#SAS学习-BASE SAS常用语法汇总
BASE SAS模块是SAS中用得最为频繁的模块,经过一段时间的学习,也大致对常用的语法进行了学习,今晚有空就做一下总结归纳呗~


BASE SAS 功能
数据管理功能
基础统计计算功能
报表生成和图形显示功能
数据导入
这里主要讲比较常用的2种,一种是import方式,另一种是infile方式,其中本人最喜欢的是import方式,但是有的时候由于种种限制还是要用infile,或者其他更为复杂的方式,这里就总结归纳一些常用常见的呗。
1. import方式:
/* 导入Excel文件 */
proc import out = Practice.app2
datafile = "F:\homework\XXX.xls"
dbms = excel replace;
sheet = "Sheet$";
getnames = yes;
format DESIRED_LOAN_AMOUNT comma15.2
ACCPT_MAX_REPAYMENT comma15.2
apply_date: mmddyy10.;
run;
/* 导入csv文件 */
proc import out = Practice.app2
datafile = "F:\homework\XXX.csv"
dbms = csv replace;
delimiter= "|";
getnames = yes;
format DESIRED_LOAN_AMOUNT comma15.2
ACCPT_MAX_REPAYMENT comma15.2
apply_date: mmddyy10.;
run;
2. infile方式:
data practice.app4;
infile 'F:\homework\作业1_2\app1.csv'
delimiter = ',' missover dsd lrecl=32767 firstobs=2 ;
informat DESIRED_LOAN_AMOUNT 15. ACCPT_MAX_REPAYMENT 15. DESIRED_PRODUCT_NAME $20. ID $10. mob $11. apply_date 10.;
format DESIRED_LOAN_AMOUNT COMMA15.2 ACCPT_MAX_REPAYMENT COMMA15.2 DESIRED_PRODUCT_NAME $20. apply_date MMDDYY10. mob $11.;
INPUT DESIRED_LOAN_AMOUNT ACCPT_MAX_REPAYMENT DESIRED_PRODUCT_NAME ID apply_date mob ;
RUN;
数据处理——DATA步(数据步)
data步一般就是对原始数据文件进行转换,变成SAS可以处理的数据集,它的一般形式是:
DATA SAS-data-set;
infile 'filename' option;
input 语句;
其他SAS语句;
RUN;
下面对data步几个比较重要并且常见的语法(句)进行归纳总结。
1. Keep语句(对应的相反语句是drop语句)
语法结构:Keep variable-list
这里特别注意一下Keep语句和Keep=选项的区别。
data a3;
set sashelp.class;
keep Nameage;
run;
data a4;
set sashelp.class(keep=Nameage);
run;
2. Rename语句
语法结构:
Rename old-name=new-name;
data a2;
set sashelp.class(rename=(name=name_new));
run;
3. Label语句
语法结构:Label variable=‘label’;
4. Set语句
语法结构:
DATAnew;
set old;
其他语句;
RUN;
一般来说set是复制数据集并且通过一些参数和语句来对其进行操控,一般用得比较多的是:
KEEP=变量
DROP=变量
RENAME=表达式
WHERE=表达式
IN=变量
创建一标识变量,如果当前观测属于某数据集,标识为1,否则为0
FIRSTOBS=常数
如常数=3,表示从第3个观测开始读数据集
OBS=常数
如常数=10,表示读到的最后一个观测是第10个观测
5. IF语句
语法结构:IF 条件表达式;
一般if语句不会单独使用,都是会配合else if,else一起使用。
常用的操作符如下:
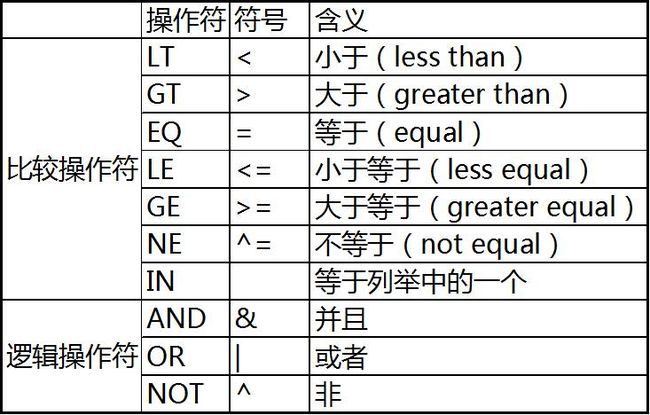
6. Where 语句
语法结构:Where 表达式;(Where = 选项)
where的用法和if差不多,但是两者还是有一些差别的,where操作的对象是一开始读入的数据集,而不能对在数据步中操作得到的新变量(系统一般会提示说变量未初始化),而if则能够实现。所以我们一般都是用if比较好。
7. Delete语句
语法结构:if 条件表达式 then delete;
8. By语句
By在SAS就是用来分组的,在后续会用得很多,此外,在DATA步中,SAS系统对每个BY组都会创建两个临时变量:First.variable以及Last .variable,它们用来区别每个BY组的第一个和最后一个观测值的,也是在后续的output筛选输出有很大作用。
9. Merge语句
语法结构:
Data 数据集;run;
Merge语句用于并接多个数据集,且要求输入数据集必须先按by变量排序。Merge是对数据集进行横向拼接的。
10 DO组语句
语法结构:
DO;
执行程序块;
END;
DO组语句规定,在DO后面直到出现END语句之前的这些语句作为一个单元被执行,常用在if-then/else语句里。
11. DO循环语句
语法结构:
DO 下标变量=初始值 to 终止值 by 步长;
循环程序块;
End;
12. 其他循环语句
(1)DO while
DO while (expression);
执行程序块;
end;
当条件成立时重复执行Do组里的语句n括号里的表达式在Do组里的语句被执行前在循环的开头被计算。如果表达式是真的,Do组被执行。
(2)DO UNTIL
DO UNTIL(expression);
执行程序块;
END;
连续执行Do组里的语句块直到UNTIL条件为真时退出循环n在循环的最后而不是在循环的开头计算表达式,expression在执行DO组内的执行语句块之后被计算。Do循环中的执行语句块至少被执行一次。
13. Retain语句
语法结构:retain x,y;
读sas数据集时,只在第一次迭代时把变量值置为缺失,以后变量保留其值直至新值写入。
数据处理——PROC步(过程步)
讲完了data步,就讲一下proc步呗。过程步是对已经处理好的数据进行分析统计,当然也是有一些十分常见和重要的语句。

1. PROC SORT语句
语法结构:
Proc sort data=数据集out=排序后的数据集;
by 变量;
run;
2. PROC APPEND语句
语法结构:
Proc append base=MD data=APD force;
run;
通俗的讲,将APD追加到数据集MD中(APD不做任何改变)
FORCE:如果APD的列结构跟MD不一致仍然强制加入,但只保留MD上有的列。
与set不同的是,使用set语句拼接数据集时,SAS将处理两个数据集的所有观测并产生一个新的数据集;而append过程避免处理原数据集中的数据,直接把新的观测添加到原数据集后面。
3. PROC TRANSPOSE语句
语法结构:
Proc transpose data = old out = new;
[VAR 变量序列;]
[ID 变量;]
[BY 变量序列;]
run;
ID语句中的变量的值将作为转置后新变量的变量名称n选项PREFIX=指定转置后新变量名的前缀。
BY语句中的变量为转置组,需排序,BY变量包含在输出数据集中但没有被转置。
对VAR语句中列出的变量转置,转置字符型变量时必须列出。
4. PROC FREQ语句
语法结构:
proc freq data=分析的数据集;
by variables; 分组变量
tables requests
< /out=新数据集> < /options >; 频数统计
run;
Options:norow nocol nopercent missing
5. PROC SQL语句
看到SQL真的是非常熟悉,SAS里面的SQL语法和SQL server的差不多,所以学起来也超级容易。
proc sql;
create table a3 as
select a1.x,
case when a2.x = . then a1.y
else a2.y
end as y
from a1 left join a2
on a1.x = a2.x;
quit;
主要重点需要掌握的是join操作,其他的都比较简单了。而且这里要区分SQL与merge的区分,主要总结如下:
Leftjoin 相当于merge中的if a
Rightjoin 相当于merge中的if b
Join/Innerjoin 相当于merge中的if a=b
Fulljoin 相当于merge中不使用IN=选项

好了,BASE SAS中比较重要的也总结完了,后续还是需要继续去熟悉这些语句,很多语句之间是可以嵌套使用的,同时也挖掘出更多其他好用的语句呗~