spring-data-jpa 是如何渲染查询的
spring-data-jpa 是如何渲染查询的
1、 spring-data-jpa是什么, 它和jpa有什么关系?
jpa: Java Persistence API, 是一种规范, 定义了一系列的接口, 用于将对象映射到表上.
Hibernate: 是jpa的一种实现
spring-data-jpa spring全家通成员之一, 也是jpa的一种实现, 并且是hibernate的封装, 底层调用的是hibernate
三者的关系可以参考下图(图片源自网络)
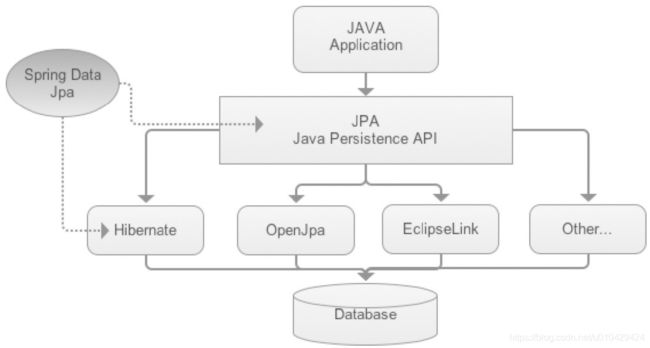
从上图中可以看出, spring-data-jpa 也是jpa规范的实现之一,并且底层封装的是hibernate
2、一次查询的渲染过程
在我实际工作中, 我们是这么使用spring-data-jpa的:
@Repository
public interface UserRepository extends AbstractRepository<UserDO, UUID> {
List<UserDO> findByUserIdAndValidTrueOrderByUserOrder(UUID id);
}
上面的代码定义了一个UserRepository接口,接口中定义了方法:findByUserIdAndValidTrueOrderByUserOrder, 从左到右通读这个方法名,仿佛看到了下面这条sql:
select * from t_user where user_id=:id and valid=1 order by user_order asc;
那么,spring-data-jpa是怎如何把这一大串方法(findByUserIdAndValidTrueOrderByUserOrder),“ 翻译”成可执行的sql的,其中spring-data-jpa为我们做了哪些事情呢?
要理解这个问题, 首先可以明确一点思路:首先把需要“翻译”的方法定位出来,即找到一系列findXXXByXXX方法,然后按照方法名一步一步“渲染”成sql
为此,spring-data-jpa实现了一个"查询方法拦截器" QueryExecutorMethodInterceptor (cglib动态代理 ), 部分代码如下:
public class QueryExecutorMethodInterceptor implements MethodInterceptor {
// queries是一个复数名词, 一个Map类型, key是Method, value是RepositoryQuery
private final Map<Method, RepositoryQuery> queries;
// 在项目启动时, 会走到这个构造方法里
public QueryExecutorMethodInterceptor(RepositoryInformation repositoryInformation,
ProjectionFactory projectionFactory) {
// ...
this.queries = lookupStrategy //optional
.map(it -> mapMethodsToQuery(repositoryInformation, it, projectionFactory)) //
.orElse(Collections.emptyMap());
}
// 把method映射成Query, 返回一个MapQueryExecutorMethodInterceptor类中, 包含一个重要的成员:queries,显然queries是一个复数名词, 它是一个Map类型, key是Method, value是RepositoryQuery,用来存储多个Method -> RepositoryQuery映射关系对
在项目启动时, 程序会走到QueryExecutorMethodInterceptor的构造方法中,为queries赋值。其中,RepositoryInformation包含待映射的Method,在mapMethodsToQuery方法中,将Method映射成了RepositoryQuery。
那么是如何映射的呢?关键就在lookupQuery方法中,将映射的实现委托给了strategy.resolveQuery方法
strategy是啥呢,它是一个QueryLookupStrategy 对象, QueryLookupStrategy 有三种实现策略:
- CREATE: 直接根据方法名创建Query
- USE_DECLARE_QUERY: 使用@Query声明的方式创建 Query
- CREATE_IF_NOT_FOUND : 1, 2的结合, 先找有没有@Query注解, 没有则直接用方法名创建 Query
在XXApplication类中,我们可以使用@EnableJpaRepositories(queryLookupStrategy= … )配置QueryLookupStrategy,
默认的配置是CREATE_IF_NOT_FOUND, 所以看下 CREATE_IF_NOT_FOUND这种策略是 如何实现resolveQuery方法的
@Override
protected RepositoryQuery resolveQuery(JpaQueryMethod method, EntityManager em, NamedQueries namedQueries) {
try {
return lookupStrategy.resolveQuery(method, em, namedQueries); // 先查询@Query注解, 查不到则抛出异常
} catch (IllegalStateException e) {
return createStrategy.resolveQuery(method, em, namedQueries); // 捕捉到异常后, 执行创建策略
}
}
这里使用了try catch做流程控制,先查询有没有@Query注解, 如果查不到则抛出异常;在捕捉到异常后, 使用方法名创建。用try-catch做流程控制,可能并不太友好。
接下来看看 createStrategy.resolveQuery方法为我们做了哪些事
@Override
protected RepositoryQuery resolveQuery(JpaQueryMethod method, EntityManager em, NamedQueries namedQueries) {
return new PartTreeJpaQuery(method, em, persistenceProvider, escape);
}
/**
* Creates a new {@link PartTreeJpaQuery}.
*
*/
PartTreeJpaQuery(JpaQueryMethod method, EntityManager em, PersistenceProvider persistenceProvider,
EscapeCharacter escape) {
// ...
this.tree = new PartTree(method.getName(), domainClass);
// ...
}
resolveQuery方法都在围绕PartTree搞事情,放眼望去,主要就是new了一个PartTree对象, PartTree这个类是做什么的呢?构造方法如下:
public PartTree(String source, Class<?> domainClass) {
Matcher matcher = PREFIX_TEMPLATE.matcher(source);
if (!matcher.find()) {
this.subject = new Subject(Optional.empty());
this.predicate = new Predicate(source, domainClass);
} else {
this.subject = new Subject(Optional.of(matcher.group(0)));
this.predicate = new Predicate(source.substring(matcher.group().length()), domainClass);
}
}
从上面的构造方法中, 看到PartTree利用正则表达式, 解析出了方法名中的主语和谓语。
关于正则表达式, PartTree中定义了下面几个正则:
- QUERY_PATTERN = “find|read|get|query|stream”;
- COUNT_PATTERN = “count”;
- EXISTS_PATTERN = “exists”;
- DELETE_PATTERN = “delete|remove”;
- Pattern PREFIX_TEMPLATE = Pattern.compile( “^(” + QUERY_PATTERN + “|” + COUNT_PATTERN + “|” + EXISTS_PATTERN + “|” + DELETE_PATTERN + ");
关于主语和谓语, 下面的注释还是值得一看的
/**
* The subject, for example "findDistinctUserByNameOrderByAge" would have the subject "DistinctUser".
*/
private final Subject subject;
/**
* The subject, for example "findDistinctUserByNameOrderByAge" would have the predicate "NameOrderByAge".
*/
private final Predicate predicate;
findXXXByYYY, 可以把XXX理解成subject,把YYY理解为predicate
以"findByUserIdAndValidTrueOrderByUserOrder"为例, 将被解析成以下类似树状的结构(可能这也是PartTree名字的来源)
findByUserIdAndValidTrueOrderByUserOrder
-> UserIdAndValidTrueOrderByUserOrder
-> UserIdAndValidTrue
-> UserId
And
-> ValidTrue
-> OrderByUserOrder
-> UserOrder
-> ASC
然后,把得到PartTree对象封装成RepositoryQuery 并返回,这样就将Method映射成了RepositoryQuery,
在启动时, 就创建出了 Map
下面是创建Map
org.springframework.data.repository.core.support.RepositoryFactorySupport.QueryExecutorMethodInterceptor#QueryExecutorMethodInterceptor
org.springframework.data.repository.core.support.RepositoryFactorySupport.QueryExecutorMethodInterceptor#mapMethodsToQuery
org.springframework.data.repository.core.support.RepositoryFactorySupport.QueryExecutorMethodInterceptor#lookupQuery
org.springframework.data.jpa.repository.query.JpaQueryLookupStrategy.AbstractQueryLookupStrategy#resolveQuery(java.lang.reflect.Method, org.springframework.data.repository.core.RepositoryMetadata, org.springframework.data.projection.ProjectionFactory, org.springframework.data.repository.core.NamedQueries)
org.springframework.data.jpa.repository.query.JpaQueryLookupStrategy.CreateIfNotFoundQueryLookupStrategy#resolveQuery
org.springframework.data.jpa.repository.query.JpaQueryLookupStrategy.CreateQueryLookupStrategy#resolveQuery
org.springframework.data.jpa.repository.query.PartTreeJpaQuery#PartTreeJpaQuery(org.springframework.data.jpa.repository.query.JpaQueryMethod, javax.persistence.EntityManager, org.springframework.data.jpa.provider.PersistenceProvider, org.springframework.data.jpa.repository.query.EscapeCharacter)
org.springframework.data.repository.query.parser.PartTree
得到Map
答案是, 在执行查询时, 根据method 直接找到对应的RepositoryQuery, 利用到了上面的queries
Method method = invocation.getMethod();
if (hasQueryFor(method)) {
return queries.get(method).execute(invocation.getArguments());
}
拿到RepositoryQuery后, 对Query进行渲染, 最终会进入hibernate中,下面是调用栈
org.springframework.data.repository.core.support.RepositoryFactorySupport.QueryExecutorMethodInterceptor#invoke
org.springframework.data.repository.core.support.RepositoryFactorySupport.QueryExecutorMethodInterceptor#doInvoke
org.springframework.data.jpa.repository.query.AbstractJpaQuery#execute
org.springframework.data.jpa.repository.query.AbstractJpaQuery#doExecute
org.springframework.data.jpa.repository.query.JpaQueryExecution#execute
org.springframework.data.jpa.repository.query.JpaQueryExecution.SingleEntityExecution#doExecute
org.springframework.data.jpa.repository.query.AbstractJpaQuery#createQuery
org.springframework.data.jpa.repository.query.PartTreeJpaQuery#doCreateQuery
org.springframework.data.jpa.repository.query.PartTreeJpaQuery.QueryPreparer#createQuery(org.springframework.data.jpa.repository.query.JpaParametersParameterAccessor)
org.springframework.data.jpa.repository.query.PartTreeJpaQuery.QueryPreparer#createQuery(javax.persistence.criteria.CriteriaQuery<?>)
// 从这里开始, 进入hibernate
org.hibernate.engine.spi.SessionDelegatorBaseImpl#createQuery(javax.persistence.criteria.CriteriaQuery<T>)
org.hibernate.internal.AbstractSharedSessionContract#createQuery(javax.persistence.criteria.CriteriaQuery<T>)
org.hibernate.query.criteria.internal.compile.CriteriaCompiler#compile
org.hibernate.query.criteria.internal.CriteriaQueryImpl#interpret
下面渲染部分
org.hibernate.query.criteria.internal.QueryStructure#render
org.hibernate.query.criteria.internal.QueryStructure#renderSelectClause
最终走到QueryStructure的render方法,通过renderXXX方法,依次渲染select,from,where,group by
public void render(StringBuilder jpaqlQuery, RenderingContext renderingContext) {
renderSelectClause( jpaqlQuery, renderingContext );
renderFromClause( jpaqlQuery, renderingContext );
renderWhereClause( jpaqlQuery, renderingContext );
renderGroupByClause( jpaqlQuery, renderingContext );
}
renderXXX方法里, 主要是jpaqlQuery查询字符串的拼接, 这里以renderSelectClause为例,看看它都做了哪些事:
protected void renderSelectClause(StringBuilder jpaqlQuery, RenderingContext renderingContext) {
renderingContext.getClauseStack().push( Clause.SELECT );
try {
jpaqlQuery.append( "select " );
if ( isDistinct() ) {
jpaqlQuery.append( "distinct " );
}
if ( getSelection() == null ) {
jpaqlQuery.append( locateImplicitSelection().render( renderingContext ) );
}
else {
jpaqlQuery.append( ( (Renderable) getSelection() ).render( renderingContext ) );
}
}
finally {
renderingContext.getClauseStack().pop();
}
}
renderSelectClause主要做了StringBuilder的拼接
到了这里, 对于如何把方法名“翻译”成sql, 能有个大概的认识了。当然这里的sql,也并不是mysql可已直接执行的原生sql,按我的理解应该是hibernate定义的一种“类似sql”的形式,里面有些占位符等。
总结:
上面主要分析了select查询是如何被渲染成sql的,当然, 除了将方法名映射成sql以外, jpa也支持@Query注解, 自定义查询, 支持原生sql或HQL
@Query("select * from tb_task t where t.task_name = ?1", nativeQuery = true)
Task findByTaskName(String taskName);
@Query("select t from Task t where t.taskName = ?1")
Task findByTaskName(String taskName);