Python字符编码
1 字符编码介绍
字符编码就是字符的二进制表示,这里的字符是广义的,包括英文、中文、日文等,ASCII、GB2312、UTF-8都是编码。
编码方式:
- GB2312:7k个简体汉字,每个文字或符号占两个字节(上限是65536种组合)。
- GBK:20k个文字(包含繁体),双字节,向下兼容GB2312。CP936可以看作是GBK的别名。
- GB18030:27k个文字(包含少数民族文字),1、2、4字节变长编码,1字节兼容ASCII,2字节与GBK基本兼容。2000年取代GBK成为国标,现在PC平台都支持GB18030,手机等嵌入式产品一般只支持GB2312。
- unicode(Universal Multiple-Octet Coded Character Set,简称UCS,俗称unicode):把所有语言都都纳入到一套编码中,常用字符的编码是2字节(生僻字符为4字节)。Unicode对ASCII是兼容的,只要将1字节的ASCII编码前面补0到2字节就是对应的Unicode编码。
- UTF(UCS Transfer Format):可以看作是unicode的实现。unicode只是规定了字符对应的编码值,但是编码值怎么存储,比如变长还是定长,多字节大小端问题等。
- UTF-8:UTF变长编码,为了解决Unicode兼容ASCII导致浪费1字节的全0,英文在UTF-8中是1字节,中文通常是3字节,生僻字符为4-6字节。记事本程序显示时使用了Unicode编码,保存使用了UTF-8编码。
- UTF-16:UTF-16需要BOM(Byte Order Mark)用于区分LE和BE,UTF-8的BOM是可选的。
对于x86平台的python3,unicode和小端不带BOM的utf-16le相同。

# -*- coding: utf-8 -*-
import sys
def get_encoding_bytes(c, encoding):
print('c=', c, ', encoding=', encoding, ', len(c)=', len(c), sep='')
if encoding != 'unicode':
for i in range(len(c)):
print('%#x' % c[i], end=' ')
else:
for b in c:
print(hex(ord(b)), end='')
print('\n', end='\n')
if __name__ == '__main__':
u = u'中'
get_encoding_bytes(u, 'unicode')
get_encoding_bytes(u.encode('utf-8'), 'utf-8')
get_encoding_bytes(u.encode('utf-8-sig'), 'utf-8-sig')
get_encoding_bytes(u.encode('utf-16'), 'utf-16')
get_encoding_bytes(u.encode('utf-16le'), 'utf-16le')
get_encoding_bytes(u.encode('utf-16be'), 'utf-16be')2 py文件编码声明
2.1 格式
下面三种都可以,必须在文件第一行或者第二行。utf-8和utf8在python2和3中都可以。
# -*- coding: utf-8 -*-
# coding: utf-8
# coding=utf-82.2 python2
- 文件编码声明指定py文件中所有字符串的默认编码方式,如果显式指定了字符串的编码方式,则使用指定的编码。
- 如果py文件中出现了中文字符,不论是定义字符串还是在注释中,python默认按照ASCII解析脚本,如果遇到了中文要么声明了文件编码,要么字符串前加u使用unicode。否则会出现下面的语法错误:
SyntaxError: Non-ASCII character '\xe4' in file encoding.py on line 10, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details
例1:’中’为utf-8,u’中’为unicode。
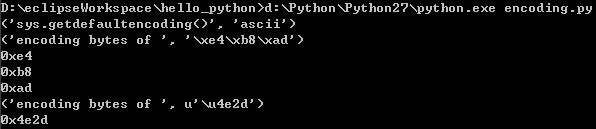
# -*- coding: utf-8 -*--
import sys
def get_encoding_bytes(c):
print('encoding bytes of ', c)
for b in c:
print(hex(ord(b)))
if __name__ == '__main__':
print('sys.getdefaultencoding()', sys.getdefaultencoding())
get_encoding_bytes('中')
get_encoding_bytes(u'中')例2:如果coding改为gbk,会出现语法错误:
SyntaxError: 'gbk' codec can't decode bytes in position 12-13: illegal multibyte sequence
因为py文件是使用UTF-8编码存储在磁盘上的,使用notepad或者sublime可以看中文使用了UTF-8编码。python读取文件时使用coding指定的编码解析UTF-8就会出现无法解析的字节问题。
![]()

2.3 python3
所有的字符串都是unicode编码,因此py文件中有中文时不加文件编码声明不会出现python2的错误。即使声明了文件编码,字符串也是unicode。

3 编码转换
3.1 python2
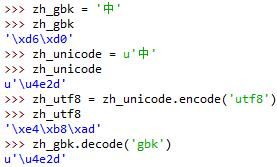
windows的IDLE中定义的中文字符串默认是gbk编码
gbk编码和utf8不能直接转换,必须通过unicode转换:
* unicode = gbk.decode(‘gbk’):把非unicode编码转换为unicode编码
* utf8 = unicode.encode(‘utf8’):把unicode编码转转为非unicode
3.2 python3
所有的字符串都是unicode编码的。
python3中增加了bytes这个类,encode返回值是bytes类型的。python2中没有bytes,encode返回的还是str。
* str.encode(‘code’):把字符串以参数指定的编码(例如’ascii’、’UTF-8’),把字符串保存到磁盘或者通过网络传输时需要这样做。
* bytes.decode(‘code’):把bytes根据参数指定的解码进行解码。从网络接收的html是bytes类型,需要根据解码。

4 其他
4.1 len(包含中文字符串)
如果中文字符串是unicode,那么返回的是中文字符的个数。
如果是python2中的非unicode编码,或者python3中的bytes,返回的是字节数。
4.2 一个包含中文的文件,但是中文有不同编码处理方式
背景:线上日志里面的中文包含GB18030和UTF-8两种中文编码。
python2:打开文件时不会尝试进行decode,返回的file.read和file.readline可以看作是byte数组,中文部分的数据是对应的编码方式的字节。对整个数组用一种编码decode转换成unicode抛出异常的情况和python3类似。
python3:用r打开时会进行一次解码,win7上是用gbk解码,这是为了使得read返回的字符串是unicode。此时由于文件中存在不是gbk格式的编码,因此打开文件时可能会抛出UnicodeDecodeError异常。
例:使用rb打开然后手动解码来模拟用r打开时的情况。
图1:6字节数组是中文“中中”的utf-8编码,使用gbk解码抛出异常。e4b8是gbk编码的涓,但是ade4不是合法的gbk编码,所以就抛出异常了。
图2:18字节数组是中文“演唱会哈尔滨”的utf-8编码,使用gbk去解码没有抛出异常,恰好每两个字节都是合法的gbk编码。


用rb打开,不会自动对中文部分解码,读入的字符串可以当作单字节字符数组处理。因为GBK、UTF8等中文编码都兼容ASCII,所以也不用担心表示汉字的某个编码字节中会有和ASCII重复的。
对于读入的字符数组,不能直接用decode解码,原因和用r打开一样,但是可以分别解码为正确结果。
例:文件二进制内容为(从低地址到高地址:0xd6 0xd0 0x0a 0xe4 0xb8 0xad,x86平台)。

f = open('test.txt', 'rb')
l = f.read()
print('len(l)', len(l))
print('l', l)
try:
print("l.decode('utf-8')", l.decode('utf-8'))
except Exception as e:
print("l.decode('utf-8')", e)
try:
print("l.decode('gbk')", l.decode('gbk'))
except Exception as e:
print("l.decode('gbk')", e)
print("l[:2].decode('gbk')", l[:2].decode('gbk'))
print("l[3:].decode('utf-8')", l[3:].decode('utf-8'))参考
- ASCII、Unicode、GBK和UTF-8字符编码的区别联系
- u’\ufeff’ in Python string
- PEP 263 – Defining Python Source Code Encodings
- python编码(七)