一、K近邻算法
1.k近邻法是一种基本的分类与回归方法。
1).分类问题:对新的样本,根据其k个最近邻的训练样本的类别,通过多数表决等方式进行预测。
2).回归问题:对新的样本,根据其k个最近邻的训练样本标签值的均值作为预测值
2.k近邻法不具有显示的学习过程,它是直接预测。它是“惰性学习”(lazy learning)的著名代表。
1).它实际上利用训练数据集对特征向量空间进行划分,并且作为其分类的“模型”。
2).这类学习技术在训练阶段仅仅将样本保存起来,训练时间开销为零,等到收到测试样本后再进行处理。
那些在训练阶段就对样本进行学习处理的方法称作“急切学习”(eager learning)。
3.k近邻法是个非参数学习算法,它没有任何参数(k是超参数,而不是需要学习的参数)。
1).k近邻模型具有非常高的容量,这使得它在训练样本数量较大时能获得较高的精度。
2).它的缺点有:
a 计算成本很高。因为需要构建一个N*N的距离矩阵,其计算量为O(),其中N为训练样本的数量。
当数据集是几十亿个样本时,计算量是不可接受的。
b 当训练集较小时,泛化能力很差,非常容易陷入过拟合。
c 无法判断特征的重要性。
4.k近邻的三要素:
1)k值选择。
2)距离度量。
3)决策规则。
1.1K值选择
1.当k = 1 时的k近邻算法称为最近邻算法,此时将训练集中与最近的点的类别作为的分类。
2.k值的选择会对k近邻法的结果产生重大影响。
a 若k值较小,则相当于用较小的邻域中的训练样本进行预测,“学习”的偏差减小。
只有与输入样本较近的训练样本才会对预测起作用,预测结果会对近邻的样本点非常敏感。
若近邻的训练样本点刚好时噪音,则预测会出错。即:k值的减小意味着模型整体变复杂,易发生过拟合。
α 优点:减少“学习”的偏差。
β 缺点:增大学习的方差(即波动较大)。
b 若k值较大,则相当于用较大的邻域中的训练样本进行预测。
这时输入样本较远的训练样本也会对预测起作用,使预测偏离预期的结果。
即:k值增大意味着模型整体变简单。
α 优点:减少“学习”的方差(即波动较小)。
β 缺点:增大“学习”的偏差。
3.应用中,k值一般取一个较小的数值。通常采用交叉验证法来选取最优的K值。
1.2 距离度量
1.特征空间中两个样本点的距离是两个样本的相似程度的反映。
k近邻模型的特征空间一般是n维实数向量空间,k其距离一般为欧式距离,也可以是一般的Lp距离:
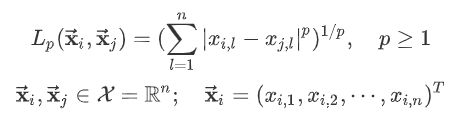
a 当p = 2时,为欧式距离: = (,)= ()^1/2
b 当p = 1时,为曼哈顿距离:
c 当p = ∞时,为各维度距离中的最大值:
2.不同的距离度量所确定的最近邻点时不同的。
1.3决策规则
1.3.1 分类决策规则
1.分类决策通常采用多数表决,也可以基于距离的远近进行加权投票:距离越近的样本权重越大。
2.多数表决等价于经验风险最小化。
设分类的损失函数为0 - 1 损失函数,分类函数为f: {}。
给定样本,其最近邻的k个训练点构成集合。设涵盖区域的类别为(这是待求的未知量,但是它肯定是之一),则损失函数为:
L就是训练数据的经验风险。要是经验风险最小,则使得最大。即多数表决:
1.3.2 回归决策规则
1.回归决策通常采用均值回归,也可以基于距离的远近进行加权投票:距离越近的样本权重越大。
2.均值回归等价于经验风险最小化。
设回归的损失函数均为均方误差。给定样本,其最近邻的k个训练点构成集合。设涵盖区域的输出为,则损失函数为:
L就是训练数据的经验风险。要使经验风险最小,则有:。即:均值回归。
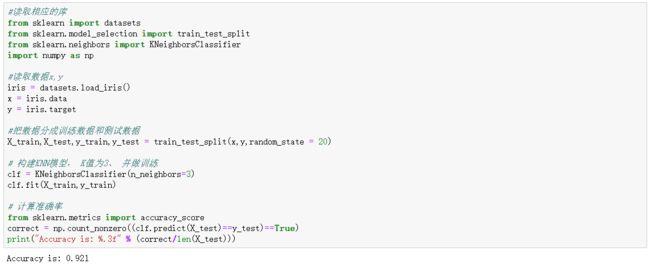
DEMO
#读取相应的库
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
#读取数据x,y
iris = datasets.load_iris()
x = iris.data
y = iris.target
#把数据分成训练数据和测试数据
X_train,X_test,y_train,y_test = train_test_split(x,y,random_state = 20)
# 构建KNN模型, K值为3、 并做训练
clf = KNeighborsClassifier(n_neighbors=3)
clf.fit(X_train,y_train)
# 计算准确率
from sklearn.metrics import accuracy_score
correct = np.count_nonzero((clf.predict(X_test)==y_test)==True)
print("Accuracy is: %.3f" % (correct/len(X_test)))
注意点:
1.大数吞小数
在进行距离计算的时候,有时候某个特征的数值会特别大,其他的特征的值的影响就会非常的小被大数覆盖掉了。所以我们很有必要进行特征的标准化或者叫做特征的归一化
2.如何处理大数据量
一旦特征或者样本的数目特别的多,KNN的时间复杂度将会非常的高。
解决方案:kd树搜索算法
kd树是一种对K维空间中的样本点进行存储以便对其进行快速检索的树形数据结构。它是二叉树,表示对k维空间的一个划分。
3.怎么处理样本的重要性
利用权重值。我们在计算距离的时候可以针对不同的邻居使用不同的权重值,比如距离越近的邻居我们使用的权重值偏大,这个可以指定算法的weights参数来设置。