件隐藏了。首先关闭OpenRefine,按住control键然后点击OpenRefine图标,在弹出菜单中选择Show package contents,然后在Contents文件夹中找到info.plist文件并打开,然后在其中找到VMOptions项(这就是JAVA虚拟机设置项)。找到以-Xmx开头的设置项,将默认的1024M按你的需要修改,比如-Xmx 2048M。
四、分析和修改数据
分析数据包括排序和各类透视功能,还包括文本过滤和检重。
修复数据步骤则包括排序、单元格转换、删除。
1.数据排序(sort菜单)
单元格值可以按照文本(区别大小写或者不区别)、数字、日期、布尔值排序,对每个 类别有两种不同的排序方式:
• Text: 文本:从a到z排序或者从z到a排序
• Numbers数字: 升序或者降序
• Dates: 日期升序或者日期降序
• Booleans: false值先于true值 或true值先于false值
我们还可以对错误值和空值指定排序顺序。比如错误值可以排在最前面(这样容易发现问题),空值排在最后(因为空值一般没有意义),而有效值居中。
每次对某列进行排序,你就会面对三种抉择:取消排序回到原来状态、暂时保持、永久改变。
如果你想将排序后的结果再进行后续操作,一定要将排序结果永久保存,比如对于空白单元格或者填充单元格,为了避免前后不一致的错误。
2.数据透视(Facet菜单)
数据透视并不改变数据,但是可以让你获得数据集的有用信息。你可以把数据透视看作是多方面查看数据的方法,就像从不同的角度观察宝石一样。数据透视可以获得数据中一个变化后的子集,比如只显示某个参数要求下的行。
对字符串进行文本透视、对数字和日期进行数字透视、几个预定义的透视功能、最后还有标星和标旗功能。OpenRefine的强大之处也在于这些透视功能的组合使用。
(1)文本透视( Text facet):只有该列中的类别总数不是特别大的时候文本透视才有用,因为文本透视并不是为了列出所有的信息,全部列出并没有多大意义,同时透视结果也不会出现相同的两个类别(除非又重复项,我们将在下一点中说明)
(2)数字透视(Numeric facet)
文本透视会返回一个不同分类数量的列表,而数字透视则是某个数值范围的分布,就像我们通过频数来透视一样。
(3)时间轴透视(Timeline facet)
时间轴透视要求数据为日期格式,所以类似17/10/1890 的文本字符串需要改为日期格式(Edit cells | Common transforms | To date )。
(4)定制透视(Customized facets)
定制透视就是按照你的想法自如的透视数据,需要对General Refine Expression language(openrefine内建函数语言GREL)有基本的了解
(5)对标星和标旗行进行透视
现在假设你想显示要么diameter字段有内容或者weight字段有内容的行。如果你对这两列都做了空值透视,然后分两次点击结果是false的内容,你将得到29行匹配,但其实这29行指的是diameter字段有内容而且weight字段也有内容,这和我们的目的不符,我了按要求取到数据,解决方法是分两步:先对diameter列进行空值透视,得到2106行为false(也就是diameter内容存在),然后使用All| Edit rows| Star rows标星,清除透视并且对weight列进行空值透视,得到179行(你会注意到只有150行被标星,因为29行已经被标星,其weight和diameter都有内容而已)。再次清除透视,然后选择All| Facet| Facet by star获得数据
3.重复检测
重复值是数据集中出现两次或更多次的恼人数据。重复数据不仅浪费存储空间,并且会导致干扰。所以我们希望能够删除重复值。
重复项透视(Duplicates facet)就是一种能够检测重复的简单办法。但是其也有限制性,比如其只能对字符串进行重复检测,最起码不能直接对非字符串进行操作
4.文本过滤(Text flter)
当你想寻找那些匹配某个特定字符串的行时,最简单的方法是使用文本过滤功能。
简单的文本过滤并没有考虑到拼写方式
文本过滤的另一个应用是检测分隔符的使用
5.简单的单元格转换(Edit cells菜单)
(1)删除首尾空格(Common transforms|Trimming whitespace):对数据进行删除多余首尾空格操作是提升数据质量的很好的开始。这保证了不会因为首尾处的空格使得相同的值为误认为不同;删除首尾空格的操作只能针对字符串,而不能对整数操作。如果你去试试,也会发现所有整数会被删除。
(2)连续空格只保留一个(Common transforms|Collapse consecutive whitespace):这个操作很安全,而且总是对数据清洗有益的。会将整数转化成字符串。
(3)解析HTML标记(Common transforms|Unescape HTML entities):HTML代码内容就能够被正确解析。
(3)大小写转换(Common transforms |To uppercase):这些值的变化主要是因为整数被转换成了字符串(因为数字被认为没有被大写)。To titlecase只会将空格后的字符串首字母大写
6.删除匹配行
检测重复或者将冗余行标上旗帜标识是需要的,但还不够。某些时候,你可能需要从单纯的数据分析转到数据清洗中来。在实际情况中,这意味着那些有问题的行需要从数据集中删除,因为它们的存在是对数据质量的损害。
在删除行前,请确保你已经做过了一个透视或者过滤,不然你可能会误将所有数据删除。请确保OpenRefine是以行rows显示而不是以记录records显示。
删除空值行十分简单,问题是,如果你直接删除这些行,那么不光重复项会被删除,那个唯一的值同时也会被删除。换句话说,如果某行出现了两次,那么删除匹配行就会把两条都删除而不是仅仅删除一条。不过即使你误删除了,你也可以通过项目历史恢复。
所以我们需要做到既去除多余重复项,同时还能够保留一项。我们可以这么做:对Registration Number进行排序,选择text和a-z选项(case sensitive不必勾选,因为该列只有大写),然后选择Sort| Reorder rows permanently来固定排序。最后,使用Registration Number | Edit cells| Blank down将多余的重复项使用空白填充
五、高级数据操作
1.对多值单元格进行处理
分割单元格内容(Edit Cells | Split multi-valued cells…):可以让我们了解所有单独的分类。把他们重新组合在一起(Edit cells |Join multi-valued cells…):分隔符可以随意设置。
2.行模式和记录模式的转换
row是指数据集中的一行。
Record包括一个主体中的所有行。第一行所有单元格非空,标识一条记录;后续行中相同内容为空,表示这些行隶属于同一条记录
在records模式下,操作对整条记录有效,记录起码是一行以上。总结下,我们可以这么说,rows模式只是各个独立的行,而records模式则是一个整体,可以包含数行。
3.相似单元格聚类(clustering)
你在分割多值单元格后对分类进行了分析,你会发现同样的分类并不一定有相同的拼写。比如,Agricultural Equipment 和 Agricultural equipment(大小写不同),Costumes 和 Costume(单复数区别)等等。这类问题可以借助OpenRefine的clustering自动处理。
在实际应用中,最好的方法是尝试不同的聚类组合,每次都需要小心的确认聚类项是否真的可以合并。
4.单元格转换(Edit cells | Transform…. )
value.replace("|", ", ")
递replace参数时出错了。如果我们检查下出现错误的单元格,我们发现是有些单元格为null所导致,选择Text filter.虽然我们可以选择Facet by blank功能
value.split(", “).uniques().join(”, "):将值按照“,”分割(逗号后面跟一个空格),然后使用uniques函数去重,最后再把内容重新连接到一起
5.增加源列(Add column based on this column…)
有时候你可能希望在单元格值转换的时候保留原单元格值,同时显示原值和转换后的值得话一定会更好
6.拆分列(Split into several columns….)
分割列比分割多值单元格功能更加强大,因为其有很多配置选项。你甚至可以使用正则表达式来定义分隔符,这样我们可以做到不同的内容应用不同的分隔符
7.行列转换(Transpose | Transpose cells across columns into rows…)
左侧From Column栏中选择需要转换的开始列,To Column 栏选择停止转换的列,这两列中间的所有列就是需要转换的列。
注意,这里OpenRefine需要设置成records模式以保证信息关联。所以,如过某行有不同的量度信息,那么转换后它们会占据多行。
我们还可以通过执行Transpose |Columnize by key/value columns…来实现反向转换。但是,这个操作对于空单元格十分敏感,所以必须小心。
六、正则表达式和GREL
regular expressions(正则表达式) 和 GREL. Regular expressions 是在处理大量数据时用来匹配和替换文本的有效工具。
这部分内容表达式及其组合较多,需要不断的练习和尝试来达到熟练应用的程度。