深度学习问题集锦
1) 什么样的资料集不适合用深度学习?
答:数据集太小,数据样本不足时,深度学习相对其它机器学习算法,没有明显优势;
数据集没有局部相关特性,目前深度学习表现比较好的领域主要是图像/语音/自然语言处理等领域,这些领域的一个共性是局部相关性。图像中像素组成物体,语音信号中音位组合成单词,文本数据中单词组合成句子,这些特征元素的组合一旦被打乱,表示的含义同时也被改变。对于没有这样的局部相关性的数据集,不适于使用深度学习算法进行处理。
2) 何为共线性, 跟过拟合有啥关联?
答:共线性:多变量线性回归中,变量之间由于存在高度相关关系而使回归估计不准确。
共线性会造成冗余,导致过拟合。
解决方法:排除变量的相关性/加入权重正则。
3) 什么造成梯度消失问题?
答:神经网络的训练中,通过改变神经元的权重,使网络的输出值尽可能逼近标签以降低误差值,训练普遍使用BP算法,核心思想是,计算出输出与标签间的损失函数值,然后计算其相对于每个神经元的梯度,进行权值的迭代。
梯度消失会造成权值更新缓慢,模型训练难度增加。造成梯度消失的一个原因是,许多激活函数将输出值挤压在很小的区间内,在激活函数两端较大范围的定义域内梯度为0。造成学习停止
4) 在神经网络训练开始前,都要对输入数据做一个归一化处理,那么具体为什么需要归一化呢?归一化后有什么好处呢?
答:原因在于神经网络学习过程本质就是为了学习数据分布,一旦训练数据与测试数据的分布不同,那么网络的泛化能力也大大降低;另外一方面,一旦每批训练数据的分布各不相同(batch 梯度下降),那么网络就要在每次迭代都去学习适应不同的分布,这样将会大大降低网络的训练速度,这也正是为什么我们需要对数据都要做一个归一化预处理的原因。
5) 为什么L1正则化可以产生稀疏模型(L1是怎么让系数等于零的)?
答:假设有如下带L1正则化的损失函数:
J=J0+α∑w|w|(1)
其中J0是原始的损失函数,加号后面的一项是L1正则化项,α是正则化系数。注意到L1正则化是权值的绝对值之和,J是带有绝对值符号的函数,因此J是不完全可微的。令L=α∑w|w|,则J=J0+L,此时我们的任务变成在L约束下求出J0取最小值的解。考虑二维的情况,即只有两个权值w1和w2,此时L=|w1|+|w2|对于梯度下降法,求解J0的过程可以画出等值线,同时L1正则化的函数L也可以在w1w2的二维平面上画出来。
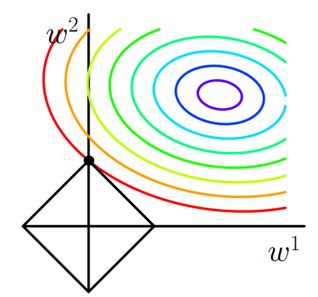
图中等值线是J0的等值线,黑色方形是L函数的图形。在图中,当J0等值线与L图形首次相交的地方就是最优解。上图中J0与L在L的一个顶点处相交,这个顶点就是最优解。注意到这个顶点的值是(w1,w2)=(0,w)。可以直观想象,因为L函数有很多『突出的角』(二维情况下四个,多维情况下更多),J0与这些角接触的机率会远大于与L其它部位接触的机率,而在这些角上,会有很多权值等于0,这就是为什么L1正则化可以产生稀疏模型,进而可以用于特征选择。
5) L2正则化项可以使权重衰减,为什么权重衰减可以防止overfitting?
答:拟合过程中通常都倾向于让权值尽可能小,最后构造一个所有参数都比较小的模型。因为一般认为参数值小的模型比较简单,表示网络的复杂度更低,能适应不同的数据集,也在一定程度上避免了过拟合现象。可以设想一下对于一个线性回归方程,若参数很大,那么只要数据偏移一点点,就会对结果造成很大的影响;但如果参数足够小,数据偏移得多一点也不会对结果造成什么影响,即『抗扰动能力强』。
过拟合的时候,拟合函数的系数往往非常大,为什么?如下图所示,过拟合,就是拟合函数需要顾忌每一个点,最终形成的拟合函数波动很大。在某些很小的区间里,函数值的变化很剧烈。这就意味着函数在某些小区间里的导数值(绝对值)非常大,由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大。
而正则化是通过约束参数的范数使其不要太大,所以可以在一定程度上减少过拟合情况。
L1 惩罚项(权重绝对值)或 L2 惩罚项(权重平方)。
6) Dropout,它为什么有助于防止过拟合呢?
答:运用了dropout的训练过程,在训练开始时,随机地“删除”一半的隐层单元,视它们为不存在。相当于训练了很多个只有半数隐层单元的神经网络(后面简称为“半数网络”),每一个这样的半数网络,都可以给出一个分类结果,这些结果有的是正确的,有的是错误的。随着训练的进行,大部分半数网络都可以给出正确的分类结果,那么少数的错误分类结果就不会对最终结果造成大的影响
7) 对所有优化问题来说, 有没有可能找到比現在已知算法更好的算法?
答:没有免费的午餐定理:
对于训练样本,不同的算法A/B在不同的测试样本中有不同的表现,这表示:对于一个学习算法A,若它在某些问题上比学习算法 B更好,则必然存在一些问题,在那里B比A好。也就是说:对于所有问题,无论学习算法A多聪明,学习算法 B多笨拙,它们的期望性能相同。
但是,没有免费午餐定力假设所有问题出现几率相同,实际应用中,不同的场景,会有不同的问题分布,所以,在优化算法时,针对具体问题进行分析,是算法优化的核心所在。
8) CNN有什么优缺点?
答:优点:共享卷积核、减少了网络自由参数的个数,对高维数据处理无压力;无需手动选取特征,训练好权重,即得特征。降低神经网络的复杂性。这种网络结构在有监督的方式下学习到了一些良好的性能:对平移、比例缩放、倾斜或其他形式的变形具有高度不变性。
缺点:需要调参,需要大量样本;
CNN的主要演进方向如下:
1、网络结构加深
2、加强卷积功能
3、从分类到检测
4、新增功能模块
9) 梯度爆炸?
答:梯度爆炸就是由于初始化权值过大,前面层会比后面层变化的更快,就会导致权值越来越大,梯度爆炸的现象就发生了。
10) 如何解决梯度消失或者梯度爆炸呢?
答:用ReLU激活函数来替代sigmoid函数。重新设计层数更少的网络。
11) CNN问题?
答:
(1) 思想
改变全连接为局部连接,这是由于图片的特殊性造成的(图像的一部分的统计特性与其他部分是一样的),通过局部连接和参数共享大范围的减少参数值。可以通过使用多个filter来提取图片的不同特征(多卷积核)。
(2) filter尺寸的选择
通常尺寸多为奇数(1,3,5,7)
(3) 输出尺寸计算公式
输出尺寸=(N - F +padding*2)/stride + 1
步长可以自由选择通过补零的方式来实现连接。
(4) pooling池化的作用
虽然通过.卷积的方式可以大范围的减少输出尺寸(特征数),但是依然很难计算而且很容易过拟合,所以依然利用图片的静态特性通过池化的方式进一步减少尺寸。
(5) 常用的几个模型,这个最好能记住模型大致的尺寸参数。
- LeNet5: 第一个CNN
- AlexNet: 引入了ReLU和dropout,引入数据增强、池化相互之间有覆盖,三个卷积一个最大池化+三个全连接层
- VGGNet: 采用1*1和3*3的卷积核以及2*2的最大池化使得层数变得更深。常用VGGNet-16和VGGNet19
- Google Inception Net 我称为盗梦空间网络: 这个在控制了计算量和参数量的同时,获得了比较好的分类性能,和上面相比有几个大的改进:
a. 去除了最后的全连接层,而是用一个全局的平均池化来取代它;
b. 引入Inception Module,这是一个4个分支结合的结构。所有的分支都用到了1*1的卷积,这是因为1*1性价比很高,可以用很少的参数达到非线性和特征变换。
c. Inception V2第二版将所有的5*5变成2个3*3,而且提出来著名的Batch Normalization;
d. Inception V3第三版把较大的二维卷积拆成了两个较小的一维卷积,加速运算、减少过拟合,同时还更改了Inception Module的结构。 - 微软ResNet残差神经网络(Residual Neural Network):
a. 引入高速公路结构,可以让神经网络变得非常深
b. ResNet第二个版本将ReLU激活函数变成y=x的线性函数
12) 什么是有监督学习和无监督学习?
答:监督学习(supervised learning):通过已有的训练样本(即已知数据以及其对应的输出)来训练,从而得到一个最优模型,再利用这个模型将所有新的数据样本映射为相应的输出结果,对输出结果进行简单的判断从而实现分类的目的,那么这个最优模型也就具有了对未知数据进行分类的能力。
监督学习中只要输入样本集,机器就可以从中推演出制定目标变量的可能结果.如协同过滤推荐算法,通过对训练集进行监督学习,并对测试集进行预测,从而达到预测的目的.
无监督学习(unsupervised learning):我们事先没有任何训练数据样本,需要直接对数据进行建模。
13) 激活函数的作用?
答:激活函数的主要作用是提供网络的非线性建模能力。如果没有激活函数,那么该网络仅能够表达线性映射,此时即便有再多的隐藏层,其整个网络跟单层神经网络也是等价的。因此也可以认为,只有加入了激活函数之后,深度神经网络才具备了分层的非线性映射学习能力。
14) 梯度下降的方式? 如何选择?
答:批量梯度下降法(Batch Gradient Descent,简称BGD)是梯度下降法最原始的形式,它的具体思路是在更新每一参数时都使用所有的样本来进行更新,最终求解的是全局的最优解。
优点:全局最优解;易于并行实现;当损失函数达到最小值以后,能够保证此时计算出的梯度为0,换句话说,就是能够收敛.因此,使用BGD时不需要逐渐减小学习速率。
缺点:当样本数目很多时,训练过程会很慢。
随机梯度下降法(stochastic gradient descent,简称SGD):它的具体思路是在更新每一参数时都使用一个样本来进行更新,如果样本量很大的情况(例如几十万),那么可能只用其中几万条或者几千条的样本,就已经将theta迭代到最优解了。虽然不是每次迭代得到的损失函数都向着全局最优方向, 但是大的整体的方向是向全局最优解的,最终的结果往往是在全局最优解附近。
优点:训练速度快;对于很大的数据集,也能够以较快的速度收敛。
缺点:准确度下降,并不是全局最优;抽取样本,使得到的梯度有误差,因此学习速率需要逐渐减小,否则模型无法收敛;误差使梯度含有比较大的噪声,不能很好的反映真实梯度。
小批量梯度下降法(Mini-batch Gradient Descent,简称MBGD):它的具体思路是在更新每一参数时都使用一部分样本来进行更新。克服BGD和SGD的缺点,又兼顾了两者的优点。
如果样本量比较小,采用批量梯度下降算法。如果样本太大,或者在线算法,使用随机梯度下降算法。在实际的一般情况下,采用小批量梯度下降算法。
15) 深度学习优化函数momentum 动量的作用和原理?
答:momentum是用来修改检索方向加快收敛速度的一种简单方法,一般的通过加入之前的梯度来修改更新梯度步长

16) 学习率的调整策略?
答:基于经验的手动调整。 通过尝试不同的固定学习率,如0.1, 0.01, 0.001等,观察迭代次数和loss的变化关系,找到loss下降最快关系对应的学习率。一般常用的学习率有0.00001,0.0001,0.001,0.003,0.01,0.03,0.1,0.3,1,3,10
根据数据集的大小来选择合适的学习率。当使用平方误差和作为成本函数时,随着数据量的增多,学习率应该被设置为相应更小的值(从梯度下降算法的原理可以分析得出)。另一种方法就是,选择不受数据集大小影响的成本函数-均值平方差函数。
在不同的迭代中选择不同的学习率。即,在最初的迭代中,学习率可以大一些,快接近最优解时,学习率小一些。那么如何知道每一步迭代中离最优值有多远,是否接近最优解呢?在每次迭代后,使用估计的模型的参数来查看误差函数的值,如果相对于上一次迭代,错误率减少了,就可以增大学习率,以5%的幅度;如果相对于上一次迭代,错误率增大了,那么应该重新设置上一轮迭代的值,并且减少学习率到之前的50%。因此,这是一种学习率自适应调节的方法。
17) 批尺寸选择原则?
答:batch size也就是块大小,代表着每一个mini batch中有多少个样本。 一般设置为2的n次方。 例如64,128,512,1024. 一般不会超过这个范围。不能太大,因为太大了会无限接近full batch的行为,速度会慢。 也不能太小,太小了以后可能算法永远不会收敛。
如果数据集比较小,完全可以采用全数据集 ( Full Batch Learning )的形式。由全数据集确定的方向能够更好地代表样本总体,从而更准确地朝向极值所在的方向。
在合理范围内,增大 Batch_Size 有何好处?
- 内存利用率提高了,大矩阵乘法的并行化效率提高。
- 跑完一次 epoch(全数据集)所需的迭代次数减少,对于相同数据量的处理速度进一步加快。
- 在一定范围内,一般来说 Batch_Size 越大,其确定的下降方向越准,引起训练震荡越小。
盲目增大 Batch_Size 有何坏处?
- 内存利用率提高了,但是内存容量可能撑不住了。
- 跑完一次 epoch(全数据集)所需的迭代次数减少,要想达到相同的精度,其所花费的时间大大增加了,从而对参数的修正也就显得更加缓慢。
- Batch_Size 增大到一定程度,其确定的下降方向已经基本不再变化。
每次只训练一个样本,即 Batch_Size = 1会怎样?
每次修正方向以各自样本的梯度方向修正,横冲直撞各自为政,难以达到收敛。
18) 周期(Epochs)选择原则?
答:选择更多的周期将显示出更高的网络准确性,然而,网络融合也需要更长的时间。另外,必须注意,如果周期数太高,网络可能会过度拟合。
19) 前向传播和后向传播
答:
前向传播为利用网络模型,通过输入计算输出的结构,网络模型(net)整合了网络中的每一层(layer),并逐步计算得到最终的loss,即输出结果,这个过程也称之为自底向上的过程。
反向传播和前向传播对应,传播方向相反,它是自顶向下的过程,网络模型利用梯度逐步计算每一层(layer)的梯度,得到整个网络模型的梯度,从而实现模型参数的更新和优化。
后向传播算法(BackPropagation)是在求解损失函数L对参数w求导时候用到的方法,目的是通过链式法则对参数进行一层一层的求导。简单的理解,就是复合函数的链式求导法则。
如有问题,欢迎指正!内容持续更新中~