环境搭建
案例为Google TensorFlow Demo
影评分为“正面”或“负面”影评。这是一个二元分类(又称为两类分类)的示例,也是一种重要且广泛适用的机器学习问题
案例使用的是 tf.keras,它是一种用于在 TensorFlow 中构建和训练模型的高阶 API
下载 IMDB 数据集
TensorFlow 中包含 IMDB 数据集。google已对该数据集进行了预处理,将影评(字词序列)转换为整数序列,其中每个整数表示字典中的一个特定字词。
以下代码会将 IMDB 数据集下载到你的计算机上(如果您已下载该数据集,则会使用缓存副本)
准备数据
影评(整数数组)必须转换为张量,然后才能馈送到神经网络中。可以通过以下两种方法实现这种转换:
对数组进行独热编码,将它们转换为由 0 和 1 构成的向量。例如,序列 [3, 5] 将变成一个 10000 维的向量,除索引 3 和 5 转换为 1 之外,其余全转换为 0。然后,将它作为网络的第一层,一个可以处理浮点向量数据的密集层。这种方法会占用大量内存,需要一个大小为
num_words * num_reviews的矩阵。或者,我们可以填充数组,使它们都具有相同的长度,然后创建一个形状为
max_length * num_reviews的整数张量。我们可以使用一个能够处理这种形状的嵌入层作为网络中的第一层。
在本教程中,用第二种方法。
由于影评的长度必须相同,我们将使用 pad_sequences 函数将长度标准化:
构建模型
神经网络通过堆叠层创建而成,这需要做出两个架构方面的主要决策:
要在模型中使用多少个层?
要针对每个层使用多少个隐藏单元?
在本示例中,输入数据由字词-索引数组构成。要预测的标签是 0 或 1。
接下来,为此问题构建一个模型
按顺序堆叠各个层以构建分类器:
第一层是 Embedding 层。该层会在整数编码的词汇表中查找每个字词-索引的嵌入向量。模型在接受训练时会学习这些向量。这些向量会向输出数组添加一个维度。生成的维度为:(batch, sequence, embedding)。
接下来,一个 GlobalAveragePooling1D 层通过对序列维度求平均值,针对每个样本返回一个长度固定的输出向量。这样,模型便能够以尽可能简单的方式处理各种长度的输入。
该长度固定的输出向量会传入一个全连接 (Dense) 层(包含 16 个隐藏单元)。
最后一层与单个输出节点密集连接。应用 sigmoid 激活函数后,结果是介于 0 到 1 之间的浮点值,表示概率或置信水平。
隐藏单元
上述模型在输入和输出之间有两个中间层(也称为“隐藏”层)。输出(单元、节点或神经元)的数量是相应层的表示法空间的维度。换句话说,该数值表示学习内部表示法时网络所允许的自由度。
如果模型具有更多隐藏单元(更高维度的表示空间)和/或更多层,则说明网络可以学习更复杂的表示法。不过,这会使网络耗费更多计算资源,并且可能导致学习不必要的模式(可以优化在训练数据上的表现,但不会优化在测试数据上的表现)。这称为过拟合,稍后会加以探讨。
损失函数和优化器
模型在训练时需要一个损失函数和一个优化器。由于这是一个二元分类问题且模型会输出一个概率(应用 S 型激活函数的单个单元层),因此将使用 binary_crossentropy 损失函数。
该函数并不是唯一的损失函数,例如,可以选择 mean_squared_error。但一般来说,binary_crossentropy 更适合处理概率问题,它可测量概率分布之间的“差距”,在本例中则为实际分布和预测之间的“差距”。
稍后,在探索回归问题(比如预测房价)时,将了解如何使用另一个称为均方误差的损失函数。
现在,配置模型以使用优化器和损失函数:
验证集
在训练时需要检查模型处理从未见过的数据的准确率。我们从原始训练数据中分离出 10000 个样本,创建一个验证集。(为什么现在不使用测试集?我们的目标是仅使用训练数据开发和调整模型,然后仅使用一次测试数据评估准确率)
训练模型
用有 512 个样本的小批次训练模型 40 个周期。这将对 x_train 和 y_train 张量中的所有样本进行 40 次迭代。在训练期间,监控模型在验证集的 10000 个样本上的损失和准确率:
评估模型
看看模型的表现如何。模型会返回两个值:损失(表示误差的数字,越低越好)和准确率
code
import tensorflow as tf
from tensorflow import keras
import numpy as np
print(tf.__version__)
#TensorFlow 中包含 IMDB 数据集。
#google已对该数据集进行了预处理,将影评(字词序列)转换为整数序列,其中每个整数表示字典中的一个特定字词。
#以下代码会将 IMDB 数据集下载到你的计算机上(如果您已下载该数据集,则会使用缓存副本)
imdb = keras.datasets.imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
#了解下数据
print("Training entries: {}, labels: {}".format(len(train_data), len(train_labels)))
print(train_data[0])
len(train_data[0]), len(train_data[1])
#创建一个辅助函数来查询包含整数到字符串映射的字典对象
word_index = imdb.get_word_index()
word_index = {k:(v+3) for k,v in word_index.items()}
word_index[""] = 0
word_index[""] = 1
word_index[""] = 2 # unknown
word_index[""] = 3
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
def decode_review(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])
#整数数组)必须转换为张量,然后才能馈送到神经网络中
train_data = keras.preprocessing.sequence.pad_sequences(train_data,
value=word_index[""],
padding='post',
maxlen=256)
test_data = keras.preprocessing.sequence.pad_sequences(test_data,
value=word_index[""],
padding='post',
maxlen=256)
#样本长度
len(train_data[0]), len(train_data[1])
#打印第一条
print(train_data[0])
#构建模型
vocab_size = 10000
model = keras.Sequential()
model.add(keras.layers.Embedding(vocab_size, 16))
model.add(keras.layers.GlobalAveragePooling1D())
model.add(keras.layers.Dense(16, activation=tf.nn.relu))
model.add(keras.layers.Dense(1, activation=tf.nn.sigmoid))
model.summary()
#配置模型以使用优化器和损失函数
model.compile(optimizer=tf.train.AdamOptimizer(),
loss='binary_crossentropy',
metrics=['accuracy'])
#从原始训练数据中分离出 10000 个样本,创建一个验证集
x_val = train_data[:10000]
partial_x_train = train_data[10000:]
y_val = train_labels[:10000]
partial_y_train = train_labels[10000:]
#训练:用有 512 个样本的小批次训练模型 40 个周期。这将对 x_train 和 y_train 张量中的所有样本进行 40 次迭代。在训练期间,监控模型在验证集的 10000 个样本上的损失和准确率
history = model.fit(partial_x_train,
partial_y_train,
epochs=40,
batch_size=512,
validation_data=(x_val, y_val),
verbose=1)
#评估:模型会返回两个值:损失(表示误差的数字,越低越好)和准确率
results = model.evaluate(test_data, test_labels)
print(results)
#创建准确率和损失随时间变化的图
#model.fit() 返回一个 History 对象,该对象包含一个字典,其中包括训练期间发生的所有情况:
history_dict = history.history
history_dict.keys()
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
# "bo" is for "blue dot"
plt.plot(epochs, loss, 'bo', label='Training loss')
# b is for "solid blue line"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
#
plt.clf() # clear figure
acc_values = history_dict['acc']
val_acc_values = history_dict['val_acc']
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
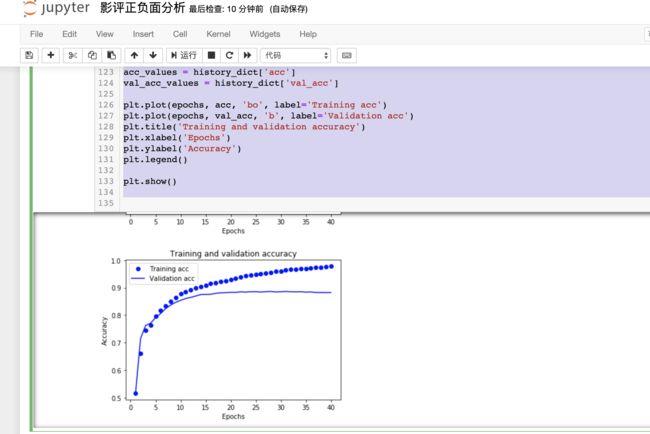
训练结果
- 训练损失随着周期数的增加而降低,训练准确率随着周期数的增加而提高
- 大约 20 个周期后准确率达到峰值
这是一种过拟合现象,过拟合说白了就是:只认识训练过的,没训练过的不认识
为了放置过拟合,一般准确率达到峰值后应该停止训练