第93讲:Spark Streaming updateStateByKey案例实战和内幕源码
有兴趣想学习国内整套Spark+Spark Streaming+Machine learning最顶级课程的,可加我qq 471186150。共享视频,性价比超高!
本节课程主要分二个部分:
一、Spark Streaming updateStateByKey案例实战
二、Spark Streaming updateStateByKey源码解密
第一部分:
updateStateByKey它的主要功能是随着时间的流逝,在Spark Streaming中可以为每一个key可以通过CheckPoint来维护一份state状态,通过更新函数对该key的状态不断更新;在更新的时候,对每一个新批次的数据(batch)而言,Spark Streaming通过使用updateStateByKey为已经存在的key进行state的状态更新(对每个新出现的key,会同样执行state的更新函数操作);但是如果通过更新函数对state更新后返回none的话,此时刻key对应的state状态会被删除掉,需要特别说明的是state可以是任意类型的数据结构,这就为我们的计算带来无限的想象空间;
非常重要:
如果要不断的更新每个key的state,就一定会涉及到状态的保存和容错,这个时候就需要开启checkpoint机制和功能,需要说明的是checkpoint可以保存一切可以存储在文件系统上的内容,例如:程序未处理的但已经拥有状态的数据。
虽然说DStream是流式处理,但是由于我们保存了前面处理的结果,所以我可以不断在历史的基础上进行次数的更新。
补充说明:
关于流式处理对历史状态进行保存和更新具有重大实用意义,例如进行广告点击全面的动态评估(动态评估就是既有历史的数据又有现在的数据)(投放广告和运营广告效果评估的价值意义,热点随时追踪、热力图)
案例实战源码:
1.编写源码:
ackage org.apache.spark.examples.streaming;
import java.util.Arrays;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import com.google.common.base.Optional;
import scala.Tuple2;
public class UpdateStateByKeyDemo {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local[2]").
setAppName("UpdateStateByKeyDemo");
JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(5));
//报错解决办法做checkpoint,开启checkpoint机制,把checkpoint中的数据放在这里设置的目录中,这里必须做checkpoint
//checkpoint如果挂了,那就挂了。所以生产环境下一般放在HDFS中,因为checkpoint有三份副本,一份挂了,还有另外2份容错。每次都要checkpoint,是会耗性能的,后面可以改进
jsc.checkpoint("/usr/local/tmp/checkpoint");
/*
* 第三步:创建Spark Streaming输入数据来源input Stream:
* 1,数据输入来源可以基于File、HDFS、Flume、Kafka、Socket等
* 2, 在这里我们指定数据来源于网络Socket端口,Spark Streaming连接上该端口并在运行的时候一直监听该端口
* 的数据(当然该端口服务首先必须存在),并且在后续会根据业务需要不断的有数据产生(当然对于Spark Streaming
* 应用程序的运行而言,有无数据其处理流程都是一样的);
* 3,如果经常在每间隔5秒钟没有数据的话不断的启动空的Job其实是会造成调度资源的浪费,因为并没有数据需要发生计算,所以
* 实例的企业级生成环境的代码在具体提交Job前会判断是否有数据,如果没有的话就不再提交Job;
*/
JavaReceiverInputDStream lines = jsc.socketTextStream("Master", 9999);
JavaDStream
@Override
public Iterable
return Arrays.asList(line.split(" "));
}
});
JavaPairDStream
@Override
public Tuple2
return new Tuple2
}
});
/*
*第4.3步:在这里是通过updateStateByKey来以Batch Interval为单位来对历史状态进行更新,
* 这是功能上的一个非常大的改进,否则的话需要完成同样的目的,就可能需要把数据保存在Redis、
* Tagyon或者HDFS或者HBase或者数据库中来不断的完成同样一个key的State更新,如果你对性能有极为苛刻的要求,
* 且数据量特别大的话,可以考虑把数据放在分布式的Redis或者Tachyon内存文件系统中,如精准的秒杀系统;
* 当然从Spark1.6.x开始可以尝试使用mapWithState,Spark2.X后mapWithState应该非常稳定了。这样就去除了cogroup的弊端
*/
//如果发现不识别报错,一般是导包导错了,这里就导错了Optional的包,搞了好久
JavaPairDStream
@Override
public Optional
throws Exception {
//第一个参数就是key传进来的数据,第二个参数是曾经已有的数据
Integer updatedValue = 0 ;//如果第一次,state没有,updatedValue为0,如果有,就获取
if(state.isPresent()){
updatedValue = state.get();
}
//遍历batch传进来的数据可以一直加,随着时间的流式会不断去累加相同key的value的结果。
for(Integer value: values){
updatedValue += value;
}
return Optional.of(updatedValue);//返回更新的值
}
});
/*
*此处的print并不会直接出发Job的执行,因为现在的一切都是在Spark Streaming框架的控制之下的,对于Spark Streaming
*而言具体是否触发真正的Job运行是基于设置的Duration时间间隔的
*诸位一定要注意的是Spark Streaming应用程序要想执行具体的Job,对Dtream就必须有output Stream操作,
*output Stream有很多类型的函数触发,类print、saveAsTextFile、saveAsHadoopFiles等,最为重要的一个
*方法是foraeachRDD,因为Spark Streaming处理的结果一般都会放在Redis、DB、DashBoard等上面,foreachRDD
*主要就是用用来完成这些功能的,而且可以随意的自定义具体数据到底放在哪里!!!
*/
wordsCount.print();
/*
* Spark Streaming执行引擎也就是Driver开始运行,Driver启动的时候是位于一条新的线程中的,当然其内部有消息循环体,用于
* 接受应用程序本身或者Executor中的消息;
*/
jsc.start();
jsc.awaitTermination();
jsc.close();
}
2.创建checkpoint目录:
jsc.checkpoint("/usr/local/tmp/checkpoint");
3. 在eclipse中通过run 方法启动main函数:
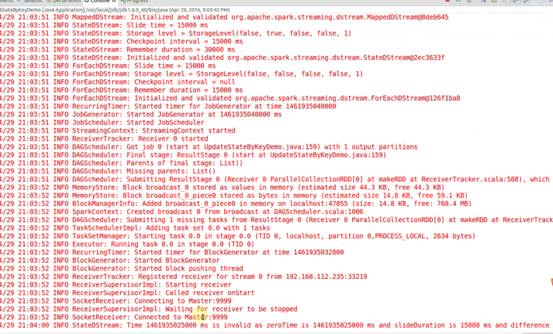
4.启动hdfs服务并发送nc -lk 9999请求:
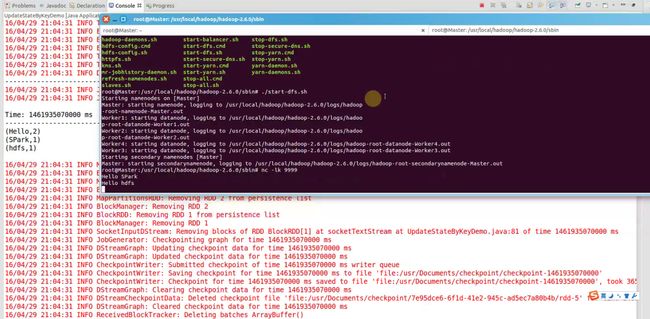
继续输入Hello hdfs
结果就是累加后的结果,
(Hello,3)
(SPark,1)
(hdfs,2)
再次输入Hello SPark,下一个batch就会继续累加,(Hello,3)(SPark,2) (hdfs,2)的结果输出
5.查看checkpoint目录输出:因为是二进制

源码解析:
1.PairDStreamFunctions类:
/**
* Return a new "state" DStream where the state for each key is updated by applying
* the given function on the previous state of the key and the new values of each key.
* Hash partitioning is used to generate the RDDs with Spark's default number of partitions.
* @param updateFunc State update function. If `this` function returns None, then
* corresponding state key-value pair will be eliminated.
* @tparam S State type
*/
def updateStateByKey[S: ClassTag](
updateFunc: (Seq[V], Option[S]) => Option[S]
): DStream[(K, S)] = ssc.withScope {
updateStateByKey(updateFunc, defaultPartitioner())
}
/**
* Return a new "state" DStream where the state for each key is updated by applying
* the given function on the previous state of the key and the new values of the key.
* org.apache.spark.Partitioner is used to control the partitioning of each RDD.
* @param updateFunc State update function. If `this` function returns None, then
* corresponding state key-value pair will be eliminated.
* @param partitioner Partitioner for controlling the partitioning of each RDD in the new
* DStream.
* @tparam S State type
*/
def updateStateByKey[S: ClassTag](
updateFunc: (Seq[V], Option[S]) => Option[S],
partitioner: Partitioner
): DStream[(K, S)] = ssc.withScope {
val cleanedUpdateF = sparkContext.clean(updateFunc)
val newUpdateFunc = (iterator: Iterator[(K, Seq[V], Option[S])]) => {
iterator.flatMap(t => cleanedUpdateF(t._2, t._3).map(s => (t._1, s)))
}
updateStateByKey(newUpdateFunc, partitioner, true)
}
/**
* Return a new "state" DStream where the state for each key is updated by applying
* the given function on the previous state of the key and the new values of each key.
* org.apache.spark.Partitioner is used to control the partitioning of each RDD.
* @param updateFunc State update function. Note, that this function may generate a different
* tuple with a different key than the input key. Therefore keys may be removed
* or added in this way. It is up to the developer to decide whether to
* remember the partitioner despite the key being changed.
* @param partitioner Partitioner for controlling the partitioning of each RDD in the new
* DStream
* @param rememberPartitioner Whether to remember the paritioner object in the generated RDDs.
* @tparam S State type
*/
def updateStateByKey[S: ClassTag](
updateFunc: (Iterator[(K, Seq[V], Option[S])]) => Iterator[(K, S)],
partitioner: Partitioner,
rememberPartitioner: Boolean
): DStream[(K, S)] = ssc.withScope {
new StateDStream(self, ssc.sc.clean(updateFunc), partitioner, rememberPartitioner, None)
}
override def compute(validTime: Time): Option[RDD[(K, S)]] = {
// Try to get the previous state RDD
getOrCompute(validTime - slideDuration) match {
case Some(prevStateRDD) => { // If previous state RDD exists
// Try to get the parent RDD
parent.getOrCompute(validTime) match {
case Some(parentRDD) => { // If parent RDD exists, then compute as usual
computeUsingPreviousRDD (parentRDD, prevStateRDD)
}
case None => { // If parent RDD does not exist
// Re-apply the update function to the old state RDD
val updateFuncLocal = updateFunc
val finalFunc = (iterator: Iterator[(K, S)]) => {
val i = iterator.map(t => (t._1, Seq[V](), Option(t._2)))
updateFuncLocal(i)
}
val stateRDD = prevStateRDD.mapPartitions(finalFunc, preservePartitioning)
Some(stateRDD)
}
}
}
case None => { // If previous session RDD does not exist (first input data)
// Try to get the parent RDD
parent.getOrCompute(validTime) match {
case Some(parentRDD) => { // If parent RDD exists, then compute as usual
initialRDD match {
case None => {
// Define the function for the mapPartition operation on grouped RDD;
// first map the grouped tuple to tuples of required type,
// and then apply the update function
val updateFuncLocal = updateFunc
val finalFunc = (iterator : Iterator[(K, Iterable[V])]) => {
updateFuncLocal (iterator.map (tuple => (tuple._1, tuple._2.toSeq, None)))
}
val groupedRDD = parentRDD.groupByKey (partitioner)
val sessionRDD = groupedRDD.mapPartitions (finalFunc, preservePartitioning)
// logDebug("Generating state RDD for time " + validTime + " (first)")
Some (sessionRDD)
}
case Some (initialStateRDD) => {
computeUsingPreviousRDD(parentRDD, initialStateRDD)
}
}
}
case None => { // If parent RDD does not exist, then nothing to do!
// logDebug("Not generating state RDD (no previous state, no parent)")
None
}
}
}
}