6/6 知识图谱的生成与频繁序列匹配
知识图谱的生成就用了前天的思路,仔细考虑了一下,发现就是前项事件集和后项事件集做二分图连接,前项事件集内做全连接,遍历即可。之后还加了底图,就是所有在用户数据中出现过的2-序列,也一并画在图里了,没有的话只有一个主干显得有些单薄,虽然我并不知道这样好不好。具体需不需要要将来跑一跑实际数据集才知道。做出来之后效果还蛮不错(对测试数据集采取了40%的支持度):
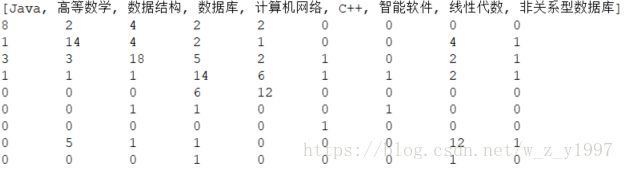
emmmm这是个那个图的关联矩阵,不用关心自连接那种东西,数值代表频繁程度。和测试数据集比对着看了一下,的确很符合我直观的感觉,可以算是比较成功了。这部分的代码:
package aprioriAll;
import java.util.HashSet;
import java.util.Map;
import java.util.Set;
import java.util.Vector;
public class GraphCalculator {
AprioriAllCalculation ap;
SequenceRecommender sr;
int[][] graph;
public GraphCalculator() {
ap = new AprioriAllCalculation();
ap.aprioriAllProcess();
}
public static void main(String[] args) {
// TODO Auto-generated method stub
GraphCalculator gc = new GraphCalculator();
gc.generateGraph();
gc.addBaseGraph();
gc.addFreqSeqGraph();
gc.output(gc.graph);
gc.generateRecmend();
}
private void generateRecmend() {
// TODO Auto-generated method stub
sr = new SequenceRecommender(ap.resultSet);
Vector freqSeq = sr.matchSequence(ap.data);
System.out.println(freqSeq);
for (Integer integer : freqSeq) {
}
}
private int[][] generateGraph() {
// TODO Auto-generated method stub
int itemCount = ap.itemList.size();
graph = new int[itemCount][itemCount];
return graph;
}
private int[][] addBaseGraph() {
// TODO Auto-generated method stub
ap.generateSeq_2();
Vector> seqs = ap.seq_2;
Map itemToIndex = ap.itemMaps;
// 对每一个2-序列 连接对应边
for (Vector seq : seqs) {
graph[itemToIndex.get(seq.get(0))][itemToIndex.get(seq.get(1))]++;
}
return graph;
}
// 把前面的和后面的链接起来,链接前后一样的抛弃,把里面的全连接
public int[][] addFreqSeqGraph() {
// ap.generateSeq_2();
// int itemCount = itemList.size();
// int[][] graph = new int[itemCount][itemCount];
Vector>> resultSet = ap.resultSet;
Map itemToIndex = ap.itemMaps;
// 对每个序列
for (int i = 0; i < resultSet.size(); i++) {
Vector> seq = resultSet.get(i);
// 对序列中的每个事件集
for (int j = 0; j < seq.size(); j++) {
Vector itemSet = seq.get(j);
// 对事件集中的每一个事件
for (int k = 0; k < itemSet.size(); k++) {
// 与其他事件全连接
for (int k2 = k; k2 < itemSet.size(); k2++) {
graph[itemToIndex.get(itemSet.get(k))][itemToIndex.get(itemSet.get(k2))]++;
graph[itemToIndex.get(itemSet.get(k2))][itemToIndex.get(itemSet.get(k))]++;
}
// 如果不是序列中最后一个事件集
if (j < seq.size()-1) {
Vector nextItemSet = seq.get(j+1);
// 链接序列中后一个事件集中的每个事件
for (int l = 0; l < nextItemSet.size(); l++) {
graph[itemToIndex.get(itemSet.get(k))][itemToIndex.get(nextItemSet.get(l))]++;
}
}
}
}
// 直接采用全部频繁序列的方法 已抛弃
// for (int j = 0; j < seq.size()-1; i++) {
// Vector curItemSet = seq.get(i);
// Vector nextItemSet = seq.get(i+1);
//
//
// if (curItemSet.size() == 1) {
// if (nextItemSet.size() == 1) {
// int cur = this.ap.itemMaps.get(curItemSet.get(0));
// int next = this.ap.itemMaps.get(nextItemSet.get(0));
// graph[cur][next]++;
// } else if (nextItemSet.size() > 1) {
// if (nextItemSet.contains(curItemSet.get(0))) {
//
// }
// }
//
// }
// }
}
return graph;
}
private Set countingItem(Vector>> resultSet) {
// TODO Auto-generated method stub
Set itemSet = new HashSet();
for (Vector> vector : resultSet) {
for (Vector vector2 : vector) {
for (String item : vector2) {
itemSet.add(item);
}
}
}
return itemSet;
}
private void output(int[][] graph) {
System.out.println(ap.itemList);
for (int i = 0; i < graph.length; i++) {
for (int j = 0; j < graph.length; j++) {
System.out.print(graph[i][j] + "\t");
}
System.out.println();
}
}
} 然后是频繁序列匹配,这里采用了用户序列中的最近2-序列来匹配频繁序列,并且匹配到最长的那条。代码:
package aprioriAll;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.HashSet;
import java.util.Set;
import java.util.StringTokenizer;
import java.util.Vector;
public class SequenceRecommender {
/**
* 最大频繁序列集合
*/
Vector>> sequenceSet;
/**
* 用户数据集
*/
private Vector>> data;
/**
* 用户数
*/
private int numUsers;
/**
* 输入间隔符
*/
private String itemSep = " ";
/**
* 构造器
* @param sequenceSet 使用AprioriAll生成的最大频繁序列
*/
public SequenceRecommender(Vector>> sequenceSet) {
this.sequenceSet = sequenceSet;
}
/**
* 序列匹配方法1 使用从文件来的新数据 推荐使用本方法并只采用每个用户最近两个事务的数据 否则很难匹配到频繁序列
* @param configFile 配置文件路径
* @param dataFile 数据文件路径
* @return 返回每个用户匹配到的最大序列
*/
public Vector matchSequence(String configFile,String dataFile) {
getConfig(configFile);
getUserData(dataFile);
return matchSequenceAction();
}
/**
* 序列匹配方法2 使用传递来的用户数据
* @param data 用户数据 例如生成频繁序列的用户数据
* @return 返回每个用户匹配到的最大序列
*/
public Vector matchSequence(Vector>> data) {
this.data = data;
return matchSequenceAction();
}
/**
* 序列匹配
* 检查用户数据的最近2-序列是否是某个最大频繁序列的子序列 如果是 返回所有匹配到的频繁序列中最长的
* @return
*/
private Vector matchSequenceAction() {
cutData();
Vector maxSeqs = new Vector<>();
// 对每个用户的最近序列
for (Vector> user : data) {
int maxSize = 0;
int maxIndex = -1;
// 检查每个频繁序列
for (int i = 0; i < sequenceSet.size(); i++) {
Vector> freq = sequenceSet.get(i);
Vector> userSeq = new Vector>(user);
Vector> freqSeq = new Vector>(freq);
while (userSeq.size() > 0 && freqSeq.size() > 0) {
// 检查是否可以匹配到这个序列(用了一种“跳过不匹配”的巧妙方式)
if (equalSet(userSeq.get(0),freqSeq.get(0))) {
userSeq.remove(0);
} else {
freqSeq.remove(0);
}
// 匹配到而且匹配到的最大序列更长 记录下来
if (userSeq.size() == 0 && freq.size() > maxSize) {
maxIndex = i;
maxSize = freq.size();
}
else {
}
}
}
maxSeqs.add(maxIndex);
}
return maxSeqs;
}
/**
* 检查两个事件集是否相等的辅助方法
* @param vector 第一个事件集
* @param vector2 第二个事件集
* @return 作为集合是否相等
*/
private static boolean equalSet(Vector vector, Vector vector2) {
Set set1= new HashSet(vector);
Set set2= new HashSet(vector2);
if (set1.equals(set2)) {
return true;
}else {
return false;
}
}
/**
* 裁剪数据集 只使用最近两个事务 否则很难匹配到序列
*/
private void cutData() {
Vector>> tempData = new Vector<>();
for (Vector> user : data) {
int size = user.size();
if (size > 2) {
Vector> cutUser = new Vector<>();
cutUser.add(user.get(size-2));
cutUser.add(user.get(size-1));
tempData.add(cutUser);
} else {
tempData.add(user);
}
}
data = tempData;
}
/**
* 读取数据库中的数据,生成一个以三维数组表示的数据集
* @param dataFile 数据文件路径
*/
private void getUserData(String dataFile) {
data = new Vector>>();
FileInputStream file_in; // 文件输入流
BufferedReader data_in; // 数据输入流
StringTokenizer stFile;
try {
// 加载数据文件
file_in = new FileInputStream(dataFile);
data_in = new BufferedReader(new InputStreamReader(file_in));
int i = 0;
while (i < numUsers) {
// 获取序列
Vector> sequence = new Vector>();
while (true) {
stFile = new StringTokenizer(data_in.readLine(), itemSep);
if (stFile.countTokens() == 0) {
break;
} else {
// 获取序列中的事件桶
Vector basket = new Vector();
while (stFile.hasMoreTokens()) {
// 获取事件桶中的事件并添加
String item = stFile.nextToken();
basket.add(item);
}
// 添加到序列
sequence.add(basket);
}
}
// 添加到事务集
data.add(sequence);
i++;
}
}
catch (IOException e) {
System.out.println(e);
}
}
/**
* 获取配置
* 暂时只包括用户个数
* @param configFile 配置文件路径
*/
private void getConfig(String configFile) {
try {
FileInputStream file_in = new FileInputStream(configFile);
BufferedReader data_in = new BufferedReader(new InputStreamReader(file_in));
// 事务(用户)数
numUsers = Integer.valueOf(data_in.readLine()).intValue();
// 输出到控制台
System.out.print("\n " + numUsers + " users, ");
System.out.println();
// 输出测试 事务数
// output(numTransactions + "\n");
} catch (IOException e) {
System.out.println(e);
}
}
} 输出给图谱计算器类的是每个用户匹配到的频繁序列的编号,但是这个效果就不是太好:
![]()
五个数据就匹配到一个。不过这是有道理的,我的频繁序列就拿他们生成的,那么他们几个肯定已经学到序列的尽头了,再加上每个人都有自己的独特学习兴趣,用最近事件集匹配不到不足为奇。这个应该是给没有学完的人来推荐学习路径的,也很符合我们的认知。
所以我在考虑给匹配不到学习路径的人推荐其他相关课程,比如推荐最近学习较多的事件在图中相连且未被该用户学习过的频繁度最高的事件之类的,或者应用比较传统的协同过滤,这个明后天再说吧。