1. Spark Stack
spark的栈
spark sql:相当于hive,将sql解析成rdd的transformation
spark streaming:流式处理,相当于storm
Mllib:机械学习,数学知识要求很高
GrathX:图计算
ApacheSpark:spark的核心代码

2. Spark Streaming概览

由消息队列向spark streaming生产数据,在spark streaming上执行,最后存储到数据底层,或者展示在控制台
3. 原理:将输入的数据切分成一个个批次
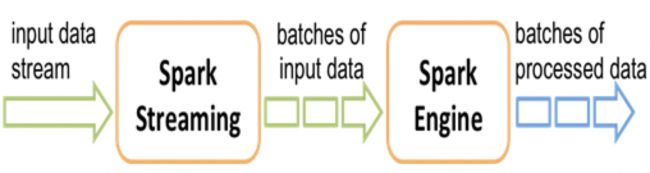
spark steaming不是严格的实时计算,他是分批次的提交任务,任务间隔在毫秒值范围内。
4. Dstreams离散流
Spark Streaming provides a high-level abstraction called discretized stream or DStream, which represents a continuous stream of data. DStreams can be created either from input data streams from sources such as Kafka, Flume, and Kinesis, or by applying high-level operations on other DStreams. Internally, a DStream is represented as a sequence of RDDs
5. 演示helloword
5.1. 创建scala项目,并导包
5.2. 创建scala程序
package org.apache.wangsf
import org.apache.spark.SparkConf
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.Seconds
object TCPWordCount {
def main(args: Array[String]) {
//setMaster("local[2]")本地执行2个线程,一个用来接收消息,一个用来计算
val conf = new SparkConf().setMaster("local[2]").setAppName("TCPWordCount")
//创建spark的streaming,传入间隔多长时间处理一次,间隔在5秒左右,否则打印控制台信息会被冲掉
val scc =new StreamingContext(conf,Seconds(5))
//读取数据的地址:从某个ip和端口收集数据
val lines = scc.socketTextStream("192.168.56.157", 8888)
//进行rdd处理
val results = lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
//将结果打印控制台
results.print()
//启动spark streaming
scc.start()
//等待终止
scc.awaitTermination()
}
}
5.3. 在linux对应的机器上发送模拟命令
启动模拟窗口
nc -lk 8888
在模拟窗口上输入数据
hello world
6. 更新状态
在上面的计算过程中,数据时批次处理的,但是不是历史数据的求和,我们需要用到一个函数如下:

6.1. 更新数据的流式处理
import org.apache.spark.SparkConf
import org.apache.spark.streaming.Seconds
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.HashPartitioner
import org.apache.log4j.Logger
import org.apache.log4j.Level
import org.slf4j.LoggerFactory
object StateFullWordCount {
/**
* String:某个单词
* Seq:[1,1,1,1,1,1],当前批次出现的次数的序列
* Option:历史的结果的sum
*/
val updateFunction = (iter: Iterator[(String,Seq[Int],Option[Int])]) => {
//将iter中的历史次数和现有的数据叠加,然后将单词和出现的最后次数输出
//iter.flatMap(t=>Some(t._2.sum + t._3.getOrElse(0)).map(x=>(t._1,x)))
iter.flatMap{case(x,y,z)=>Some(y.sum+z.getOrElse(0)).map(v =>(x,v))}
}
def main(args: Array[String]) {
//设置日志级别
Logger.getRootLogger.setLevel(Level.WARN)
//创建
val conf = new SparkConf().setMaster("local[2]").setAppName("StateFullWordCount")
val ssc = new StreamingContext(conf,Seconds(5))
//回滚点设置在本地
//ssc.checkpoint("./")
//将回滚点写到hdfs
ssc.checkpoint("hdfs://master1:9000/ceshi")
val lines = ssc.socketTextStream("192.168.56.157", 8888)
/**
* updateStateByKey()更新数据
* 1、更新数据的具体实现函数
* 2、分区信息
* 3、boolean值
*/
val results = lines.flatMap(_.split(" ")).map((_,1)).updateStateByKey(updateFunction,new HashPartitioner(ssc.sparkContext.defaultParallelism),true)
results.print()
ssc.start()
ssc.awaitTermination()
}
}
6.2. 线上模式
打包
export
上传
将jar包上传到spark的机器
提交
spark-submit --class org.apache.wangsf.StateFullWordCount statefullwordcount.jar
测试
启动模拟窗口
nc -lk 8888
在模拟窗口上输入数据
hello world
7. 从flume拉取数据
7.1. 代码
import org.apache.spark.HashPartitioner
import org.apache.spark.SparkConf
import org.apache.spark.streaming.Seconds
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.flume.FlumeUtils
import java.net.InetSocketAddress
import org.apache.spark.storage.StorageLevel
object FlumeWordCount {
val updateFunction = (iter: Iterator[(String,Seq[Int],Option[Int])]) => {
iter.flatMap{case(x,y,z)=>Some(y.sum+z.getOrElse(0)).map(v =>(x,v))}
}
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local[2]").setAppName("FlumeWordCount")
val ssc = new StreamingContext(conf,Seconds(5))
ssc.checkpoint("hdfs://master1:9000/ceshi")
//设置flume的多台地址
val address = Seq(new InetSocketAddress("192.168.56.157", 9999),new InetSocketAddress("192.168.56.156", 9999))
//从flume中拉取数据
val flumeStream = FlumeUtils.createPollingStream(ssc,address,StorageLevel.MEMORY_AND_DISK)
//将flume数据中body部分的array转换为string,进行rdd
val results = flumeStream.flatMap(x => new String(x.event.getBody().array()).split(" ")).map((_,1)).updateStateByKey(updateFunction,new HashPartitioner(ssc.sparkContext.defaultParallelism),true)
results.print()
ssc.start()
ssc.awaitTermination()
}
}
7.2. flume的agent
分为主动拉取和被动接收数据,我们经常用主动拉取的方式
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /var/log/flume
a1.sources.r1.fileHeader = true
# Describe the sink
a1.sinks.k1.type = org.apache.spark.streaming.flume.sink.SparkSink
a1.sinks.k1.hostname = 192.168.45.85
a1.sinks.k1.port = 9999
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
7.3. 上传依赖包
将依赖包上传到flume的lib下
7.4. 创建文件夹
在flume的根目录下创建test文件夹
7.5. 启动
启动flume
flume-ng agent -n a1 -c /home/hadoop/flume/conf/ -f /home/hadoop/flume /conf/flume-poll.conf -Dflume.root.logger=WARN,console
再启动spark-streaming应用程序
7.6. 测试
向flume监听的文件夹下方文件即可
8. spark从kafka拉取数据
8.1. 代码
import java.net.InetSocketAddress
import org.apache.spark.HashPartitioner
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.Seconds
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.flume.FlumeUtils
import org.apache.spark.streaming.kafka.KafkaUtils
object KafkaWordCount {
val updateFunction = (iter: Iterator[(String, Seq[Int], Option[Int])]) => {
iter.flatMap { case (x, y, z) => Some(y.sum + z.getOrElse(0)).map(v => (x, v)) }
}
def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local[2]").setAppName("FlumeWordCount")
val ssc = new StreamingContext(conf, Seconds(5))
ssc.checkpoint("hdfs://master1:9000/ceshi")
val Array(zkQuorum, groupId, topics, numThreads) = args
val topicMap = topics.split(",").map((_,numThreads.toInt)).toMap
val lines = KafkaUtils.createStream(ssc, zkQuorum, groupId, topicMap).map(_._2)
val results = lines.flatMap(_.split(" ")).map((_, 1)).updateStateByKey(updateFunction, new HashPartitioner(ssc.sparkContext.defaultParallelism), true)
results.print()
ssc.start()
ssc.awaitTermination()
}
}
8.2. 其他步骤待续
结合kafka
首先启动zk
bin/kafka-server-start.sh config/server.properties
创建topic
bin/kafka-topics.sh --create --zookeeper 192.168.80.10:2181 --replication-factor 1 --partitions 1 --topic wordcount
查看主题
bin/kafka-topics.sh --list --zookeeper 192.168.80.10:2181
启动一个生产者发送消息
bin/kafka-console-producer.sh --broker-list 192.168.80.10:9092 --topic wordcount
启动spark-streaming应用程序
bin/spark-submit --class cn.itcast.spark.streaming.KafkaWordCount /root/streaming-1.0.jar 192.168.80.10:2181 group1 wordcount 1
9. Window Operations
计算一个时间段的数据,比如一分钟之内的wordcount

batch interval
window length
sliding interval
window length and sliding interval must be multiples of the batch interval of the source DStream