SparkSQL 通过加载csv文件创建dataframe的常用方式总结
背景
DataFrame可以从结构化文件(csv、json、parquet)、Hive表以及外部数据库构建得到,本文主要整理通过加载csv文件来创建Dataframe的方法
使用的数据集——用户行为日志user_log.csv,csv中自带首行列头信息,字段定义如下:
1. user_id | 买家id
2. item_id | 商品id
3. cat_id | 商品类别id
4. merchant_id | 卖家id
5. brand_id | 品牌id
6. month | 交易时间:月
7. day | 交易事件:日
8. action | 行为
9. age_range | 买家年龄分段
10. gender | 性别
11. province| 收获地址省份
新手上路,有任何搞错的地方,或者走了弯路,还请大家不吝指出,帮我进步。
创建dataframe的四种方式
- 1. 使用SparkSession直接读取CSV文件创建
- 2. 使用StructType和RDD[Row]创建
- 3. 转换RDD生成
- 4. 使用case class 和 toDF创建
- ► 小结
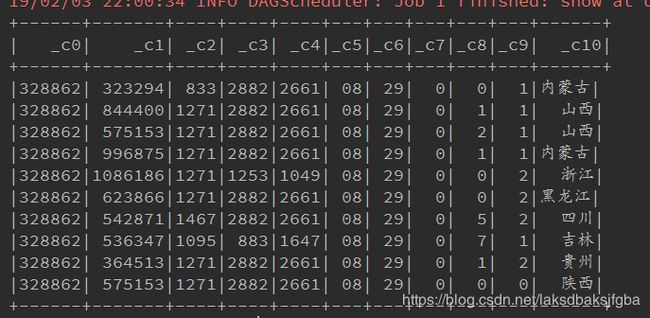
1. 使用SparkSession直接读取CSV文件创建
object UserAnalysis {
def main(args:Array[String]): Unit ={
//测试数据所在的本地路径
val userDataPath = "file:///home/hadoop/data_format/small_user_log.csv"
//创建sparksession
val sparkSession = SparkSession
.builder
.master("local")
.appName("UserAnalysis")
.enableHiveSupport() //启用hive
.getOrCreate()
//sparksession直接读取csv,可设置分隔符delimitor.
val userDF = sparkSession.read
.option("header","true") //如果csv文件中第一行有列头信息,需要在这里设置header为true
//.option("delimiter","|") csv文件默认分隔符是逗号,如果csv文件内容以竖线分隔,使用这种方式重新指定
.csv(userDataPath)
//显示DataFrame的前10行数据
userDF.show(10)
//将DataFrame注册成视图,然后可使用hql访问
userDF.createOrReplaceTempView("userDF")
//执行hql语句,生成一个新DataFrame
val provinceDF = sparkSession.sql("select province from userDF")
//显示DataFrame的前十行数据
provinceDF.show(10)
}
}
注意:如果csv文件中第一行没有列头信息,使用option("header","false")这种方式,读csv创建DataFrame后会生成默认表头
2. 使用StructType和RDD[Row]创建
object UserAnalysis {
def main(args:Array[String]): Unit ={
//定义一个表结构,要和待加载的csv内容逐列对应上
val schema = StructType(List(
StructField("user_id", StringType, nullable = false),
StructField("item_id", StringType, nullable = false),
StructField("cat_id", StringType, nullable = false),
StructField("merchant_id", StringType, nullable = false),
StructField("brand_id", StringType, nullable = false),
StructField("month", StringType, nullable = false),
StructField("day", StringType, nullable = false),
StructField("action", StringType, nullable = false),
StructField("age_range", StringType, nullable = false),
StructField("gender", StringType, nullable = false),
StructField("province", StringType, nullable = false)
))
//测试数据所在的本地路径
val userDataPath = "file:///home/hadoop/data_format/small_user_log_noheader.csv"
//创建sparksession
val sparkSession = SparkSession
.builder
.master("local")
.appName("UserAnalysis")
.enableHiveSupport() //启用hive
.getOrCreate()
//将csv读取成RDD[String]
val lineRdd = sparkSession.sparkContext.textFile(userDataPath)
//将RDD[String]转换成RDD[Row]
val rowRDD = lineRdd.map { x => {
val split = x.split(",")
// val splitx.split("\\|") 如果csv文件内容以竖线分隔,使用这种方式切分,注意需要转义
RowFactory.create(split(0),split(1),split(2),split(3),split(4),split(5),
split(6),split(7),split(8),split(9),split(10))
}
}
//调用SparkSession的方法把RDD[Row]转换成DataFrame
val userDF = sparkSession.createDataFrame(rowRDD,schema)
//显示DataFrame的前10行数据
userDF.show(10)
//将DataFrame注册成视图,然后即可使用hql访问
userDF.createOrReplaceTempView("userDF")
//执行hql语句,生成一个新DataFrame
val provinceDF = sparkSession.sql("select province from userDF")
//显示DataFrame的前十行数据
provinceDF.show(10)
}
}
注意:如果csv文件内容第一行是列头信息,按这种方式创建DataFrame会看到如下情况,甚至可能会因 字段类型转换失败而报错,例如:user_id这个字符串没法转换成int
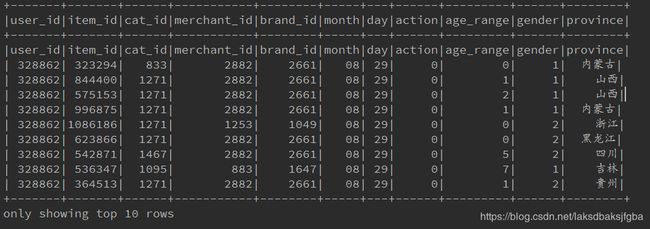
3. 转换RDD生成
object UserAnalysis {
def main(args:Array[String]): Unit = {
//测试数据所在的本地路径
val userDataPath = "file:///home/hadoop/data_format/small_user_log.csv"
//创建sparksession
val sparkSession = SparkSession
.builder
.master("local")
.appName("UserAnalysis")
.enableHiveSupport() //启用hive
.getOrCreate()
//将csv读取成RDD[String]
val lineRdd = sparkSession.sparkContext.textFile(userDataPath)
//导入隐式转换,否则RDD无法调用toDF方法
val sqlContext = sparkSession.sqlContext
import sqlContext.implicits._
//将RDD[String]转换成元组,然后调用toDF方法创建DataFrame
val userDF = lineRdd.map{{x=>
val split = x.split(",")
// val splitx.split("\\|") 如果csv文件内容以竖线分隔,使用这种方式切分,注意需要转义
(split(0),split(1),split(2),split(3),split(4),split(5),split(6),
split(7),split(8),split(9),split(10))
}
}.toDF("A","B","C","D","E","F","G","H","I","J","K")
//显示DataFrame的前10行数据
userDF.show(10)
//将DataFrame注册成视图,然后即可使用hql访问
userDF.createOrReplaceTempView("userDF")
//执行hql语句,生成一个新DataFrame
val provinceDF = sparkSession.sql("select K from userDF")
//显示DataFrame的前十行数据
provinceDF.show(10)
}
}
注意:如果csv文件内容第一行是列头信息,按方式三创建DataFrame会看到如下情况,甚至可能会因 字段类型转换失败而报错,例如:user_id这个字符串没法转换成int
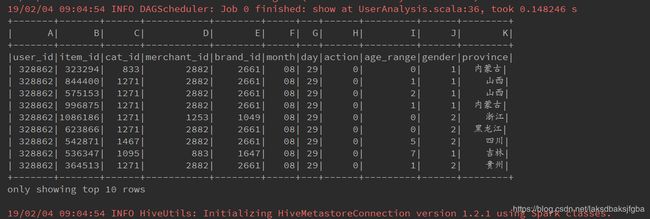
注意:如果调用toDF方法时没有指定列头名称,就会被指定默认值,如下图
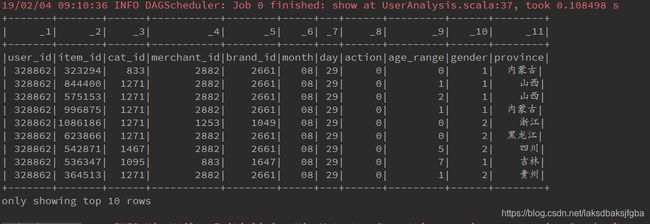
4. 使用case class 和 toDF创建
case class User(user_id:String,item_id:String,cat_id:String,merchant_id:String,brand_id:String,month:String,day:String,
action:String,age_range:String,gender:String,province:String)
object UserAnalysis {
def main(args:Array[String]): Unit = {
//测试数据所在的本地路径
val userDataPath = "file:///home/hadoop/data_format/small_user_log.csv"
//创建sparksession
val sparkSession = SparkSession
.builder
.master("local")
.appName("UserAnalysis")
.enableHiveSupport() //启用hive
.getOrCreate()
//将csv读取成RDD[String]
val lineRdd = sparkSession.sparkContext.textFile(userDataPath)
//导入隐式转换,否则RDD无法调用toDF方法
val sqlContext = sparkSession.sqlContext
import sqlContext.implicits._
//将RDD[String]转换成元组,然后调用toDF方法创建DataFrame
val userDF = lineRdd.map{{x=>
val split = x.split(",")
// val splitx.split("\\|") 如果csv文件内容以竖线分隔,使用这种方式切分,注意需要转义
User(split(0),split(1),split(2),split(3),split(4),split(5),split(6),
split(7),split(8),split(9),split(10))
}
}.toDF()
//显示DataFrame的前10行数据
userDF.show(10)
//将DataFrame注册成视图,然后即可使用hql访问
userDF.createOrReplaceTempView("userDF")
//执行hql语句,生成一个新DataFrame
val provinceDF = sparkSession.sql("select province from userDF")
//显示DataFrame的前十行数据
provinceDF.show(10)
}
}
注意:如果csv文件内容第一行是列头信息,按方式四创建DataFrame会看到如下情况,甚至会因 字段类型转换失败而报错,例如:user_id这个字符串没法转换成int
注意:如果调用toDF方法时没有指定列头名称,则会以case class的参数名称为列头名;
如果调用toDF方法时指定了列头名称,则会显示toDF方法指定的列头名称
不上图了。。。
另外,在scala 2.10中最大支持22个字段的case class,这点需要注意
► 小结
-
关于处理csv文件中首行列头信息
第一种创建方式,可以通过设置option中的header属性来控制是否读取csv文件第一行为列头。
即如果有列头,设置为true,反之则设置为false。无论是加载单个文件还是批量加载都没问题。其它三种创建方式,使用textFile加载csv文件,可能需要使用filter来过滤掉所有csv文件的首行列头信息
-
关于字段类型和字段名称
第一种创建方式,在创建好dataframe之前,似乎没法指定字段名称和字段类型,字段名称要么是csv文件行首自带的要么是spark生成的,字段类型似乎全部默认为String。但是我们能通过dataframe的withColumn方法和withColumnRenamed方法修改它们,如下://转换dataframe字段类型或字段名 import org.apache.spark.sql.functions._ userDF = userDF.withColumn("user_id", col("user_id").cast(IntegerType)) .withColumn("item_id", col("item_id").cast(IntegerType)) .withColumn("cat_id", col("cat_id").cast(IntegerType)) .withColumn("merchant_id", col("merchant_id").cast(IntegerType)) .withColumn("brand_id", col("brand_id").cast(IntegerType)) .withColumn("month", col("month").cast(IntegerType)) .withColumn("day", col("day").cast(IntegerType)) .withColumn("action", col("action").cast(IntegerType)) .withColumn("age_range", col("age_range").cast(IntegerType)) .withColumn("gender", col("gender").cast(IntegerType)) .withColumnRenamed("province","省份")第二种创建方式,我们可以在定义StructType时指定字段名称和类型
第三种创建方式,我们可以在将RDD[String]转换成元组时指定字段类型,在调用toDF时指定字段名称,如下://将RDD[String]转换成元组,然后调用toDF方法创建DataFrame val userDF = lineRdd.map{{x=> val split = x.split(",") (Integer.parseInt(split(0)), Integer.parseInt(split(1)), Integer.parseInt(split(2))) } }.toDF("A","B","C")第四种创建方式,我们可以在定义case class时指定字段名称和类型,在调用toDF时也能指定字段名称,
toDF里指定的的名称优先级更高。
这样看来,以上几种创建dataframe的方式各有优劣,所以还是要根据实际应用场景来择取最方便的途径吧。