数据结构_B-树
B-树
从严格意义上讲B-数并不是二分查找树,在物理上B-树的每个节点可以包含多个分支,但是从逻辑上讲,它等同于二分查找树。为了了解B-树,首先要了解以下几个方面的内容。
1、越来越小的内存
事实上:内存容量的增长速度时要远远小于问题数据规模的增长速度,例如:
典型的数据库规模 / 内存容量
1980:10MB / 1MB = 10
2000:1TB / 1GB = 1000
2010: …
相对而言:内存容量是在不断地减小的。直观的方法,我们可以把内存容量做的更大,但是我们存在着一个选择,即是:存储器的容量越大/小,访问速度就越慢/快。
2、高速缓存
面对存储器速度和大小之间的内在矛盾,高速缓存是一种行之有效的方法。
事实1:不同容量的存储器,访问速度的差异悬殊。
以磁盘与内存为例:ms / ns >10^5 > 246060,这种差异其实就是一秒之于一天,也就是说若一次内存访问需要一秒,则一次外存访问就相当于一天,显然这种差异是巨大的,因此,为了避免1次外存访问,我们宁愿访问内存10次、100次…。
鉴于以上原因,多数的存储系统,都是分级组织的,如下图所示:

随着层次的深入,存储器的容量越来越大,但是反过来访问的速度越来越慢。最常用的数据尽可能放在更高层、更小的存储器中。不常用的数据,会自适应的转移的速度更慢但是更大的级别中去。两个相邻存储级别之间的数据传输,称之为一次I/O。由于各级存储器的访问速度相差悬殊,所以我们应该尽可能的减少I/O次数,所以,算法的实际运行时间往往主要取决于算法的I/O复杂度。当访问一个数据时,在实在找不到的时候,才向更底层、更大的存储器索取。
事实2:从磁盘中读写1B,于读写1KB几乎一样快。
实际上,是采用批量式访问,以页或块为单位借助中间层存储器作为缓存。

因此,在涉及频繁而大量数据访问的算法中,我们要使用批量式访问,要么一次读写若干个KB,要么一次也不访问。这篇文章所要介绍的B-树,就可以在多级存储系统中减少磁盘操作次数,下面首先认识一下B-树的结构,如下图:
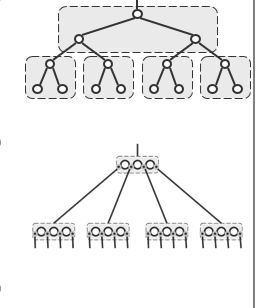
多路平衡搜索树
B-树是一种平衡的多路搜索树,这样一种多路搜索树与二叉搜索树本质上是等价的。
我们将多路搜索树中的每一个节点定义为超级节点,每一个超级节点都可以看作是二路节点合并得到的,例如:
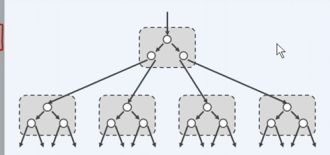
上图中,我们无视方框,其实就是一个二路搜索树,我们两层两层的考察这些节点,我们将这些节点合成一个超级节点,那么就可以等价为以下形式:

因此,可以看出:
每2代合并:4路,3个关键码。
每3代合并:8路,7个关键码。
…
每d代合并:m=2^d路,m-1个关键码。
逻辑上与BBST没有区别,为何要引入B-树呢?主要是因为,多级存储系统中使用B-树,可针对外部查找,大大减少I/O次数,从而大大提高时间效率,例如:
对于AVL树来说,假如有n=1G个记录,每次查找需要log(2,10^9)=30次I/O操作,每次只读出一个关键码,划不来。
对于B-树来说,可以充分利用外存对批量访问的支持,将此特点转换为优点,每次下降一层,都以超级节点为单位,读入一组关键码。
超级节点:

一组多大,视磁盘的数据块大小而定,对于上例,若取m=256,则每次查找只需要log(256,10^9)<=4次I/O。
B-树定义
所谓m阶B-树,即m路平衡搜索树(m>=2)。作为B-树的特征,所有叶节点的深度统一相等,**外部节点(叶节点的数值为空的孩子)**的深度统一相等,对于B-树而言,树的深度是相对于外部节点而言的即:h=外部节点的深度,如下图:
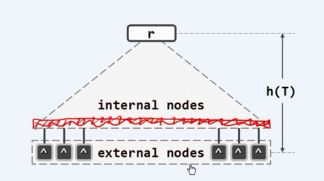
对于m阶B-树,每个内部节点都存有不超过m-1个关键码,以及不超过m个分支。此外每个节点的分支树也有下限,例如:
对于含有n个关键码的节点
K1 < K2 < … < Kn
它含有的分支数:
A0 , A1 , A2 ,…, An
对于树根而言,n+1>=2 ;其余节点 n+1>=m/2(向上取整)。所以,可以称作([m/2],m)-树,例如:(2,4)树。
B-树可以表示为如下紧凑形式:

B-树实现
B-树节点类BTnode的实现,每一个超级节点可以实现为两个向量,一个包含n个关键码,另一个包含n+1个分支,如下:
#include "vector/vector.h"
#define BTNodePosi(T) BTNode* //B-树节点位置
template struct BTNode { //B-树节点模板类
// 成员(为简化描述起见统一开放,读者可根据需要进一步封装)
BTNodePosi(T) parent; //父节点
Vector key; //关键码向量
Vector child; //孩子向量(其长度总比key多一)
// 构造函数(注意:BTNode只能作为根节点创建,而且初始时有0个关键码和1个空孩子指针)
BTNode() { parent = NULL; child.insert ( 0, NULL ); }
BTNode ( T e, BTNodePosi(T) lc = NULL, BTNodePosi(T) rc = NULL ) {
parent = NULL; //作为根节点,而且初始时
key.insert ( 0, e ); //只有一个关键码,以及
child.insert ( 0, lc ); child.insert ( 1, rc ); //两个孩子
if ( lc ) lc->parent = this; if ( rc ) rc->parent = this;
}
};
B-树模板类可以实现如下:
#include "BTNode.h" //引入B-树节点类
template class BTree { //B-树模板类
protected:
int _size; //存放的关键码总数
int _order; //B-树的阶次,至少为3——创建时指定,一般不能修改
BTNodePosi(T) _root; //根节点
BTNodePosi(T) _hot; //BTree::search()最后访问的非空(除非树空)的节点位置
void solveOverflow ( BTNodePosi(T) ); //因插入而上溢之后的分裂处理
void solveUnderflow ( BTNodePosi(T) ); //因删除而下溢之后的合并处理
public:
BTree ( int order = 3 ) : _order ( order ), _size ( 0 ) //构造函数:默认为最低的3阶
{ _root = new BTNode(); }
~BTree() { if ( _root ) release ( _root ); } //析构函数:释放所有节点
int const order() { return _order; } //阶次
int const size() { return _size; } //规模
BTNodePosi(T) & root() { return _root; } //树根
bool empty() const { return !_root; } //判空
BTNodePosi(T) search ( const T& e ); //查找
bool insert ( const T& e ); //插入
bool remove ( const T& e ); //删除
}; //BTree
- B-树查找算法实现
B-树结构非常适宜于在相对更小的内存中,实现对大规模数据的高效操作。一般的,可以将大数据集组织为B-树存放于外存中。对于活跃的B-树,其根节点会常驻与内存;此外,任何时刻通常只有另一节点(称作当前节点)留驻于内存。如下图所示:
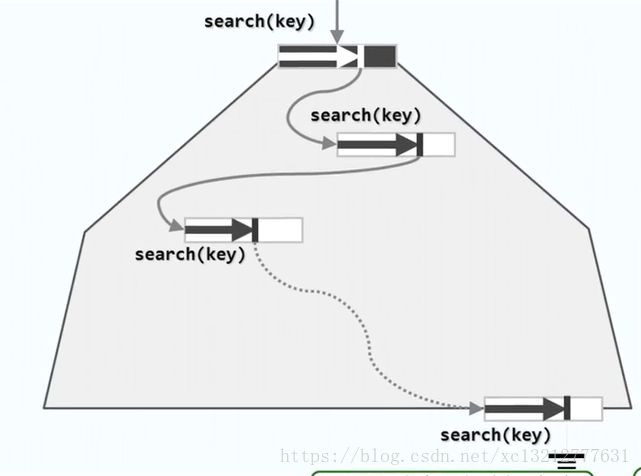
查找过程如上图所示:二分查找+顺序查找。令当前指针指向根节点,只要当前指针非空,将当前节点整体读入内存(I/O),在当前节点中顺序查找(RAM),如果找到关键码,则返回查找成功,否则得到另一个指向下一层的指针。只有在切换和更新当前节点时才会发生I/O操作,而在同一节点内部的查找完全在内存中进行。因内存访问的速度远远高于外存,故可直接采用顺序查找策略,不必采用二分查找,实现如下:
template BTNodePosi(T) BTree::search ( const T& e ) { //在B-树中查找关键码e
BTNodePosi(T) v = _root; _hot = NULL; //从根节点出发
while ( v ) { //逐层查找
Rank r = v->key.search ( e ); //在当前节点中,找到不大于e的最大关键码
if ( ( 0 <= r ) && ( e == v->key[r] ) ) return v; //成功:在当前节点中命中目标关键码
_hot = v; v = v->child[r + 1]; //否则,转入对应子树(_hot指向其父)——需做I/O,最费时间
} //这里在向量内是二分查找,但对通常的_order可直接顺序查找
return NULL; //失败:最终抵达外部节点
}
成功时返回目标关键码所在的节点,上层调用过程可以在该节点内部进一步查找确定准确的命中位置;失败时返回对应的外部节点(可能指向存储级别更低的B-树),其父节点由变量_hot指代。
复杂度分析:
B-树查找操作所需要的时间主要有两个因素:将某一个节点载入内存,以及在内存中对当前节点的查找。由于内存、外村在访问速度上的差异,后一类时间消耗可以忽略不计,也就是说B-树查找操作的效率主要取决于外存的访问次数。
B-树的每一次查找过程中,在每一个高度上至多访问一个节点。意味着,对于高度为h的B-树,外存访问不超过O(h-1)次。而对于树高h与节点个数有何关系?
树高h(由外部节点的深度决定的):

1、最大树高h:
对于含N个关键码的m阶B-树,若要使其高度最大,则内部节点应该尽可能“瘦”(取内部节点满足的下届),各层的节点数依次为:

考察外部节点(关键码个数为N,则外部节点数目为N+1,相应的N种查找成功可能,N+1种查找失败可能)所在层:

B-树的意义不在于降低渐近意义下的复杂度,在于降低常数意义下的复杂度,相对于BBST:

例如:

2、最小树高h:
对于含N个关键码的m阶B-树,若要使其高度最低,则内部节点应该尽可能“胖”(取内部节点满足的上届),各层的节点数依次为:
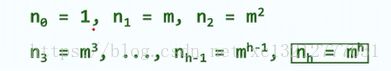
考察外部节点所在的层:

同样的与BBST做对比:

例如:

综合起来,在关键码个数固定的时候,B-树上下浮动的范围是十分有限的。
因此,每次查找过程共需要访问O(logm(N))个节点,相应的需要做O(logm(N))次外存读取操作。则对于含有N个关键码的m阶B-树的每次查找操作,耗时不超过O(logm(N)),虽然相对于BBST没有渐近意义上的改进,但是却大大减少了I/O操作的次数,减少为原来的1/log2(m)。
- B-树插入算法实现
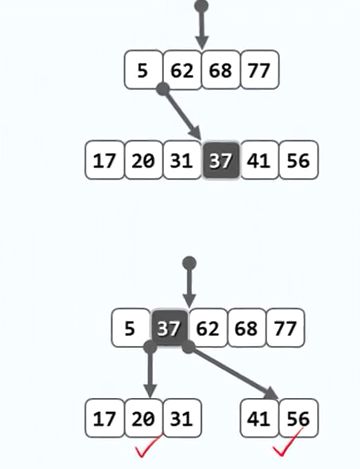
插入的过程如下图: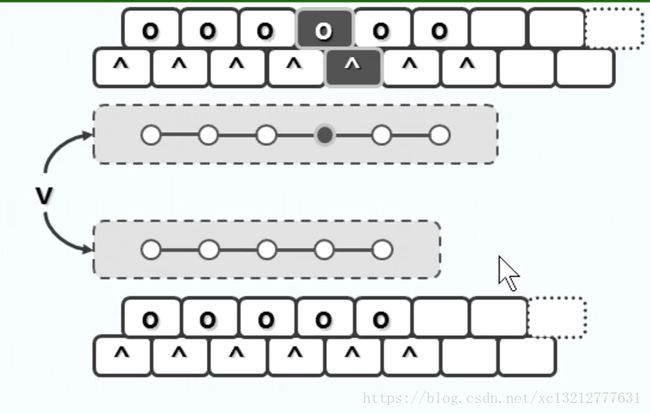
可实现为:
template bool BTree::insert ( const T& e ) { //将关键码e插入B树中
BTNodePosi(T) v = search ( e ); if ( v ) return false; //确认目标节点不存在
Rank r = _hot->key.search ( e ); //在节点_hot的有序关键码向量中查找合适的插入位置
_hot->key.insert ( r + 1, e ); //将新关键码插至对应的位置
_hot->child.insert ( r + 2, NULL ); //创建一个空子树指针
_size++; //更新全树规模
solveOverflow ( _hot ); //如有必要,需做分裂
return true; //插入成功
}
为了在B-树中插入一个新的关键码e,首先调用search(e)在树中查找该关键码,查找过程必然终止于某一外部节点,且其父节点由变量_hot指示。接下来,在该节点中再次查找关键码e,就可以确定e在其中的插入位置r,但是此时可能由于插入操作使得该节点发生了上溢(超出了B-树的阶次),此时要进行处理。
上溢与分裂:
一般刚发生上溢的节点,应该含有m个关键码,依次为:

取中位数s=m/2(向下取整),以关键码Ks为界划分为:

可见,以Ks为界,可以将该节点分前、后两个子节点,且长度相当。于是,可以让关键码Ks上升一层,归入其父节点的适当的位置,并分别以这两个子节点作为其左、右孩子。这一过程为分裂。例如:
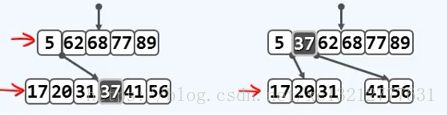
1、原上溢节点的父节点存在,且足以接纳一个关键码,如下图:
2、尽管上溢节点的父节点存在,但是它已处于饱和状态,在强行被提升的关键码插入父节点之后,会导致父节点继而发生上溢,这种现象可能持续发生,但是只能向上,最坏不过是到树根。如下图:
3、上溢传递到树根时,可以让被提升的关键码自成一个节点,并且作为新树根。如下图所示,此时全树增高一层(导致B-树增高的唯一情况)。并且整个过程所做的分裂次数不超过全树的高度(O(logm(N)))。这也是为什么再定义B-树时,根节点作为特例要满足n+1>=2。

上溢分裂实现如下:
template //关键码插入后若节点上溢,则做节点分裂处理
void BTree::solveOverflow ( BTNodePosi(T) v ) {
if ( _order >= v->child.size() ) return; //递归基:当前节点并未上溢
Rank s = _order / 2; //轴点(此时应有_order = key.size() = child.size() - 1)
BTNodePosi(T) u = new BTNode(); //注意:新节点已有一个空孩子
for ( Rank j = 0; j < _order - s - 1; j++ ) { //v右侧_order-s-1个孩子及关键码分裂为右侧节点u
u->child.insert ( j, v->child.remove ( s + 1 ) ); //逐个移动效率低
u->key.insert ( j, v->key.remove ( s + 1 ) ); //此策略可改进
}
u->child[_order - s - 1] = v->child.remove ( s + 1 ); //移动v最靠右的孩子
if ( u->child[0] ) //若u的孩子们非空,则
for ( Rank j = 0; j < _order - s; j++ ) //令它们的父节点统一
u->child[j]->parent = u; //指向u
BTNodePosi(T) p = v->parent; //v当前的父节点p
if ( !p ) { _root = p = new BTNode(); p->child[0] = v; v->parent = p; } //若p空则创建之
Rank r = 1 + p->key.search ( v->key[0] ); //p中指向u的指针的秩
p->key.insert ( r, v->key.remove ( s ) ); //轴点关键码上升
p->child.insert ( r + 1, u ); u->parent = p; //新节点u与父节点p互联
solveOverflow ( p ); //上升一层,如有必要则继续分裂——至多递归O(logn)层
}
由上可以得到B-树的插入操作,时间复杂度线性正比于树高h。
插入实例:

- B-树的删除算法
B-树的删除操作可以具体实现如下:
template bool BTree::remove ( const T& e ) { //从BTree树中删除关键码e
BTNodePosi(T) v = search ( e ); if ( !v ) return false; //确认目标关键码存在
Rank r = v->key.search ( e ); //确定目标关键码在节点v中的秩(由上,肯定合法)
if ( v->child[0] ) { //若v非叶子,则e的后继必属于某叶节点
BTNodePosi(T) u = v->child[r+1]; //在右子树中一直向左,即可
while ( u->child[0] ) u = u->child[0]; //找出e的后继
v->key[r] = u->key[0]; v = u; r = 0; //并与之交换位置
} //至此,v必然位于最底层,且其中第r个关键码就是待删除者
v->key.remove ( r ); v->child.remove ( r + 1 ); _size--; //删除e,以及其下两个外部节点之一
solveUnderflow ( v ); //如有必要,需做旋转或合并
return true;
}
为了从B-树中删除关键码e,首先调用search(e)接口查找e所属的节点,若查找成功,则通过顺序查找,就可以进一步确定e在节点v中的位置。同样,删除操作可能使节点不在满足B-树要求,即可能发生了下溢,此时要进行处理。
下溢与合并:
在m阶B-树中,刚发生下溢的节点V必然恰好包含:

此时根据其左、右兄弟所含关键码的数目,分三种情况做相应处理:
1、V的左兄弟L存在,且至少包含m/2(向上取整)个关键码,如下图所示:

此时,设L和V分别是其父节点p中关键码y的左、右孩子,L中最大关键码x(x<=y)。此时可以如下图,将y从节点p转移至v中(作为最小关键码),再将x从L中转移至p中取代原关键码y。(转借)

2、V的右兄弟R存在,且至少包含m/2(向上取整)个关键码。
此时,情况与第一种情况对称,不再赘述。
3、V的左、右兄弟L和R或者不存在,或者其包含的关键码均不足m/2(向上取整)个。此时可按下图处理:
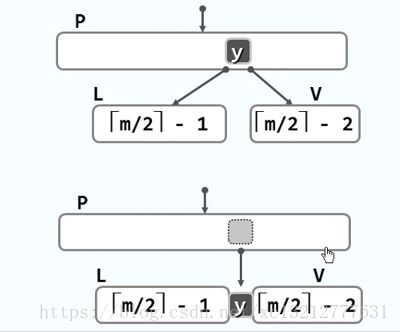
为了修复节点V的下溢,可以从父节点P中抽出介于L和V之间的关键码y,并且通过该关键码将节点L和V合成一个大节点。此时还必须检查父节点p,他可能由于借出一个节点而发生下溢,此时可按如上方法解决下溢。当然,修复之后,仍然可能使得下溢向上传递,但是,与上溢情况类似,每一次修复,新下溢节点会上升一层,特别地,当下溢传至根节点时且其中不在包含任何关键码的时候,即可将其删除并且让合并后的节点作为新的根节点,全树的高度下降一层。可以看出,整个下溢过程,至多需要O(logm(N))次合并操作。
可以实现如下:
template //关键码删除后若节点下溢,则做节点旋转或合并处理
void BTree::solveUnderflow ( BTNodePosi(T) v ) {
if ( ( _order + 1 ) / 2 <= v->child.size() ) return; //递归基:当前节点并未下溢
BTNodePosi(T) p = v->parent;
if ( !p ) { //递归基:已到根节点,没有孩子的下限
if ( !v->key.size() && v->child[0] ) {
//但倘若作为树根的v已不含关键码,却有(唯一的)非空孩子,则
_root = v->child[0]; _root->parent = NULL; //这个节点可被跳过
v->child[0] = NULL; release ( v ); //并因不再有用而被销毁
} //整树高度降低一层
return;
}
Rank r = 0; while ( p->child[r] != v ) r++;
//确定v是p的第r个孩子——此时v可能不含关键码,故不能通过关键码查找
//另外,在实现了孩子指针的判等器之后,也可直接调用Vector::find()定位
// 情况1:向左兄弟借关键码
if ( 0 < r ) { //若v不是p的第一个孩子,则
BTNodePosi(T) ls = p->child[r - 1]; //左兄弟必存在
if ( ( _order + 1 ) / 2 < ls->child.size() ) { //若该兄弟足够“胖”,则
v->key.insert ( 0, p->key[r - 1] ); //p借出一个关键码给v(作为最小关键码)
p->key[r - 1] = ls->key.remove ( ls->key.size() - 1 ); //ls的最大关键码转入p
v->child.insert ( 0, ls->child.remove ( ls->child.size() - 1 ) );
//同时ls的最右侧孩子过继给v
if ( v->child[0] ) v->child[0]->parent = v; //作为v的最左侧孩子
return; //至此,通过右旋已完成当前层(以及所有层)的下溢处理
}
} //至此,左兄弟要么为空,要么太“瘦”
// 情况2:向右兄弟借关键码
if ( p->child.size() - 1 > r ) { //若v不是p的最后一个孩子,则
BTNodePosi(T) rs = p->child[r + 1]; //右兄弟必存在
if ( ( _order + 1 ) / 2 < rs->child.size() ) { //若该兄弟足够“胖”,则
v->key.insert ( v->key.size(), p->key[r] ); //p借出一个关键码给v(作为最大关键码)
p->key[r] = rs->key.remove ( 0 ); //ls的最小关键码转入p
v->child.insert ( v->child.size(), rs->child.remove ( 0 ) );
//同时rs的最左侧孩子过继给v
if ( v->child[v->child.size() - 1] ) //作为v的最右侧孩子
v->child[v->child.size() - 1]->parent = v;
return; //至此,通过左旋已完成当前层(以及所有层)的下溢处理
}
} //至此,右兄弟要么为空,要么太“瘦”
// 情况3:左、右兄弟要么为空(但不可能同时),要么都太“瘦”——合并
if ( 0 < r ) { //与左兄弟合并
BTNodePosi(T) ls = p->child[r - 1]; //左兄弟必存在
ls->key.insert ( ls->key.size(), p->key.remove ( r - 1 ) ); p->child.remove ( r );
//p的第r - 1个关键码转入ls,v不再是p的第r个孩子
ls->child.insert ( ls->child.size(), v->child.remove ( 0 ) );
if ( ls->child[ls->child.size() - 1] ) //v的最左侧孩子过继给ls做最右侧孩子
ls->child[ls->child.size() - 1]->parent = ls;
while ( !v->key.empty() ) { //v剩余的关键码和孩子,依次转入ls
ls->key.insert ( ls->key.size(), v->key.remove ( 0 ) );
ls->child.insert ( ls->child.size(), v->child.remove ( 0 ) );
if ( ls->child[ls->child.size() - 1] ) ls->child[ls->child.size() - 1]->parent = ls;
}
release ( v ); //释放v
} else { //与右兄弟合并
BTNodePosi(T) rs = p->child[r + 1]; //右兄度必存在
rs->key.insert ( 0, p->key.remove ( r ) ); p->child.remove ( r );
//p的第r个关键码转入rs,v不再是p的第r个孩子
rs->child.insert ( 0, v->child.remove ( v->child.size() - 1 ) );
if ( rs->child[0] ) rs->child[0]->parent = rs; //v的最左侧孩子过继给ls做最右侧孩子
while ( !v->key.empty() ) { //v剩余的关键码和孩子,依次转入rs
rs->key.insert ( 0, v->key.remove ( v->key.size() - 1 ) );
rs->child.insert ( 0, v->child.remove ( v->child.size() - 1 ) );
if ( rs->child[0] ) rs->child[0]->parent = rs;
}
release ( v ); //释放v
}
solveUnderflow ( p ); //上升一层,如有必要则继续分裂——至多递归O(logn)层
return;
}
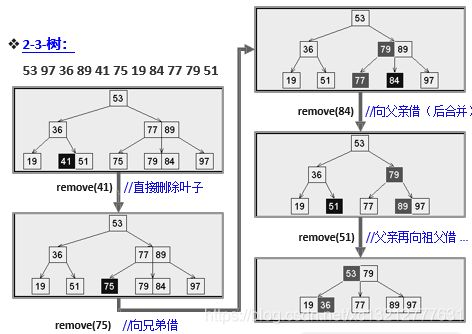
删除操作实例:
总结
所谓对B-树的访问,是一系列的外存操作与内存操作交替组成。为了保证高的访问率,所以使,外存操作代价与内存操作代价相当,所以B-树设计的矮胖。