本文记录了利用FPGA加速图像处理中的卷积计算的设计与实现。实现环境为Altera公司的Cyclone IV型芯片,NIOS II软核+FPGA架构。
由于这是第一次设计硬件加速模块,设计中的瑕疵以及问题欢迎前来讨论。
更新记录:
- D0423 记录FPGA核心计算模块和控制模块
- D0426 记录FPGA核心计算模块的控制驱动,性能与功能测试
Part1 : 卷积相关
软件实现卷积
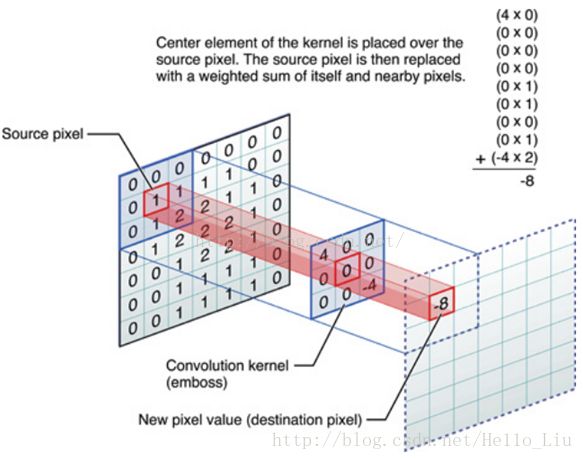
- 卷积是将原来矩阵的对应部分与
卷积核对位乘法再加起来,形成新的矩阵中的一个位。 - 图中红色的框是
卷积操作当前所在位置,对位乘法相加之后得到中间的小红框的值。 - 利用C语言实现核心代码如下
void Conv(int filter[100][100], int arr[100][100], int res[100][100], int filterW, int filterH, int arrW, int arrH){
int temp;
for (int i=0; i1; i++){
for (int j=0; j1; j++){
printf("Start %d %d \n",i,j);
temp = 0;
for (int m=0; mfor (int n=0; nprintf("m %d n %d ",m,n);
if ((i-m)>=0 && (i-m)=0 && (j-n)printf("%d * %d",filter[m][n],arr[i-m][j-n]);
temp += filter[m][n]*arr[i-m][j-n];
}
printf("\n");
}
}
printf("End\n");
res[i][j] = temp;
}
}
} ***********************************************
Filter:
2 1 2
0 5 0
1 3 1
***********************************************
***********************************************
Matrix:
17 24 1 8 15
23 5 7 14 16
4 6 13 20 22
10 12 19 21 3
11 18 25 2 9
***********************************************
***********************************************
Result:
17 75 90 35 40 53 15
23 159 165 45 105 137 16
38 198 120 165 205 197 52
56 95 160 200 245 184 35
19 117 190 255 235 106 53
20 89 160 210 75 90 6
22 47 90 65 70 13 18
*********************************************** 针对具体的(3,4)
Start 3 4
m 0 n 0 1 * 3
m 0 n 1 3 * 21
m 0 n 2 1 * 19
m 1 n 0 0 * 22
m 1 n 1 5 * 20
m 1 n 2 0 * 13
m 2 n 0 2 * 16
m 2 n 1 1 * 14
m 2 n 2 2 * 7
End硬件实现思路和可能的加速
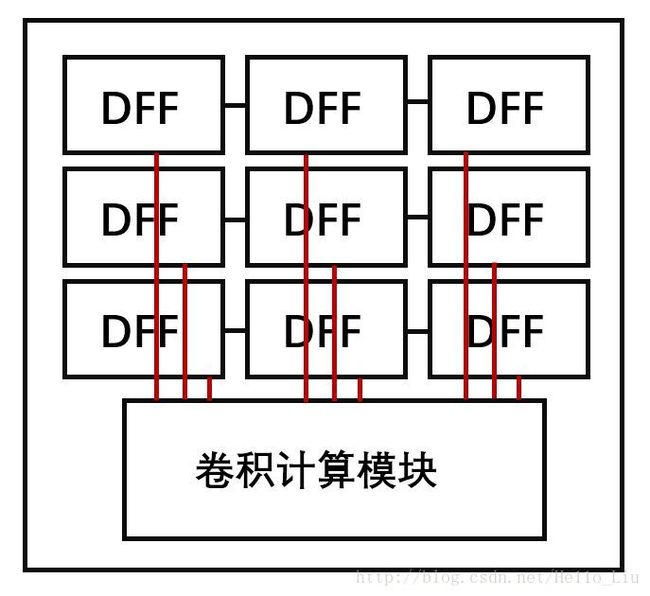
- 这是一个卷积处理单元的顶层图。
- 还是同滑动窗口思路类似,右边三位输入为控制器,使得该处理单元在3行上向右滑动。
- 不同于软件实现,这里的乘法底层应该是查找表实现的,所有9个DFF的乘法,可以并行计算。
- 计算结构用最下面的加法模块加上后输出当前位。
- 这个加法可能会通过拆分加优化(加法树之类)
最简单的实现就是将这个模块运算玩一行后继续算下一行。但是这样没有充分利用这些数据不相关的特性,有两种思路。
- 一个是如上图多放几个卷积模块
- 另一个是通过级联将
3*3的卷积模块扩大 比如说6*6的,可以通过4个3*3的处理模块级联实现。具体多大,和板子资源和具体矩阵尺寸有关。这个还要再考虑。
与软件比较
3*3处理模块中软件9个乘法串行,这里并行。- 多个级联后可以达到
36或者更高的优化
Part2 : FPGA卷积核心计算模块
Convolution Calculate Moudle
该模块是卷积计算的核心模块,模块顶层图如下:
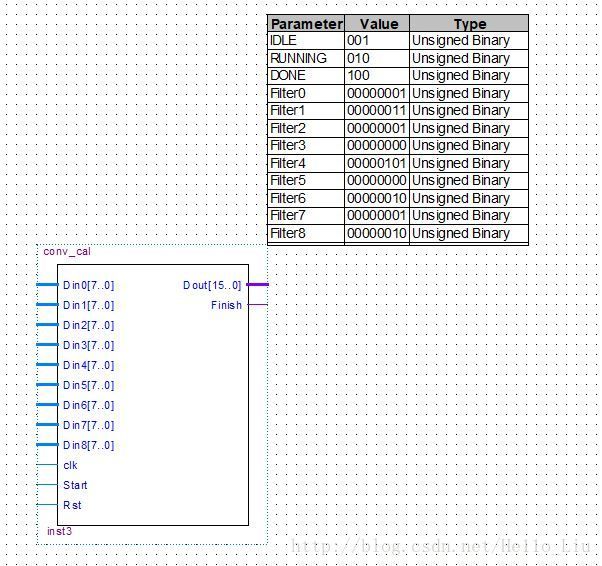
输入输出端口说明
Din0 ~ Din8 是当前计算矩阵3*3的输入
参数Filter0 ~ Filter8 是卷积核3*3的参数。这里不选择动态输入是为了FPGA构造更小的LUT
Start和Rst是该模块的控制输入
Finish是该模块的完成输出,可以作为中断信号。
防止溢出,这里Dout给的16位
详细设计与分析
该模块包含一个自动机,用于跟踪计算状态,提供与上层同步的时序依据。
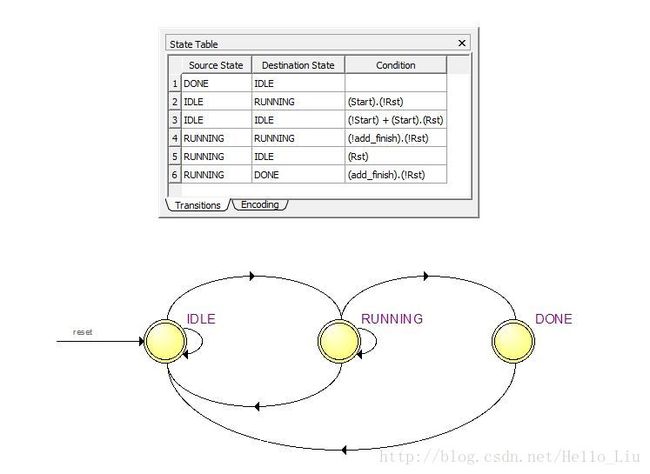
在RUNING过程中包括两个子状态,用于并行计算乘与并行计算加,利用两个变量来控制。
该模块在Quartus 13的RTL如下:
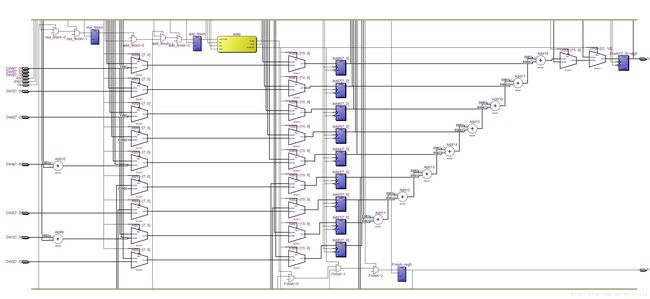
虽然看起来加法链那里由于没有优化拉的很长,但是由于与时序无关,下一个时钟周期来的时候计算一定会完成,所以没有太大影响。
测试该模块
书写Test Bench仿真测试
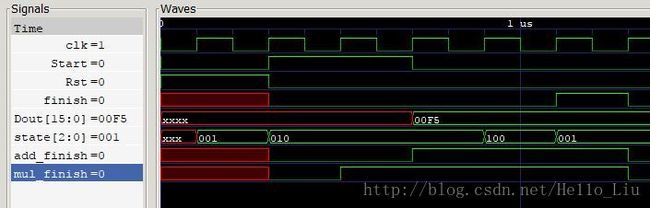
利用NIOS II 软核测试
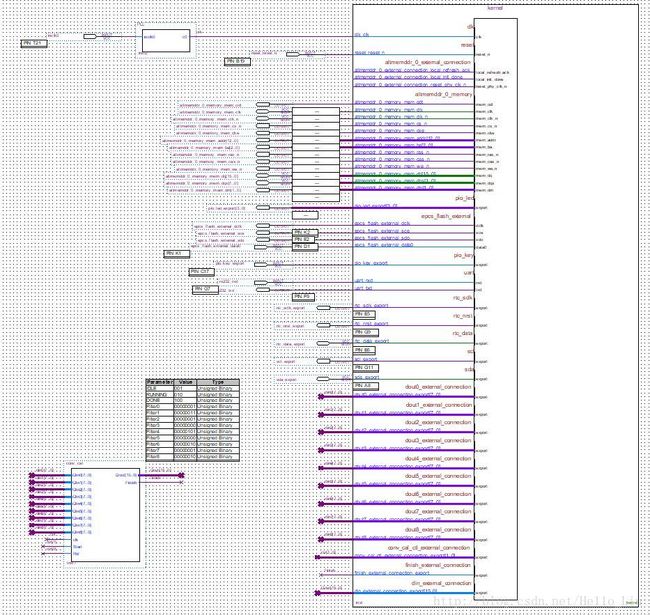
烧录Cyclone IV JTAG输出测试
测试程序如下:
#include JTAG 输出
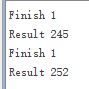
存在问题 下版本优化
- 从设计上来说 三个周期就已经可以输出结果了,当前状态机导致到了第五个时钟周期才通知取结果,状态机需要稍微优化一下。
- 设计上一层分配
3*3矩阵输入拆分模块时,状态能和当前状态机配合,甚至可以达到流水线的状态。
第二版本
第二版本相较于第一版本,将所有的非时序部分统一在一个时钟周期内完成。
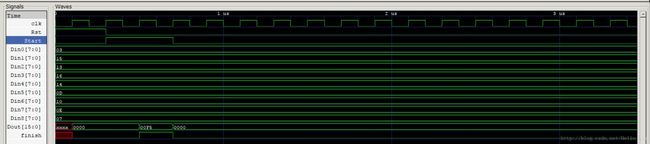
综合实现RTL如下:
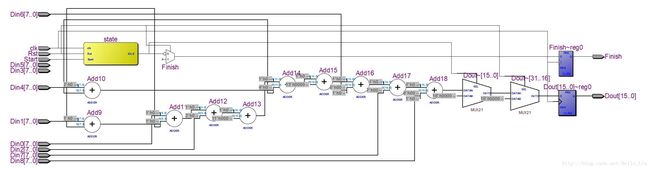
简化后的状态机为
Part3 : FPGA卷积计算控制模块&驱动
如何使用FPGA的卷积计算模块有两种思路
- 一个是直接利用FPGA实现对内存的读取控制
- 一个是利用AXI总线直接用上的模块
FPGA通过内存读写
先尝试第一种方法。开发难度非常大,最后写出来的模块也非常复杂。
由于本人第一次尝试设计一个功能模块,状态机中间可能有容易时钟周期,仅用于示意。状态图如下:
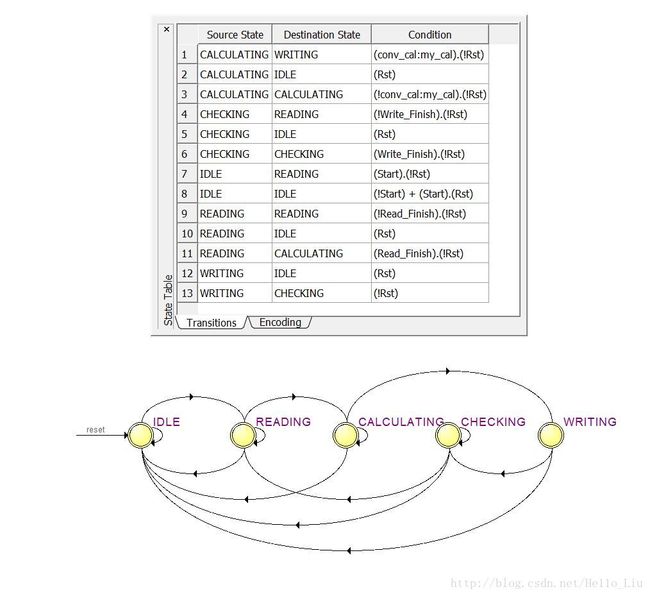
设计大体思路如下:
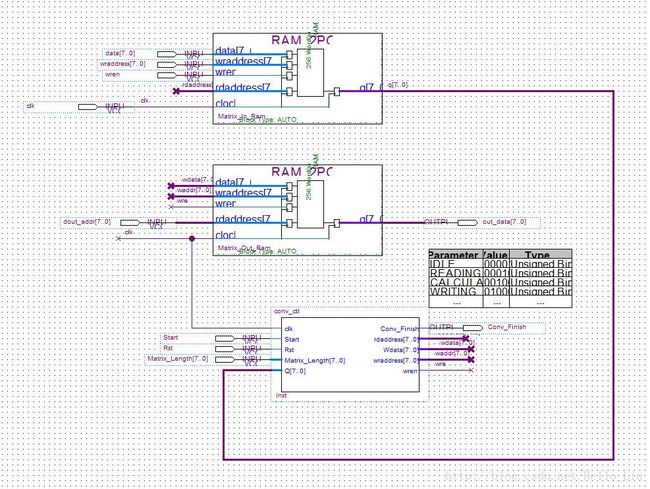
两个单向读取写入RAM分别用作
- PS部分写入矩阵,PL部分读取处理
- PL部分写入处理结果,PS部分读取结果
边界情况暂时略去。
波形仿真截取开始和结束
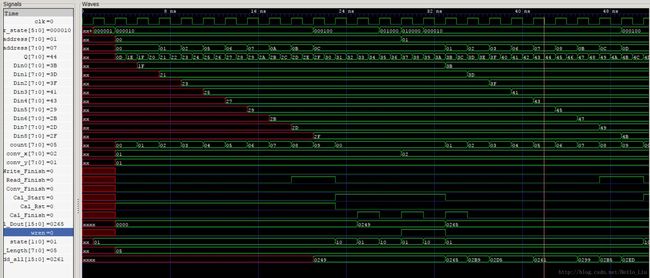
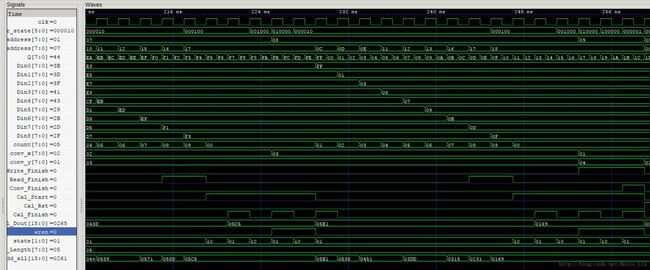
变量顾名思义,具体时序设计见代码。
生成RTL的实际电路如下:
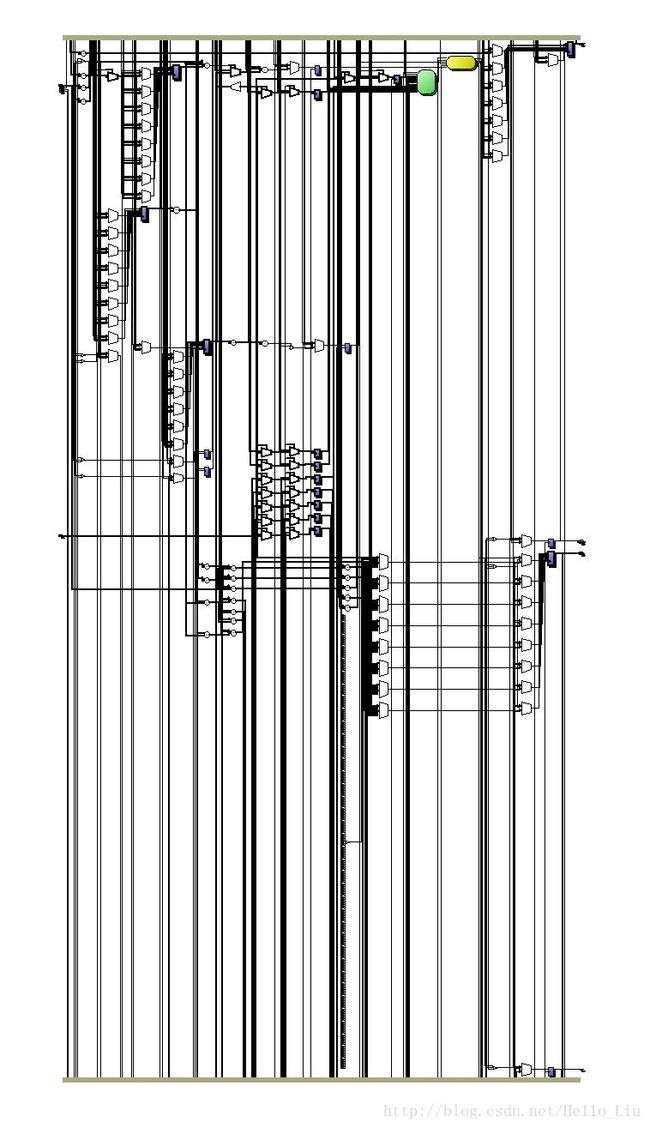
其中绿色部分才是最核心的加速模块。
在设计过程中,很明显发现这样设计的特点:
FPGA真的不适合表达串行逻辑,或者逻辑复杂的时候,需要精心设计状态机。
下面是两张综合后所用资源的图
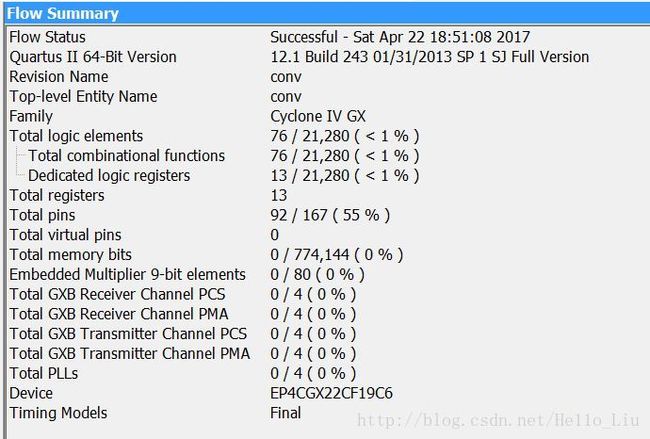
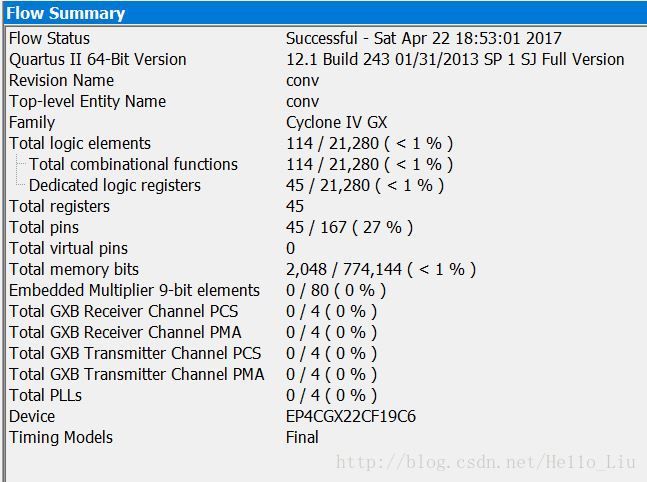
上面一张是核心模块综合后的资源图,下面一张是利用内存之后的占用的资源图。
直接核心与PL交互的话输出端口占用比较多,而利用内存进行交互占用比较少。
这一点可以将核心模块的并行输入改为串行输入降低核心模块直接交互的端口数。
代码不容易维护,扩展性极差。
实际速度不好说,只有大约2/13的时钟周期在进行计算。这一点和直接利用PS核IO口传数据过来的速度比较可能优势也不大。
通过IO口读写
基本思路同上面写的软核测试类似。主要考虑两点
- 并行输入该串行,IO口节约,或者写一个中间模块通过AXI总线交互的
- 实际是将每次的9个乘法和一个加法优化到硬件部分实现
同样是上面的NIOS II工程,先利用软核软件实现:
void Conv_SW(int filter[100][100], int arr[100][100],int filterW, int filterH, int arrW, int arrH) {
int temp;
int i, j, m, n;
for (i = 2; i < filterH + arrH - 3; i++) {
for (j = 2; j < filterW + arrW - 3; j++) {
temp = 0;
for (m = 0; m < filterH; m++) {
for (n = 0; n < filterW; n++) {
if ((i - m) >= 0 && (i - m) < arrH && (j - n) >= 0
&& (j - n) < arrW) {
temp += filter[m][n] * arr[i - m][j - n];
}
}
}
res[i][j] = temp;
}
if(i % 50 == 0) printf("=");
}
}然后是FPGA模块硬件驱动:
/**
* 卷积硬件驱动示例
* 将结果保存到全局变量res
*/
void Conv_HW(int filter[100][100], int arr[100][100],int filterW, int filterH, int arrW, int arrH) {
int i, j;
IOWR_ALTERA_AVALON_PIO_DATA(CONV_CAL_CTL_BASE, 0x1);
for (i = 2; i < filterH + arrH - 3; i++) {
for (j = 2; j < filterW + arrW - 3; j++) {
IOWR_ALTERA_AVALON_PIO_DATA(DOUT0_BASE, arr[i][j]);
IOWR_ALTERA_AVALON_PIO_DATA(DOUT1_BASE, arr[i][j-1]);
IOWR_ALTERA_AVALON_PIO_DATA(DOUT2_BASE, arr[i][j-2]);
IOWR_ALTERA_AVALON_PIO_DATA(DOUT3_BASE, arr[i-1][j]);
IOWR_ALTERA_AVALON_PIO_DATA(DOUT4_BASE, arr[i-1][j-1]);
IOWR_ALTERA_AVALON_PIO_DATA(DOUT5_BASE, arr[i-1][j-2]);
IOWR_ALTERA_AVALON_PIO_DATA(DOUT6_BASE, arr[i-2][j]);
IOWR_ALTERA_AVALON_PIO_DATA(DOUT7_BASE, arr[i-2][j-1]);
IOWR_ALTERA_AVALON_PIO_DATA(DOUT8_BASE, arr[i-2][j-2]);
IOWR_ALTERA_AVALON_PIO_DATA(CONV_CAL_CTL_BASE, 0x2);
while ((IORD_ALTERA_AVALON_PIO_DATA(FINISH_BASE) & 0x01) == 0)
;
res[i][j] = IORD_ALTERA_AVALON_PIO_DATA(DIN_BASE);
}
if(i % 50 == 0) printf("=");
}
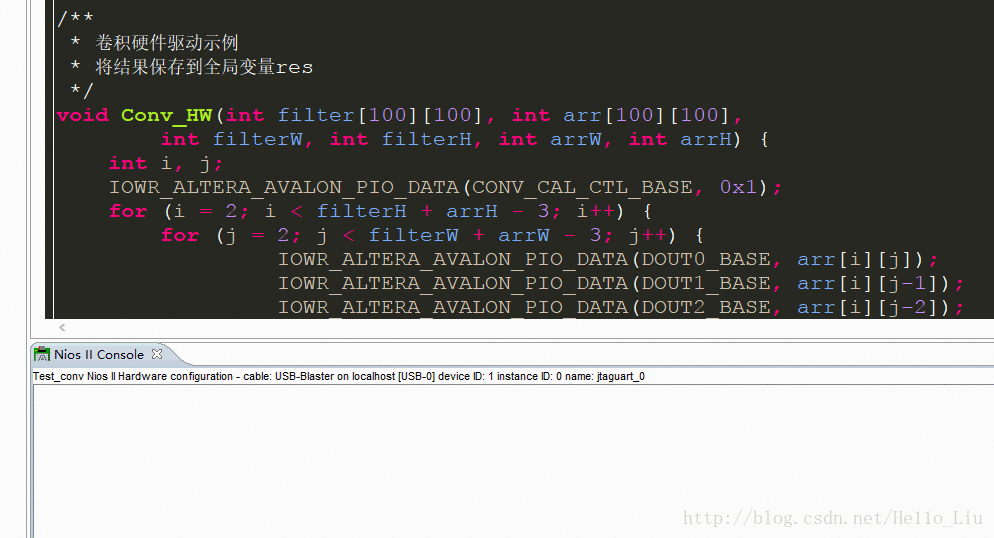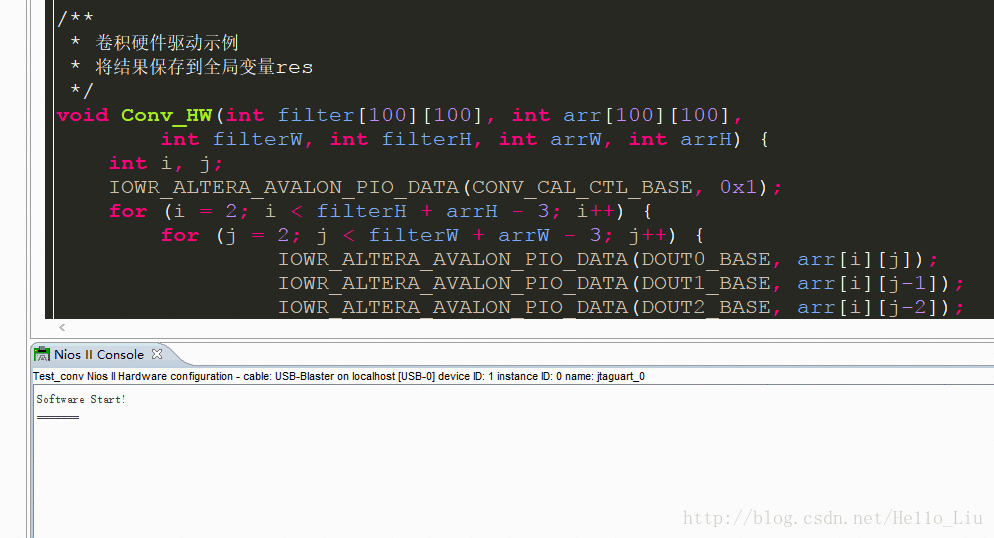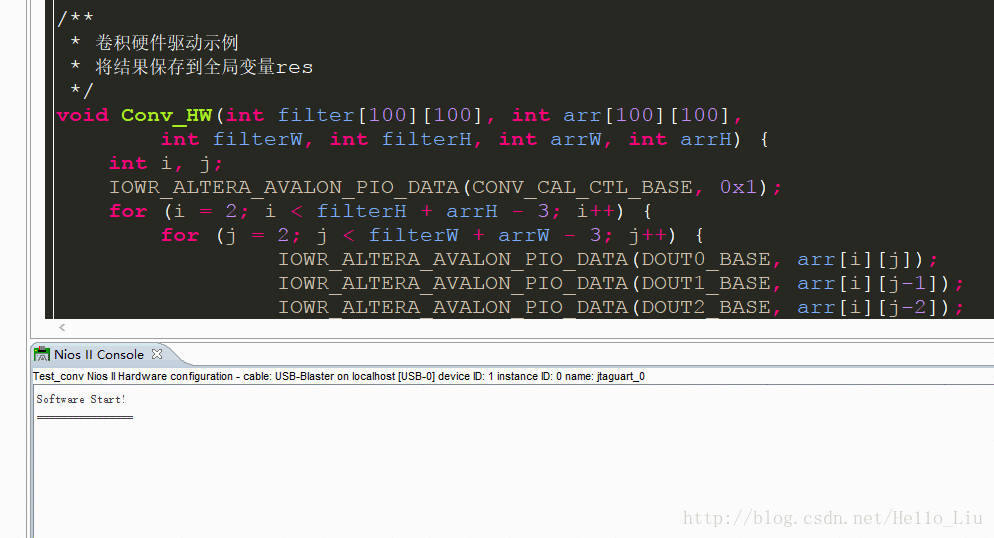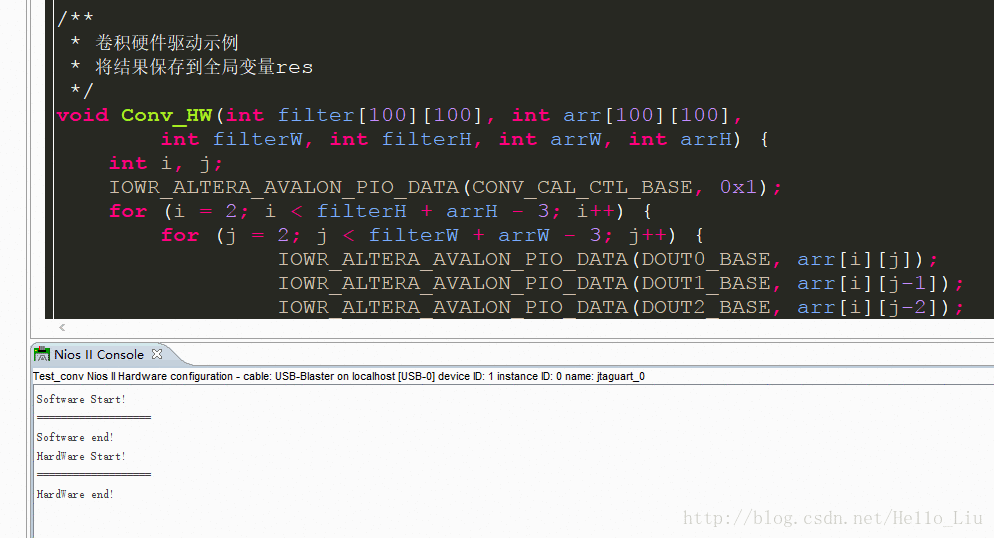
}主函数针对性能和功能进行测试。由于NIOS II无法获取Time,故直接将进度输出。(软件大致16s完成对500*500的矩阵计算,硬件大致3s完成相同计算)
void Conv_SW(int filter[100][100], int arr[100][100],
int filterW, int filterH, int arrW, int arrH);
void Conv_HW(int filter[100][100], int arr[100][100],
int filterW, int filterH, int arrW, int arrH);
int res[1000][1000];
int main() {
int filterW = 3;
int filterH = 3;
int arrW = 5;
int arrH = 5;
int resW = filterW + arrW - 1;
int resH = filterH + arrH - 1;
int i, j;
int pFilter[100][100];
int arr[100][100];
pFilter[0][0] = 1;
pFilter[0][1] = 3;
pFilter[0][2] = 1;
pFilter[1][0] = 0;
pFilter[1][1] = 5;
pFilter[1][2] = 0;
pFilter[2][0] = 2;
pFilter[2][1] = 1;
pFilter[2][2] = 2;
#ifdef TestSpeed
arrW = 500;
arrH = 500;
resH = filterH + arrH - 1;
resW = filterW + arrW - 1;
printf("Software Start!\n");
Conv_SW(pFilter, arr, filterW, filterH, arrW, arrH);
printf("\nSoftware end!\n");
printf("HardWare Start!\n");
Conv_HW(pFilter, arr, filterW, filterH, arrW, arrH);
printf("\nHardWare end!");
#else
srand(10);
arrW = 20;
arrH = 20;
resH = filterH + arrH - 1;
resW = filterW + arrW - 1;
for(i = 0; i < arrH; i++){
for(j = 0; j< arrW;j++){
arr[i][j] = rand()%20;
}
}
printf("*********************************************** \n");
printf("Filter: \n");
for (i = filterH - 1; i >= 0; i--) {
for (j = filterW - 1; j >= 0; j--) {
printf("%d ", pFilter[i][j]);
}
printf("\n");
}
printf("*********************************************** \n");
printf("Matrix: \n");
for (i = 0; i < arrH; i++) {
for (j = 0; j < arrW; j++) {
printf("%4d ", arr[i][j]);
}
printf("\n");
}
printf("*********************************************** \n");
printf("Software Start!\n");
Conv_SW(pFilter, arr, filterW, filterH, arrW, arrH);
printf("\nSoftware end!\n");
printf("*********************************************** \n");
printf("Result1: \n");
for (i = 0; i < resH; i++) {
for (j = 0; j < resW; j++) {
printf("%5d ", res[i][j]);
}
printf("\n");
}
for (i = 0; i < resH; i++) {
for (j = 0; j < resW; j++) {
res[i][j] = 0;
}
}
printf("*********************************************** \n");
printf("HardWare Start!\n");
Conv_HW(pFilter, arr, filterW, filterH, arrW, arrH);
printf("\nHardWare end!");
printf("Result2: \n");
for (i = 0; i < resH; i++) {
for (j = 0; j < resW; j++) {
printf("%5d ", res[i][j]);
}
printf("\n");
}
printf("*********************************************** \n");
#endif
return 0;
}由于是示例驱动,这里忽略对四周的处理:

300*300 速度示例
附录 FPGA 部分源代码
通过IO口读写
基本思路同上面写的软核测试类似。主要考虑两点
- 并行输入该串行,IO口节约,或者写一个中间模块通过AXI总线交互的
- 实际将4重循环优化到了两重循环。
- 测试驱动下周写一个例子
控制模块源代码
module conv_ctl(
//控制信号输入输出
clk,Start,Rst,Matrix_Length,Conv_Finish,
//连接读取数据RAM
Q,rdaddress,
//连接写入数据RAM
Wdata,wraddress,wren);
//控制信号输入输出
input clk,Start,Rst;
input [7:0] Matrix_Length;
output reg Conv_Finish;
//连接读取数据RAM
input [7:0] Q;
output reg [7:0] rdaddress;
//连接写入数据RAM
output [7:0] Wdata;
output reg [7:0] wraddress;
output reg wren;
//连接conv_cal
// input[15:0] Cal_Dout;
// input Cal_Finish;
wire [15:0] Cal_Dout;
wire Cal_Finish;
reg [7:0] Din0,Din1,Din2,Din3,Din4,Din5,Din6,Din7,Din8;
reg Cal_Start;
reg Cal_Rst;
//状态机
reg [5:0] cur_state,nxt_state;
parameter IDLE = 6'b000001;
parameter READING = 6'b000010;
parameter CALCULATING = 6'b000100;
parameter WRITING = 6'b001000;
parameter CHECKING = 6'b010000;
parameter FINISH = 6'b100000;
//辅助参数
reg Read_Finish;
reg Write_Finish;
reg [7:0] count,conv_x,conv_y;
//调用模块
conv_cal_2 my_cal(Cal_Dout,Din0,Din1,Din2,Din3,Din4,Din5,Din6,Din7,Din8,clk,Cal_Start,Cal_Rst,Cal_Finish);
//状态自动转移
always@(posedge clk)
begin
if(Rst)
cur_state <= IDLE;
else
cur_state <= nxt_state;
end
//状态转移条件
always@(cur_state or Start or Cal_Finish or Rst or Read_Finish or Write_Finish)
begin
if(Rst)
nxt_state = IDLE;
else
begin
case(cur_state)
IDLE:nxt_state = Start?READING:IDLE;
READING:nxt_state = Read_Finish?CALCULATING:READING;
CALCULATING:nxt_state = Cal_Finish?WRITING:CALCULATING;
WRITING: nxt_state = CHECKING;
CHECKING: nxt_state = Write_Finish?FINISH:READING;
FINISH: nxt_state = IDLE;
default: nxt_state = IDLE;
endcase
end
end
//状态动作
always@(posedge clk)
begin:b1
case(cur_state)
IDLE:
begin
Read_Finish = 1'b0;
Write_Finish = 1'b0;
count = 0;
conv_x = 1;
conv_y = 1;
Cal_Start = 1'b0;
Cal_Rst = 1'b1;
wraddress = 8'd0;
rdaddress = 8'd0;
wren = 1'b0;
Conv_Finish = 1'b0;
end
READING:
begin
wren = 1'b0;
Cal_Start = 1'b0;
//根据count对3*3输入进行赋值
case(count)
0:
begin
Din0 = Q;
rdaddress = conv_x - 1 + (conv_y-1) * Matrix_Length;
end
1:
begin
Din1 = Q;
rdaddress = conv_x + (conv_y-1) * Matrix_Length;
end
2:
begin
Din2 = Q;
rdaddress = conv_x + 1 + (conv_y-1) * Matrix_Length;
end
3:
begin
Din3 = Q;
rdaddress = conv_x - 1 + conv_y * Matrix_Length;
end
4:
begin
Din4 = Q;
rdaddress = conv_x + conv_y * Matrix_Length;
end
5:
begin
Din5 = Q;
rdaddress = conv_x + 1 + conv_y * Matrix_Length;
end
6:
begin
Din6 = Q;
rdaddress = conv_x - 1 + (conv_y+1) * Matrix_Length;
end
7:
begin
Din7 = Q;
rdaddress = conv_x + (conv_y+1) * Matrix_Length;
end
8:
begin
Din8 = Q;
rdaddress = conv_x + 1 + (conv_y+1) * Matrix_Length;
end
endcase
count = count + 7'd1;
if(count == 7'd8)
Read_Finish = 1'b1;
end
CALCULATING:
begin
Read_Finish = 1'b0;
count = 0;
Cal_Rst = 1'b0;
Cal_Start = 1'b1;
end
WRITING:
begin
wren = 1'b1;
if(conv_x == Matrix_Length - 2) //
begin
conv_x = 1;
conv_y = conv_y + 1;
end
else
begin
conv_x = conv_x + 1;
end
wraddress = wraddress + 1; //!!!这句话可能有问题
if(conv_y == Matrix_Length - 1) //
begin
Write_Finish = 1'b1;
end
else
begin
Write_Finish = 1'b0;
end
end
FINISH:
begin
Conv_Finish = 1'b1;
end
endcase
end
endmodule核心计算模块 版本一
module conv_cal (Dout,Din0,Din1,Din2,Din3,Din4,Din5,Din6,Din7,Din8,clk,Start,Rst,Finish);
input [7:0] Din0,Din1,Din2,Din3,Din4,Din5,Din6,Din7,Din8;
input clk;
input Start;
input Rst;
output reg [15:0] Dout;
output reg Finish;
reg [7:0] Add0,Add1,Add2,Add3,Add4,Add5,Add6,Add7,Add8;
reg [2:0] state;
reg mul_finish;
reg add_finish;
parameter IDLE = 3'b001;
parameter RUNNING = 3'b010;
parameter DONE = 3'b100;
//Convolution Kernel
parameter Filter0 = 8'd1;
parameter Filter1 = 8'd3;
parameter Filter2 = 8'd1;
parameter Filter3 = 8'd0;
parameter Filter4 = 8'd5;
parameter Filter5 = 8'd0;
parameter Filter6 = 8'd2;
parameter Filter7 = 8'd1;
parameter Filter8 = 8'd2;
always@(posedge clk)
begin
if(Rst)
begin
state <= IDLE;
end
else
case(state)
IDLE: state <= Start ? RUNNING:IDLE;
RUNNING:
begin
if(add_finish == 1)
begin
state <= DONE;
Finish <= 1'b1;
end
else
state <= RUNNING;
end
DONE :
begin
Finish <= 1'b0;
state <= IDLE;
end
default : state <= IDLE;
endcase
end
always@(posedge clk)
begin
if(state == IDLE)
begin
mul_finish <= 1'b0;
add_finish <= 1'b0;
Finish <= 1'b0;
end
else if(state == RUNNING)
begin
if(!mul_finish)
begin
Add0 <= Din0 * Filter0;
Add1 <= Din1 * Filter1;
Add2 <= Din2 * Filter2;
Add3 <= Din3 * Filter3;
Add4 <= Din4 * Filter4;
Add5 <= Din5 * Filter5;
Add6 <= Din6 * Filter6;
Add7 <= Din7 * Filter7;
Add8 <= Din8 * Filter8;
mul_finish <= 1;
end
else
begin
Dout <= Add0+Add1+Add2+Add3+Add4+Add5+Add6+Add7+Add8;
add_finish <= 1;
end
end
end
endmodule核心计算模块 版本二
module conv_cal_2 (Dout,Din0,Din1,Din2,Din3,Din4,Din5,Din6,Din7,Din8,clk,Start,Rst,Finish);
input [7:0] Din0,Din1,Din2,Din3,Din4,Din5,Din6,Din7,Din8;
input clk;
input Start;
input Rst;
output reg [15:0] Dout;
output reg Finish;
wire [7:0] Add0,Add1,Add2,Add3,Add4,Add5,Add6,Add7,Add8;
wire [15:0] Add_all;
reg [1:0] state;
parameter IDLE = 2'b01;
parameter DONE = 2'b10;
//Convolution Kernel
parameter Filter0 = 8'd1;
parameter Filter1 = 8'd3;
parameter Filter2 = 8'd1;
parameter Filter3 = 8'd0;
parameter Filter4 = 8'd5;
parameter Filter5 = 8'd0;
parameter Filter6 = 8'd2;
parameter Filter7 = 8'd1;
parameter Filter8 = 8'd2;
assign Add0 = Din0 * Filter0;
assign Add1 = Din1 * Filter1;
assign Add2 = Din2 * Filter2;
assign Add3 = Din3 * Filter3;
assign Add4 = Din4 * Filter4;
assign Add5 = Din5 * Filter5;
assign Add6 = Din6 * Filter6;
assign Add7 = Din7 * Filter7;
assign Add8 = Din8 * Filter8;
assign Add_all = Add0+Add1+Add2+Add3+Add4+Add5+Add6+Add7+Add8;
always@(posedge clk )
begin
if(Rst)
begin
state <= IDLE;
Finish <= 1'b0;
Dout <= 16'b0;
end
else
case(state)
IDLE:
begin
Finish <= 1'b0;
if(Start)
begin
state <= DONE;
end
else
state <= IDLE;
end
DONE :
begin
Finish <= 1'b1;
state <= IDLE;
Dout <= Add_all;
end
default : state <= IDLE;
endcase
end
endmodule