线搜索中有最速下降法、牛顿法、拟牛顿法、共轭梯度法汇总
最速下降法利用目标函数一阶梯度进行下降求解,易产生锯齿现象,在快接近最小值时收敛速度慢。Newton法利用了二阶梯度,收敛速度快,但是目标函数的Hesse矩阵不一定正定。于是出现了修正的Newton法,主要是对不同情况进行了分情况讨论。Newton法的优缺点都很突出。优点:高收敛速度(二阶收敛);缺点:对初始点、目标函数要求高,计算量、存储量大(需要计算、存储Hesse矩阵及其逆)。拟Newton法是模拟Newton法给出的一个保优去劣的算法。共轭梯度法是介于最速下降法和牛顿法之间的一个方法,相比最速下降法收敛速度快,并且不需要像牛顿法一样计算Hesse矩阵,只需计算一阶导数(共轭梯度法是共轭方向法的一种,意思是搜索方向都互相共轭)。
最速下降法
最速下降法是最早的求解多元函数极值的数值方法。它直观、简单。它的缺点是,收敛速度较慢、实用性差。在点 x k x_{k} xk处,沿什么方向寻找下一个迭代点呢?显然应该沿下降方向。一个非常直观的想法就是沿最速下降方向,即负梯度方向: p k = − ∇ f ( x k ) p_{k}=-\nabla f(x_{k}) pk=−∇f(xk)。

沿 p k p_{k} pk方向进行直线搜索,由此确定下一个点的位置 x k + 1 = x k − t k ∇ f ( x k ) x_{k+1} = x_{k} - t_{k}\nabla f(x_{k}) xk+1=xk−tk∇f(xk),我们将 t k t_{k} tk称为步长因子,满足以下等式:
f ( x k − t k ∇ f ( x k ) ) = min t f ( x k − t ∇ f ( x k ) ) f\left(x_{k}-t_{k} \nabla f\left(x_{k}\right)\right)=\min _{t} f\left(x_{k}-t \nabla f\left(x_{k}\right)\right) f(xk−tk∇f(xk))=tminf(xk−t∇f(xk))
简单合记为:
x k + 1 = l s ( x k , − ∇ f ( x k ) ) x_{k+1}=l s\left(x_{k},-\nabla f\left(x_{k}\right)\right) xk+1=ls(xk,−∇f(xk))
为了书写方便,以后记 g k = g ( x k ) = ∇ f ( x k ) g_{k}=g(x_{k})=\nabla f(x_{k}) gk=g(xk)=∇f(xk)。
到这里,我们已经大概知道最速下降法是怎么工作的,那这个步长因子 t k t_{k} tk到底怎么求呢?,我们考虑特殊情况,假设我们的目标函数是正定二次函数:
f ( x ) = 1 2 x T Q x + b T x + c f(x)=\frac{1}{2} x^{T} Q x+b^{T} x+c f(x)=21xTQx+bTx+c
目标函数对 x x x的一阶梯度:
g ( x ) = Q x + b g(x)=Qx+b g(x)=Qx+b
这里引入一个定理,之后的求解就是依据这个定理的等式进行求解:
定理:设目标函数 f ( x ) f(x) f(x)具有一阶连续偏导数,若 z = l s ( x , p ) z=ls(x,p) z=ls(x,p),则 ∇ f ( z ) T p = 0 \nabla f(z)^{T}p=0 ∇f(z)Tp=0。
依据定理,我们可以得到 g k + 1 ⋅ g k = 0 g_{k+1}·g_{k}=0 gk+1⋅gk=0。由此有:
g k + 1 ⋅ g k = [ Q ( x k − t k g k ) + b ] T g ( k ) = 0 = [ Q x k + b − t k Q g k ] T g ( k ) = 0 = [ g k − t k Q g k ] T g ( k ) = 0 \begin{aligned} g_{k+1}·g_{k} & = [Q(x_{k}-t_{k}g_{k})+b]^{T}g(k)=0 \\ & = [Qx_{k}+b - t_{k}Qg_{k}]^{T}g(k)=0 \\ & = [g_{k}-t_{k}Qg_{k}]^{T}g(k)=0 \end{aligned} gk+1⋅gk=[Q(xk−tkgk)+b]Tg(k)=0=[Qxk+b−tkQgk]Tg(k)=0=[gk−tkQgk]Tg(k)=0
由此,可求解出 t k t_{k} tk:
t k = g k T g k g k T Q g k t_{k}=\frac{g_{k}^{T}g_{k}}{g_{k}^{T}Qg_{k}} tk=gkTQgkgkTgk
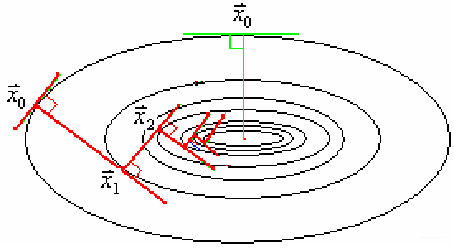
最速下降法的迭代点在向极小点靠近的过程中,走的是曲折的路线:后一次搜索方向 p k + 1 p_{k+1} pk+1与前一次搜索方向 p k p_{k} pk总是相互垂直的,称它为锯齿现象。除极特殊的目标函数(如等值面为球面的函数)和极特殊的初始点外,这种现象一般都要发生。
由于锯齿现象,在接近极小点的地方,每次迭代进行的距离变得越来越小,因而收敛速度不快,这正是最速下降法的缺点所在。
Newton法
由于最速下降法速度慢,Newton引入二阶梯度,通过求其Hesse矩阵,一步到位直接求到极小点 x ∗ x^{*} x∗。
如果目标函数 f ( x ) f(x) f(x)在 R n R^{n} Rn上具有连续的二阶偏导数,其Hesse矩阵 G ( x ) = ∇ 2 f ( x ) G(x)=\nabla^{2}f(x) G(x)=∇2f(x)正定,那么就可以用Newton法对其进行求解了。原理如下:
考虑从 x k x_{k} xk到 x k + 1 x_{k+1} xk+1的迭代过程。在点 x k x_{k} xk处,对 f ( x ) f(x) f(x)按Taylor级数展开到第三项,即:
f ( x ) ≈ Q ( x ) = f ( x k ) + g ( x k ) T ( x − x k ) + 1 2 ( x − x k ) T G ( x k ) ( x − x k ) f(x) \approx Q(x)=f\left(x_{k}\right)+g\left(x_{k}\right)^{T}\left(x-x_{k}\right)+\frac{1}{2}\left(x-x_{k}\right)^{T} G\left(x_{k}\right)\left(x-x_{k}\right) f(x)≈Q(x)=f(xk)+g(xk)T(x−xk)+21(x−xk)TG(xk)(x−xk)
又因为Hesse矩阵 G ( x ) G(x) G(x)正定,所以 Q ( x ) Q(x) Q(x)是 x x x的正定二次函数。令 Q ( x ) Q(x) Q(x)其一阶导数等于0,求出来的点就是极小点。
∇ Q ( x ) = G ( x k ) ( x − x k ) + g ( x k ) = 0 \nabla Q(x)=G\left(x_{k}\right)\left(x-x_{k}\right)+g\left(x_{k}\right)=0 ∇Q(x)=G(xk)(x−xk)+g(xk)=0
解出:
x k + 1 = x k − G ( x k ) − 1 g ( x k ) x_{k+1}=x_{k}-G\left(x_{k}\right)^{-1} g\left(x_{k}\right) xk+1=xk−G(xk)−1g(xk)
x k + 1 x_{k+1} xk+1是 f ( x ) f(x) f(x)极小点 x x x的新的近似点。上式称为Newton迭代公式,由该公式产生的算法称为Newton法。当目标函数 f ( x ) f(x) f(x)是正定二次函数时,有 f ( x ) f(x) f(x)恒等于 Q ( x ) Q(x) Q(x)。这说明:对于正定二次函数,Newton法一次迭代就会得到最优解。
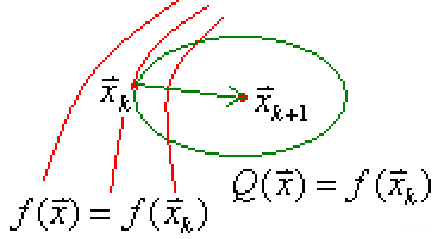
现在从几何上我们来直观理解一下,我们要求目标函数 f ( x ) f(x) f(x)的极小值,函数 f ( x ) f(x) f(x)过点 x k x_{k} xk的等值面方程 f ( x ) = f ( x k ) f(x)=f(x_{k}) f(x)=f(xk),在点 x k x_{k} xk处,用一个与该曲面最密切的二次曲面来代替它(Taylor展开),这个二次曲面的方程即是 Q ( x ) = f ( x ) Q(x)=f(x) Q(x)=f(x)。当 G ( x ) G(x) G(x)正定时,它是一个超椭球面, Q ( x ) Q(x) Q(x)的极小点 x k + 1 x_{k+1} xk+1正是这个超椭球面的中心。我们就用 x k + 1 x_{k+1} xk+1作为 f ( x ) f(x) f(x)极小点 x ∗ x^{*} x∗的近似点。如下图所示:
对于具有正定Hesse矩阵的一般目标函数,由于在极小点附近,它近似地呈现为正定二次函数,所以可以想见,Newton法在最优点附近应该具有较高的收敛速度。
修正Newton法
Newton法的优点是收敛速度快、程序简单。但是对于表达式很复杂的目标函数,由于其Hesse矩阵很难或不可能求出,这时显然不宜使用Newton法。下面介绍修正Newton法:
以下讨论仅假定Hesse矩阵可以求到。
-
在迭代点 x k x_{k} xk处Hesse矩阵 G k G_{k} Gk变为不可逆,由线性方程组 G k p k = − g k G_{k}p_{k}=-g_{k} Gkpk=−gk无法解出搜索方向 p k p_{k} pk。遇有此种情况,改取 p k = − g k p_{k}=-g_{k} pk=−gk,然后作直线搜索:
x k + 1 = l s ( x k , p k ) x_{k+1}=ls(x_{k},p_{k}) xk+1=ls(xk,pk)
即用最速下降法的迭代公式代替Newton法的迭代公式,从而完成这一次迭代。 -
在迭代点 x k x_{k} xk处Hesse矩阵 G k G_{k} Gk非奇异,即 G k − 1 G_{k}^{-1} Gk−1存在这时可解出 p k = − G k − 1 g k p_{k}=-G_{k}^{-1}g_{k} pk=−Gk−1gk(称为Newton方向)。按Newton迭代公式,有:
x k + 1 = x k + p k x_{k+1}=x_{k}+p_{k} xk+1=xk+pk
上式可以理解为从点 x k x_{k} xk出发沿 p k p_{k} pk方向进行直线搜索,步长因子取为1。上面这个公式是Newton法中假设目标函数为二次正定而推到出来的,但是现在这个目标函数并没有这一项约束,所以目标函数可能很复杂,因而不能总保证 p k p_{k} pk的方向是下降方向,有时即使是下降方向,也会由于步长因子不加选择地取为1,而不能保证 f ( x k + 1 ) < f ( x k ) f(x_{k+1})< f(x_{k}) f(xk+1)<f(xk)。对此又分情况进行处理:a.若 f ( x k + 1 ) < f ( x ) f(x_{k+1})< f(x_{}) f(xk+1)<f(x),那函数是朝着下降方向去的,则该迭代有效。
b.若 f ( x k + 1 ) ≤ f ( x ) f(x_{k+1}) \leq f(x_{}) f(xk+1)≤f(x),则表明函数不是朝着下降方向去的,这里又分了两种情况进行了讨论
第一:当 ∣ g k T p k ∣ ≤ ε ∥ g k ∥ ∥ p k ∥ \left |g_{k}^{T}p_{k}\right | \leq \varepsilon \left \| g_{k} \right \| \left \|p_{k} \right \| ∣∣gkTpk∣∣≤ε∥gk∥∥pk∥,( ε \varepsilon ε是某一很小的正数)时(说明 p k p_{k} pk与 − g k -g_{k} −gk几乎垂直,也就是说一阶梯度和假设目标函数为二次正定而求出的梯度方向完全不一致,也就是说明目标函数假设为二次正定函数错误,应该取一阶梯度方向),故Newton方向 p k p_{k} pk是不利方向。这时,改取 p k = − g k p_{k}=-g_{k} pk=−gk,然后新进行直线搜索。
第二: g k T p k < ε ∥ g k ∥ ∥ p k ∥ g_{k}^{T}p_{k} < \varepsilon \left \| g_{k} \right \| \left \|p_{k} \right \| gkTpk<ε∥gk∥∥pk∥时说明Newton方向 p k = − G k − 1 g k p_{k}=-G_{k}^{-1}g_{k} pk=−Gk−1gk是下降方向(一阶梯度和假设目标函数为二次正定而求出的梯度方向之间的夹角是小于90度的,大体方向一致),这时重新进行直线搜索。否则,有 g k T p k > ε ∥ g k ∥ ∥ p k ∥ g_{k}^{T}p_{k} > \varepsilon \left \| g_{k} \right \| \left \|p_{k} \right \| gkTpk>ε∥gk∥∥pk∥时说明Newton方向 p k = − G k − 1 g k p_{k}=-G_{k}^{-1}g_{k} pk=−Gk−1gk是上升方向(一阶梯度和假设目标函数为二次正定而求出的梯度方向之间的夹角是大于90度的,大体方向相反)改取Newton方向的反方向 p k = G k − 1 g k p_{k}=G_{k}^{-1}g_{k} pk=Gk−1gk为搜索方向,然后重新进行直线搜索。
拟Newton法
拟Newton法是效果很好的一大类方法。它当中的DFP算法和BFGS算法是直到目前为止在不用Hesse矩阵的方法中的最好方法。
基本思想
考虑Newton迭代公式
x k + 1 = x k − G k − 1 g k , k = 0 , 1 , ⋅ ⋅ ⋅ x_{k+1}=x_{k}-G_{k}^{-1} g_{k} , \ \ k=0,1, ··· xk+1=xk−Gk−1gk, k=0,1,⋅⋅⋅
这里搜索方向为 p k = − G k − 1 g k p_{k}=-G_{k}^{-1}g_{k} pk=−Gk−1gk,步长因子为1。
我们从以下两点考虑对Newton迭代公式的改进:
(1) 为避免求逆矩阵,设想用某种近似矩阵 H k = H ( x k ) H_{k}=H(x_{k}) Hk=H(xk)替换 − G k − 1 -G_{k}^{-1} −Gk−1,上式则变为
x k + 1 = x k − H k g k , k = 0 , 1 , ⋅ ⋅ ⋅ x_{k+1}=x_{k}-H_{k} g_{k} , \ \ k=0,1, ··· xk+1=xk−Hkgk, k=0,1,⋅⋅⋅
这时搜索方向为 p k = − H k g k p_{k}=-H_{k}g_{k} pk=−Hkgk,步长因子仍为1。
(2) 为了取得更大的灵活性,考虑更一般的公式
x k + 1 = x k − t k H k g k , k = 0 , 1 , ⋅ ⋅ ⋅ x_{k+1}=x_{k}-t_{k}H_{k} g_{k} , \ \ k=0,1, ··· xk+1=xk−tkHkgk, k=0,1,⋅⋅⋅
这时搜索方向仍为 p k = − H k g k p_{k}=-H_{k}g_{k} pk=−Hkgk,但步长因子取为最优步长因子。上式是代表面很广的一类迭代公式。例如,当 H k = E H_{k}=E Hk=E时,它是最速下降法公式。当 H k = G k − 1 H_{k}=G_{k}^{-1} Hk=Gk−1时,它是阻尼Newton法公式。
这样的 H k H_{k} Hk存在吗?又如何来求呢?假如存在,那么为使 H k H_{k} Hk确实近似 G k − 1 G_{k}^{-1} Gk−1并易于计算,我们要对 H k H_{k} Hk人为地附加某些条件。主要是三点:
第一,为保证搜索方向 p k = − H k g k p_{k}=-H_{k}g_{k} pk=−Hkgk是下降方向,如果 ∇ f ( x 0 ) T p < 0 \nabla f(x_{0})^{T}p < 0 ∇f(x0)Tp<0,则 p p p方向是函数 f ( x ) f(x) f(x)在点 x 0 x_{0} x0处的下降方向得到:
p k T g k < 0 ⇒ − g k T H k g k < 0 ⇒ g k T H k g k > 0 p_{k}^{T} g_{k}<0 \Rightarrow-g_{k}^{T} H_{k} g_{k}<0 \Rightarrow g_{k}^{T} H_{k} g_{k}>0 pkTgk<0⇒−gkTHkgk<0⇒gkTHkgk>0
要求每一个 H k H_{k} Hk都是对称正定矩阵,可以保证该式成立。
第二,为易于计算,要求 H k H_{k} Hk到 H k + 1 H_{k+1} Hk+1之间具有简单的迭代形式。最简单的迭代关系为
H k + 1 = H k + E k H_{k+1}=H_{k}+E_{k} Hk+1=Hk+Ek
E k E_{k} Ek称为校正矩阵,上式称为校正公式。
第三,为使 H k H_{k} Hk确实近似 G k − 1 G_{k}^{-1} Gk−1要求每一个 H k H_{k} Hk必须满足拟Newton条件。那所谓的拟Newton条件是啥呢?
我们假设目标函数 f ( x ) f(x) f(x)具有连续的二阶偏导数,将 f ( x ) f(x) f(x)在点 x k + 1 x_{k+1} xk+1处作Taylor级数展开:
f ( x ) ≈ f ( x k + 1 ) + ∇ f ( x k + 1 ) T ( x − x k + 1 ) + 1 2 ( x − x k + 1 ) T G k + 1 ( x − x k + 1 ) f(x) \approx f\left(x_{k+1}\right)+\nabla f\left(x_{k+1}\right)^{T}\left(x-x_{k+1}\right)+\frac{1}{2}\left(x-x_{k+1}\right)^{T} G_{k+1}\left(x-x_{k+1}\right) f(x)≈f(xk+1)+∇f(xk+1)T(x−xk+1)+21(x−xk+1)TGk+1(x−xk+1)
对上式两端求梯度有:
∇ f ( x ) ≈ g k + 1 + G k + 1 ( x − x k + 1 ) \nabla f(x) \approx g_{k+1}+G_{k+1}\left(x-x_{k+1}\right) ∇f(x)≈gk+1+Gk+1(x−xk+1)
令 x = x k x=x_{k} x=xk,则有:
g k ≈ g k + 1 + G k + 1 ( x k − x k + 1 ) g_{k} \approx g_{k+1}+G_{k+1}\left(x_{k}-x_{k+1}\right) gk≈gk+1+Gk+1(xk−xk+1)
所以,当 G k + 1 G_{k+1} Gk+1正定时,有
x k + 1 − x k ≈ G k + 1 − 1 ( g k + 1 − g k ) x_{k+1}-x_{k} \approx G_{k+1}^{-1}\left(g_{k+1}-g_{k}\right) xk+1−xk≈Gk+1−1(gk+1−gk)
对于正定二次函数,上式近似将变为等式。
因此,如果迫使 H k + 1 H_{k+1} Hk+1满足类似于上式的等式
x k + 1 − x k = H k + 1 ( g k + 1 − g k ) x_{k+1}-x_{k} = H_{k+1} \left(g_{k+1}-g_{k}\right) xk+1−xk=Hk+1(gk+1−gk)
那么 H k + 1 H_{k+1} Hk+1就有可能很好地近似于 G k + 1 − 1 G_{k+1}^{-1} Gk+1−1上式称为拟Newton条件或拟Newton方程。
记:
s k = x k + 1 − x k y k = g k + 1 − g k s_{k}=x_{k+1}-x_{k} \\ y_{k} = g_{k+1}-g_{k} sk=xk+1−xkyk=gk+1−gk
那么拟Newton条件可简记为:
H k + 1 y k = S k H_{k+1}y_{k}=S_{k} Hk+1yk=Sk
带入迭代关系式 H k + 1 = H k + E k H_{k+1}=H_{k}+E_{k} Hk+1=Hk+Ek有:
E k y k = S k − H k y k E_{k}y_{k} = S_{k} - H_{k}y_{k} Ekyk=Sk−Hkyk
算法中的校正矩阵 E k E_{k} Ek可由确定的公式来计算,不同的公式对应不同的拟Newton算法。满足条件的 E k E_{k} Ek有无穷多个,因此上述的拟Newton算法是一簇算法。
DFP算法
DFP法是首先由Davidon(1959年)提出,后由Fletcher和Powell(1963年)改进的算法。它是无约束优化方法中最有效的方法之一。DFP法虽说比共轭梯度法有效,但它对直线搜索有很高的精度要求。
考虑如下校正公式
H k + 1 = H k + α k u k u k T + β k v k v k T H_{k+1}=H_{k}+\alpha_{k}u_{k}u_{k}^{T}+\beta_{k}v_{k}v_{k}^{T} Hk+1=Hk+αkukukT+βkvkvkT
其中 u k u_{k} uk, v k v_{k} vk是待定列向量, α k \alpha_{k} αk, β k \beta_{k} βk是待定常数。校正矩阵
E k = α k u k u k T + β k v k v k T E_{k}=\alpha_{k}u_{k}u_{k}^{T}+\beta_{k}v_{k}v_{k}^{T} Ek=αkukukT+βkvkvkT
根据拟Newton条件,有
α k u k u k T y k + β k v k v k T y k = s k − H k y k \alpha_{k}u_{k}u_{k}^{T}y_{k}+\beta_{k}v_{k}v_{k}^{T}y_{k} = s_{k}-H_{k}y_{k} αkukukTyk+βkvkvkTyk=sk−Hkyk
上式 u k u_{k} uk和 v k v_{k} vk有很多种取法
α k u k u k T y k = s k β k v k v k T y k = − H k y k \alpha_{k}u_{k}u_{k}^{T}y_{k} = s_{k} \\ \beta_{k}v_{k}v_{k}^{T}y_{k} = -H_{k}y_{k} αkukukTyk=skβkvkvkTyk=−Hkyk
如果取 u k = s k u_{k}=s_{k} uk=sk, v k = H k y k v_{k}=H_{k}y_{k} vk=Hkyk那么有
α k = 1 s k T y k , β k = − 1 y k T H k y k \alpha_{k}=\frac{1}{s_{k}^{T}y_{k}}, \ \beta_{k}=-\frac{1}{y_{k}^{T}H_{k}y_{k}} αk=skTyk1, βk=−ykTHkyk1
H k + 1 = H k + s k s k T s k T y k − H k y k y k T H k y k T H k y k H_{k+1}=H_{k}+\frac{s_{k}s_{k}^{T}}{s_{k}^{T}y_{k}}-\frac{H_{k}y_{k}y_{k}^{T}H_{k}}{y_{k}^{T}H_{k}y_{k}} Hk+1=Hk+skTykskskT−ykTHkykHkykykTHk
DFP算法的性质
定理1:在DFP算法中,若初始矩阵 H 0 H_{0} H0对称正定,则 H k H_{k} Hk中每一个都对称正定。
定理2:设将DFP算法施用于具有对称正定矩阵 Q Q Q的二次函数 f ( x ) = 1 2 x T Q x + b T x + c f(x)=\frac{1}{2} x^{T} Q x+b^{T} x+c f(x)=21xTQx+bTx+c,如果:
(i) 初始矩阵 H 0 H_{0} H0对称正定;
(ii) 迭代点互异,产生的搜索方向向量依次为 p 0 , p 1 , ⋅ ⋅ ⋅ , P k ( k ≤ n − 1 ) p_{0},p_{1},···,P_{k} \ (k \leq n-1) p0,p1,⋅⋅⋅,Pk (k≤n−1),则有
p i T Q p j = 0 , i , j = 0 , 1 , ⋅ ⋅ ⋅ , k ( i ≠ j ) H k + 1 Q p j = p j , j = 0 , 1 , ⋅ ⋅ ⋅ , k . p_{i}^{T}Q p_{j} = 0, \ i,j = 0,1,···,k(i \neq j) \\ H_{k+1}Qp_{j} = p_{j}, \ j=0,1,···,k. piTQpj=0, i,j=0,1,⋅⋅⋅,k(i=j)Hk+1Qpj=pj, j=0,1,⋅⋅⋅,k.
定理3:若定理2的条件都满足,并且经过 n n n次迭代才求到极小点,则 H n = Q − 1 H_{n}=Q^{-1} Hn=Q−1。
共轭方向法与共轭梯度法
基本思想
最速下降法存在锯齿现象,Newton法需要计算目标函数的二阶导数。接下来介绍的共轭方向法是介于最速下降法和Newton法之间的一种方法,它克服了最速下降法的锯齿现象,从而提高了收敛速度;它的迭代公式也比较简单,不必计算目标函数的二阶导数,与Newton法相比,减少了计算量和存储量。它是比较实用而有效的最优化方法。
我们先将其在正定二次函数 f ( x ) = 1 2 x T Q x + b T x + c f(x)=\frac{1}{2} x^{T} Q x+b^{T} x+c f(x)=21xTQx+bTx+c上研究,然后再把算法用到更一般的目标函数上。首先考虑二维的情形。
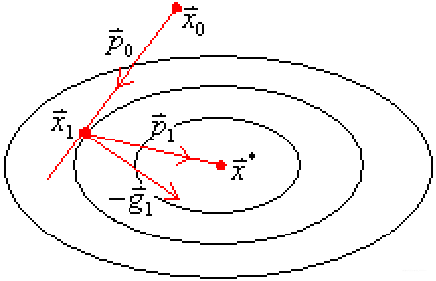
任选初始点 x 0 x_{0} x0,沿它的某个下降方向,例如向量 p 0 p_{0} p0的方向,作直线搜索,如上图所示。由下面这个定理:
定理:设目标函数 f ( x ) f(x) f(x)具有一阶连续偏导数,若 z = l s ( x , p ) z=ls(x,p) z=ls(x,p),则 ∇ f ( z ) T p = 0 \nabla f(z)^{T}p=0 ∇f(z)Tp=0。
知 ∇ f ( x 1 ) T p 0 = 0 \nabla f(x_{1})^{T}p_{0}=0 ∇f(x1)Tp0=0。如果按照最速下降法选择的就是负梯度方向为搜索方向(也就是 − g 1 -g_{1} −g1方向),那么将要发生锯齿现象。于是一个设想是,干脆选择下一个迭代的搜索方向 p 1 p_{1} p1就从 x 1 x_{1} x1直指极小点 x ∗ x^{*} x∗,也就是找到上图所示的 p 1 p_{1} p1方向。
因为 p 1 p_{1} p1从 x 1 x_{1} x1直指极小点 x ∗ x^{*} x∗,所以 x ∗ x^{*} x∗可以表示为:
x ∗ = x 1 + t 1 p 1 x^{*}=x_{1}+t_{1}p_{1} x∗=x1+t1p1
其中 t 1 t_{1} t1是最优步长因子。显然,当 x ∗ ≠ x 1 x^{*} \neq x_{1} x∗=x1时, t 1 ≠ 0 t_{1} \neq 0 t1=0。到这里,我们还有一个已知条件没用,就是目标函数为二次正定,所以我们对目标函数求导,得到:
∇ f ( x ) = Q x + b \nabla f(x)=Qx+b ∇f(x)=Qx+b
因为 x ∗ x^{*} x∗是极小点,所以有:
∇ f ( x ∗ ) = Q x ∗ + b = 0 \nabla f(x^{*})=Qx^{*}+b=0 ∇f(x∗)=Qx∗+b=0
将 x ∗ = x 1 + t 1 p 1 x^{*}=x_{1}+t_{1}p_{1} x∗=x1+t1p1带入上述方程式,有:
∇ f ( x 1 ) + t 1 Q p 1 = 0 \nabla f(x_{1}) + t_{1}Qp_{1}=0 ∇f(x1)+t1Qp1=0
上式两边同时左乘 p 0 T p_{0}^{T} p0T,并注意到 p 0 T ∇ f ( x 1 ) = 0 p_{0}^{T} \nabla f(x_{1})=0 p0T∇f(x1)=0和 t ≠ 0 t \neq 0 t=0,得到 p 0 T Q p 1 = 0 p_{0}^{T}Qp_{1}=0 p0TQp1=0。这就是为使 p 1 p_{1} p1直指极小点 x ∗ x^{*} x∗, p 1 p_{1} p1所必须满足的条件。并且我们将两个向量 p 0 p_{0} p0和 p 1 p_{1} p1称为 Q Q Q共轭向量或称 p 0 p_{0} p0和 p 1 p_{1} p1是 Q Q Q共轭方向。
由上面共轭梯度法那张图可以设:
p 1 = − ∇ f ( x 1 ) + α 0 p 0 p_{1}=-\nabla f(x_{1})+\alpha_{0}p_{0} p1=−∇f(x1)+α0p0
上式两边同时左乘 p 0 T Q p_{0}^{T}Q p0TQ,得:
− p 0 T Q ∇ f ( x 1 ) + α 0 p 0 T Q p 0 = 0 -p_{0}^{T} Q \nabla f\left(x_{1}\right)+\alpha_{0} p_{0}^{T} Q p_{0}=0 −p0TQ∇f(x1)+α0p0TQp0=0
由此解出:
α 0 = p 0 T Q ∇ f ( x 1 ) p 0 T Q p 0 \alpha_{0} = \frac{p_{0}^{T} Q \nabla f\left(x_{1}\right)}{p_{0}^{T} Q p_{0}} α0=p0TQp0p0TQ∇f(x1)
代回 p 1 = − ∇ f ( x 1 ) + α 0 p 0 p_{1}=-\nabla f(x_{1})+\alpha_{0}p_{0} p1=−∇f(x1)+α0p0得:
p 1 = − ∇ f ( x 1 ) + p 0 T Q ∇ f ( x 1 ) p 0 T Q p 0 p 0 p_{1}=-\nabla f(x_{1})+\frac{p_{0}^{T} Q \nabla f\left(x_{1}\right)}{p_{0}^{T} Q p_{0}}p_{0} p1=−∇f(x1)+p0TQp0p0TQ∇f(x1)p0
从而求到了 p 1 p_{1} p1的方向。
归纳一下,对于正定二元二次函数,从任意初始点 x 0 x_{0} x0出发,沿任意下降方向 p 0 p_{0} p0做直线搜索得到 x 1 x_{1} x1再从 x 1 x_{1} x1出发,沿 p 0 p_{0} p0的共轭方向 p 1 p_{1} p1作直线搜索,所得到的 x 2 x_{2} x2必是极小点 x ∗ x^{*} x∗。到目前为止的共轭梯度法依旧是假设了目标函数是二次正定矩阵。
上面的结果可以推广到 n n n维空间中,即在 n n n维空间中,可以找出 n n n个互相共轭的方向,对于 n n n元正定二次函数从任意初始点出发,顺次沿着这 n n n个共轭方向最多作 n n n次直线搜索,就可以求到目标函数的极小点。
对于 n n n元正定二次目标函数,如果从任意初始点出发经过有限次迭代就能够求到极小点,那么称这种算法具有二次终止性。例如,Newton法对于二次函数只须经过一次迭代就可以求到极小点,因此是二次终止的;而最速下降法就不具有二次终止性。共轭方向法(如共轭梯度法、拟Newton法等)也是二次终止的。
一般说来,具有二次终止性的算法,在用于一般函数时,收敛速度是较快的。
共轭向量及其性质
定义:设 Q Q Q是 n × n n \times n n×n对称正定矩阵。若 n n n维向量空间中的非零向量 p 0 , p 1 , ⋅ ⋅ ⋅ , p m − 1 p_{0},p_{1},···,p_{m-1} p0,p1,⋅⋅⋅,pm−1满足 p i T Q p j = 0 p_{i}^{T}Qp_{j}=0 piTQpj=0, i , j = 0 , 1 , ⋅ ⋅ ⋅ , m − 1 ( i ≠ j ) i,j=0,1,···,m-1(i \neq j) i,j=0,1,⋅⋅⋅,m−1(i=j)则称 p 0 , p 1 , ⋅ ⋅ ⋅ , p m − 1 p_{0},p_{1},···,p_{m-1} p0,p1,⋅⋅⋅,pm−1是 Q Q Q共轭向量或称向量 p 0 , p 1 , ⋅ ⋅ ⋅ , p m − 1 p_{0},p_{1},···,p_{m-1} p0,p1,⋅⋅⋅,pm−1是 Q Q Q共轭的(简称共轭)。
当 Q = E Q=E Q=E(单位矩阵)时 p i T Q p j = 0 p_{i}^{T}Qp_{j}=0 piTQpj=0变为 p i T p j = 0 p_{i}^{T}p_{j}=0 piTpj=0, i , j = 0 , 1 , ⋅ ⋅ ⋅ , m − 1 ( i ≠ j ) i,j=0,1,···,m-1(i \neq j) i,j=0,1,⋅⋅⋅,m−1(i=j)。即向量 i , j = 0 , 1 , ⋅ ⋅ ⋅ , m − 1 ( i ≠ j ) i,j=0,1,···,m-1(i \neq j) i,j=0,1,⋅⋅⋅,m−1(i=j)互相正交。由此看到,“正交”是“共轭”的一种特殊情形,或说,“共轭”是“正交”的推广。
下面介绍几个定理:
定理:若非零向量 p 0 , p 1 , ⋅ ⋅ ⋅ , p m − 1 p_{0},p_{1},···,p_{m-1} p0,p1,⋅⋅⋅,pm−1是 Q Q Q共轭的,则线性无关。
推论:在 n n n维向量空间中, R n R^{n} Rn非零的共轭向量的个数不超过 n n n。
定义 设 p 0 , p 1 , ⋅ ⋅ ⋅ , p m − 1 p_{0},p_{1},···,p_{m-1} p0,p1,⋅⋅⋅,pm−1是 R R R中的线性无关向量, x 0 ∈ R x_{0} \in R x0∈R。那么形式为:
z = x 0 + ∑ i = 0 m − 1 α i p i , ∀ α 1 , α 2 , ⋯ , α m − 1 ∈ R z=x_{0}+\sum_{i=0}^{m-1} \alpha_{i} p_{i}, \forall \alpha_{1}, \alpha_{2}, \cdots, \alpha_{m-1} \in R z=x0+i=0∑m−1αipi,∀α1,α2,⋯,αm−1∈R
的向量构成的集合,记为 L [ x 0 ; p 0 , p 1 , ⋅ ⋅ ⋅ , p m − 1 ] L \left [ x_{0};p_{0},p_{1},···,p_{m-1} \right ] L[x0;p0,p1,⋅⋅⋅,pm−1]。称为由点 x 0 x_{0} x0和向量 p 0 , p 1 , ⋅ ⋅ ⋅ , p m − 1 p_{0},p_{1},···,p_{m-1} p0,p1,⋅⋅⋅,pm−1所生成的线性流形。
共轭方向法
共轭方向法的理论基础是下面的定理。
定理 假设
(1) Q为 n × n n \times n n×n对称正定矩阵;
(2) 非零向量 p 0 , p 1 , ⋅ ⋅ ⋅ , p m − 1 p_{0},p_{1},···,p_{m-1} p0,p1,⋅⋅⋅,pm−1是 Q Q Q共轭向量;
(3) 对二次目标函数 f ( x ) = 1 2 x T Q x + b T x + c f(x)=\frac{1}{2} x^{T} Q x+b^{T} x+c f(x)=21xTQx+bTx+c顺次进行 m m m次直线搜索:
x i 1 = l s ( x i , p i ) , i = 0 , 1 , ⋅ ⋅ ⋅ , m − 1 x_{i_1} = ls(x_{i},p_{i}) , i=0,1,···,m-1 xi1=ls(xi,pi),i=0,1,⋅⋅⋅,m−1
其中 x 0 ∈ R x_{0} \in R x0∈R是任意选定的初始点,则有:
i) p j T ∇ f ( x m ) = 0 p_{j}^{T} \nabla f(x_{m})=0 pjT∇f(xm)=0, 0 ⩽ j ⩽ m 0 \leqslant j \leqslant m 0⩽j⩽m;
ii) x m x_{m} xm是二次函数 f ( x ) = 1 2 x T Q x + b T x + c f(x)=\frac{1}{2} x^{T} Q x+b^{T} x+c f(x)=21xTQx+bTx+c在线性流形 L [ x 0 ; p 0 , p 1 , ⋅ ⋅ ⋅ , p m − 1 ] L \left [ x_{0};p_{0},p_{1},···,p_{m-1} \right ] L[x0;p0,p1,⋅⋅⋅,pm−1]上的极小点。
这个定理看来较繁,但可借用直观的几何图形来帮助理解。 n = 3 n=3 n=3, m = 2 m=2 m=2的情形为例,如图示。

p 0 p_{0} p0和 p 1 p_{1} p1是Q共轭向量,张成了二维空间 R 2 R^{2} R2,这是过坐标原点的一个平面。 现在,过点 x 0 x_{0} x0沿 p 0 p_{0} p0方向作直线搜索得到 x 1 x_{1} x1,再过点 x 1 x_{1} x1沿 p 1 p_{1} p1方向作直线搜索得到 x 2 x_{2} x2过点 x 0 x_{0} x0由向量 p 0 p_{0} p0和 p 1 p_{1} p1张成的平面就是线性流形 L [ x 0 ; p 0 , p 1 ] L \left [ x_{0};p_{0},p_{1} \right ] L[x0;p0,p1]。它是 R 2 R^{2} R2的平行平面。
定理的论断是,最后一个迭代点 x 2 x_{2} x2处的梯度 ∇ f ( x 2 ) \nabla f(x_{2}) ∇f(x2)必与 p 0 p_{0} p0和 p 1 p_{1} p1垂直。并且 x 2 x_{2} x2是三元二次目标函数 f ( x ) f(x) f(x)在线性流形 L [ x 0 ; p 0 , p 1 ] L \left [ x_{0};p_{0},p_{1} \right ] L[x0;p0,p1](即过 x 0 x_{0} x0由 p 0 p_{0} p0和 p 1 p_{1} p1张成的平面)上的极小点。
共轭方向法算法的大体流程就是:选定初始点 x 0 x_{0} x0和下降方向向量 p 0 p_{0} p0,做直线搜索 x k + 1 = l s ( x k , p k ) x_{k+1}=ls(x_{k},p_{k}) xk+1=ls(xk,pk)。提供的梯度方向 p k + 1 p_{k+1} pk+1使得 p j T Q p k + 1 = 0 p_{j}^{T}Qp_{k+1}=0 pjTQpk+1=0, j = 0 , 1 , ⋅ ⋅ ⋅ , k j=0,1,···,k j=0,1,⋅⋅⋅,k。提供共轭方向的方法有多种。不同的提供方法将对应不同的共轭方法。每种方法也因产生共轭方向的特点而得名。
那么这里做直线搜索 x k + 1 = x k + t p k x_{k+1}=x_{k}+tp_{k} xk+1=xk+tpk中的 t t t是如何确定的呢?这里我们先回顾一下在最速下降法中是如何计算这个 t t t的。最速下降法:
依据定理 设目标函数 f ( x ) f(x) f(x)具有一阶连续偏导数,若 z = l s ( x , p ) z=ls(x,p) z=ls(x,p),则 ∇ f ( z ) T p = 0 \nabla f(z)^{T}p=0 ∇f(z)Tp=0。,我们可以得到 g k + 1 ⋅ g k = 0 g_{k+1}·g_{k}=0 gk+1⋅gk=0。由此有:
g k + 1 ⋅ g k = [ Q ( x k − t k g k ) + b ] T g ( k ) = 0 = [ Q x k + b − t k Q g k ] T g ( k ) = 0 = [ g k − t k Q g k ] T g ( k ) = 0 \begin{aligned} g_{k+1}·g_{k} & = [Q(x_{k}-t_{k}g_{k})+b]^{T}g(k)=0 \\ & = [Qx_{k}+b - t_{k}Qg_{k}]^{T}g(k)=0 \\ & = [g_{k}-t_{k}Qg_{k}]^{T}g(k)=0 \end{aligned} gk+1⋅gk=[Q(xk−tkgk)+b]Tg(k)=0=[Qxk+b−tkQgk]Tg(k)=0=[gk−tkQgk]Tg(k)=0
由此,可求解出 t k t_{k} tk:
t k = g k T g k g k T Q g k t_{k}=\frac{g_{k}^{T}g_{k}}{g_{k}^{T}Qg_{k}} tk=gkTQgkgkTgk
这里还可以采用另外一种种方式计算 t k t_{k} tk,下面对另外一种方式进行公式推导:
由 x k + 1 = x k + t p k x_{k+1}=x_{k}+tp_{k} xk+1=xk+tpk,用 Q Q Q左乘上式两边,然后再同时加上 b b b,利用 ∇ f ( x ) = Q x + b \nabla f(x)=Qx+b ∇f(x)=Qx+b能够得到:
∇ f ( x k + 1 ) = ∇ f ( x k ) + t Q p k \nabla f(x_{k+1})=\nabla f(x_{k}) + t Q p_{k} ∇f(xk+1)=∇f(xk)+tQpk
左乘 p k p_{k} pk有
p k T ∇ f ( x k + t p k ) = p k T ∇ f ( x k ) + t p k T Q p k = 0 p_{k}^{T} \nabla f(x_{k}+tp_{k})=p_{k}^{T} \nabla f(x_{k}) + t p_{k}^{T} Q p_{k} = 0 pkT∇f(xk+tpk)=pkT∇f(xk)+tpkTQpk=0
由此解出:
t = − p k T ∇ f ( x k ) p k T Q p k t=- \frac{p_{k}^{T} \nabla f(x_{k})}{p_{k}^{T} Q p_{k}} t=−pkTQpkpkT∇f(xk)
在最速下降法中 x k + 1 = x k − t k g k x_{k+1}=x_{k} - t_{k}g_{k} xk+1=xk−tkgk,在共轭方向法中 x k + 1 = x k + t k g k x_{k+1}=x_{k} + t_{k}g_{k} xk+1=xk+tkgk。
共轭梯度法
在共轭方向法中,如果初始共轭向量 p 0 p_{0} p0恰好取为初始点 x 0 x_{0} x0处的负梯度 − g 0 - g_{0} −g0,而其余共轭向量 p k p_{k} pk ( k = 1 , 2 , ⋅ ⋅ ⋅ , n − 1 ) (k=1,2,···,n-1) (k=1,2,⋅⋅⋅,n−1)由第 k k k个迭代点 x k x_{k} xk处的负梯度 − g k - g_{k} −gk与已经得到的共轭向量 p k − 1 p_{k-1} pk−1的线性组合来确定,那么这个共轭方向法就称为共轭梯度法。
针对目标函数是正定二次函数来讨论:
(1) 第一个迭代点的获得:
选定初始点 x 0 x_{0} x0,设 x 0 ≠ x ∗ x_{0} \neq x^{*} x0=x∗(否则迭代终止),因此 ∇ f ( x 0 ) ≠ 0 \nabla f(x_{0}) \neq 0 ∇f(x0)=0。(以下用 g k g_{k} gk表示 ∇ f ( x k ) \nabla f(x_{k}) ∇f(xk))从 x 0 x_{0} x0出发沿 p 0 p_{0} p0方向做直线搜索,得到第1个迭代点 x 1 = x 0 + t 0 p 0 x_{1}=x_{0}+t_{0}p_{0} x1=x0+t0p0,其中 t 0 t_{0} t0可由下式确定:
t 0 = − p 0 T g 0 p 0 T Q p 0 = g 0 T g 0 p 0 T Q p 0 t_{0}=- \frac{p_{0}^{T} g_{0}}{p_{0}^{T} Q p_{0}} = \frac{g_{0}^{T}g_{0}}{p_{0}^{T}Qp_{0}} t0=−p0TQp0p0Tg0=p0TQp0g0Tg0
显然 t 0 ≠ 0 t_{0} \neq 0 t0=0
(2) 第二个迭代点的获得:
设 x 1 ≠ x ∗ x_{1} \neq x^{*} x1=x∗,因此 g 1 ≠ 0 g_{1} \neq 0 g1=0。由 p 0 T g 1 = 0 p_{0}^{T}g_{1}=0 p0Tg1=0知 p 0 p_{0} p0与 g 1 g_{1} g1线性无关。取 p 1 = − g 1 + α 0 p 0 p_{1}=-g_{1} + \alpha _{0} p_{0} p1=−g1+α0p0其中 α 0 \alpha_{0} α0是使 p 1 p_{1} p1与 p 0 p_{0} p0共轭的待定系数,令:
p 1 T Q p 0 = − g 1 T Q p 0 + α 0 p 0 T Q p 0 = 0 p_{1}^{T}Qp_{0}=-g_{1}^{T}Qp_{0} + \alpha_{0} p_{0}^{T}Qp_{0} = 0 p1TQp0=−g1TQp0+α0p0TQp0=0
由此解出
α 0 = g 1 T Q p 0 p 0 T Q p 0 \alpha _{0} = \frac{g_{1}^{T}Qp_{0}}{p_{0}^{T}Qp_{0}} α0=p0TQp0g1TQp0
并代回确定 p 1 p_{1} p1,并获得第2个迭代点。
x 2 = x 1 + t 1 p 1 x_{2}=x_{1}+t_{1}p_{1} x2=x1+t1p1
由公式 t = − p k T ∇ f ( x k ) p k T Q p k t=- \frac{p_{k}^{T} \nabla f(x_{k})}{p_{k}^{T} Q p_{k}} t=−pkTQpkpkT∇f(xk)可以求得 t 1 t_{1} t1,带入公式 p 1 = − g 1 + α 0 p 0 p_{1}=-g_{1} + \alpha _{0} p_{0} p1=−g1+α0p0可进一步优化得到:
t 1 = − p 1 T g 1 p 1 T Q p 1 = g 1 T g 1 p 1 T Q p 1 ≠ 0 t_{1} = - \frac{p_{1}^{T} g_{1}}{p_{1}^{T} Q p_{1}} = \frac{g_{1}^{T} g_{1}}{p_{1}^{T} Q p_{1}} \neq 0 t1=−p1TQp1p1Tg1=p1TQp1g1Tg1=0
(3) 第三个迭代点的获得:
设 x 2 ≠ x ∗ x_{2} \neq x^{*} x2=x∗,因此 g 2 ≠ 0 g_{2} \neq 0 g2=0。由 p 1 T g 2 = 0 p_{1}^{T}g_{2}=0 p1Tg2=0知 p 1 p_{1} p1与 g 2 g_{2} g2线性无关。取 p 2 = − g 2 + α 1 p 1 p_{2}=-g_{2} + \alpha _{1} p_{1} p2=−g2+α1p1其中 α 1 \alpha_{1} α1是使 p 2 p_{2} p2与 p 1 p_{1} p1共轭的待定系数,令:
p 2 T Q p 1 = − g 2 T Q p 1 + α 1 p 1 T Q p 1 = 0 p_{2}^{T}Qp_{1}=-g_{2}^{T}Qp_{1} + \alpha_{1} p_{1}^{T}Qp_{1} = 0 p2TQp1=−g2TQp1+α1p1TQp1=0
由此解出
α 1 = g 2 T Q p 1 p 1 T Q p 1 \alpha _{1} = \frac{g_{2}^{T}Qp_{1}}{p_{1}^{T}Qp_{1}} α1=p1TQp1g2TQp1
并代回确定 p 2 p_{2} p2 ,并获得第3个迭代点。
x 3 = x 2 + t 2 p 2 x_{3}=x_{2}+t_{2}p_{2} x3=x2+t2p2
其中
t 2 = − p 2 T g 2 p 2 T Q p 2 = g 2 T g 2 p 2 T Q p 2 ≠ 0 t_{2} = - \frac{p_{2}^{T} g_{2}}{p_{2}^{T} Q p_{2}} = \frac{g_{2}^{T} g_{2}}{p_{2}^{T} Q p_{2}} \neq 0 t2=−p2TQp2p2Tg2=p2TQp2g2Tg2=0
上述过程仅表明 p 0 p_{0} p0与 p 1 p_{1} p1, p 1 p_{1} p1与 p 2 p_{2} p2共轭,现在问, p 0 p_{0} p0与 p 2 p_{2} p2也共轭吗?
p 2 T Q p 0 = ( − g 2 + α 1 p 1 ) T Q p 0 = − g 2 T Q p 0 + α 1 p 1 T Q p 0 = − g 2 T Q p 0 [ L ∣ p 1 T Q p 0 = 0 ] = − g 2 T ( g 1 − g 0 ) / t 0 ( H g 1 + 1 = g i + t i Q p i , t i ≠ 0 ) = − ( g 2 T g 1 − g 2 T g 0 ) / t 0 \begin{aligned} p_{2}^{T} Q p_{0} &=\left(-g_{2}+\alpha_{1} p_{1}\right)^{T} Q p_{0} \\ &=-g_{2}^{T} Q p_{0}+\alpha_{1} p_{1}^{T} Q p_{0} \\ &=-g_{2}^{T} Q p_{0}\left[\mathbb{L} | p_{1}^{T} Q p_{0}=0\right] \\ &=-g_{2}^{T}\left(g_{1}-g_{0}\right) / t_{0}\left(\mathrm{Hg}_{1+1}=g_{i}+t_{i} Q p_{i}, t_{i} \neq 0\right) \\ &=-\left(g_{2}^{T} g_{1}-g_{2}^{T} g_{0}\right) / t_{0} \end{aligned} p2TQp0=(−g2+α1p1)TQp0=−g2TQp0+α1p1TQp0=−g2TQp0[L∣p1TQp0=0]=−g2T(g1−g0)/t0(Hg1+1=gi+tiQpi,ti=0)=−(g2Tg1−g2Tg0)/t0
(4) 第 k k k个迭代点的获得:
由 p k − 1 T g k = 0 p_{k-1}^{T}g_{k}=0 pk−1Tgk=0知 p k − 1 p_{k-1} pk−1与 g k g_{k} gk线性无关。取 p k = − g k + α k − 1 p k − 1 p_{k}=-g_{k} + \alpha _{k-1} p_{k-1} pk=−gk+αk−1pk−1其中 α k − 1 \alpha_{k-1} αk−1是使 p k p_{k} pk与 p k − 1 p_{k-1} pk−1共轭的待定系数,令:
p k T Q p k − 1 = − g k T Q p k − 1 + α k − 1 p k − 1 T Q p k − 1 = 0 p_{k}^{T}Qp_{k-1}=-g_{k}^{T}Qp_{k-1} + \alpha_{k-1} p_{k-1}^{T}Qp_{k-1} = 0 pkTQpk−1=−gkTQpk−1+αk−1pk−1TQpk−1=0
由此解出
α k − 1 = g k T Q p k − 1 p k − 1 T Q p k − 1 \alpha _{k-1} = \frac{g_{k}^{T}Qp_{k-1}}{p_{k-1}^{T}Qp_{k-1}} αk−1=pk−1TQpk−1gkTQpk−1
并代回确定 p k p_{k} pk ,并获得第k+1个迭代点。
x k + 1 = x k + t k p k x_{k+1}=x_{k}+t_{k}p_{k} xk+1=xk+tkpk
其中
t k = − p k T g k p k T Q p k = g k T g k p k T Q p k ≠ 0 t_{k} = - \frac{p_{k}^{T} g_{k}}{p_{k}^{T} Q p_{k}} = \frac{g_{k}^{T} g_{k}}{p_{k}^{T} Q p_{k}} \neq 0 tk=−pkTQpkpkTgk=pkTQpkgkTgk=0
以上就是共轭梯度法得核心内容。
Fletcher-Reeves共轭梯度法
为使共轭梯度算法也适用于非二次函数,需要消去算法中的 Q Q Q对于正定二次函数,有 Q p k = 1 t k ( g k + 1 − g k ) Qp_{k}=\frac{1}{t_{k}}(g_{k+1}-g_{k}) Qpk=tk1(gk+1−gk)代入到 α k \alpha_{k} αk中,得:
α k = g k + 1 T Q p k p k T Q p k = g k + 1 T ( g k + 1 − g k ) p k T ( g k + 1 − g k ) \alpha_{k}=\frac{g_{k+1}^{T} Q p_{k}}{p_{k}^{T} Q p_{k}}=\frac{g_{k+1}^{T}\left(g_{k+1}-g_{k}\right)}{p_{k}^{T}\left(g_{k+1}-g_{k}\right)} αk=pkTQpkgk+1TQpk=pkT(gk+1−gk)gk+1T(gk+1−gk)
此式中已不再出现矩阵 Q Q Q,将 p k = − g k + α k − 1 p k − 1 p_{k}=-g_{k} + \alpha _{k-1} p_{k-1} pk=−gk+αk−1pk−1两端转置运算,并同时右乘 g k + 1 g_{k+1} gk+1得:
p k T g k + 1 = − g k T g k + 1 + α k − 1 p k − 1 T g k + 1 p_{k}^{T}g_{k+1}=-g_{k}^{T}g_{k+1} + \alpha _{k-1} p_{k-1}^{T}g_{k+1} pkTgk+1=−gkTgk+1+αk−1p