数据分析 day06(三)
美国总统大选政治捐献金分析
一. 相关信息
首先将数据文件放入相应的文件夹下,
创建一个ipnb文件,命名为美国总统大选政治捐献金分析

导入模块
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from pandas import Series,DataFrame
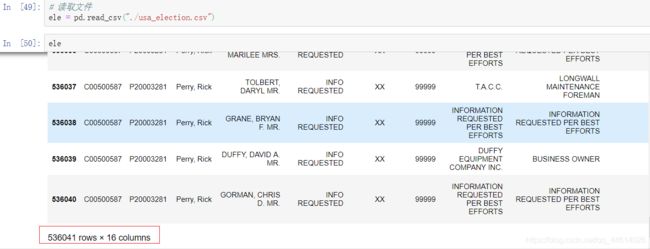
读取文件
总共有536041行,16个列(属性)
这只是美国总统大选政治捐献金的部分数据,不是全部的数据
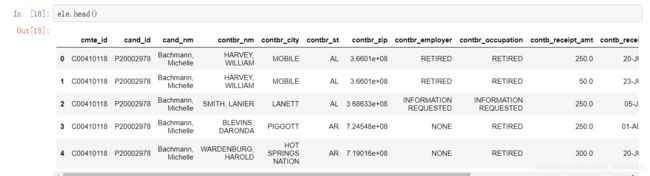
这里缺失了一些数据 关于党派信息的数据
将txt文件中的内容复制进来

执行一下这条语句
二. 将党派信息补充到表上
1. 方案一、合并
把党派信息创建成一个DataFrame对象,然后把DataFrame和ele对象合并,
这个合并以姓名为基准
- 创建一个数据表包含候选人姓名和党派,c_nm用于盛放候选人姓名,p_nm用于盛放党派
- 创建DataFrame对象
- 把DataFrame和ele对象合并
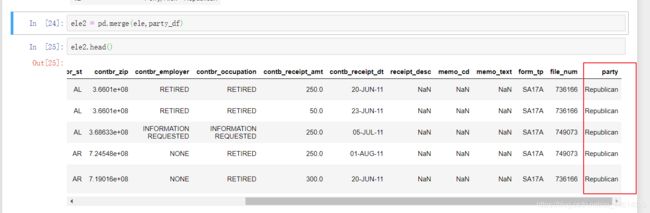
合并成功,可以看到多出一列数据party
,这是一个一对多的合并,因为在ele,也就是数据的文件中,这个人出现了多次
而相应的,在合并后的数据文件中,party属性也要和该人对应


2. 方案二、映射
映射使用map函数,map是使用Series来调用,所以首先要取出cand_nm这个属性
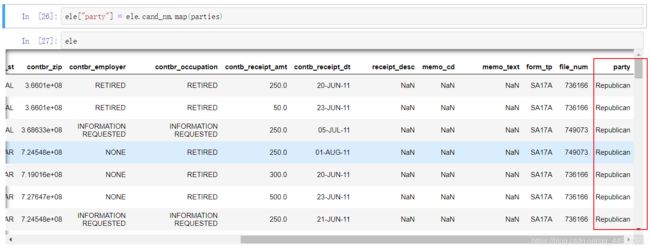
可以看到,此时就产生了party这一列
三. 查看信息
3.1 查看基本信息

3.2 查看表的统计数据

3.3 查看党派信息
一共有4个属性:共和党, 民主党,改良党,无党派人士

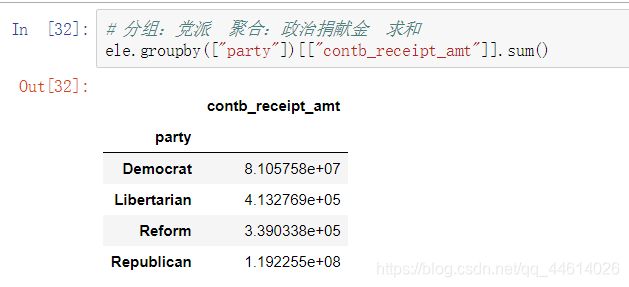
3.4 查看各个党派收到的政治捐献总金额
用到分组聚合方面的知识
分组:党派 ; 聚合:政治捐献金 ; 聚合方式: 求和
3.5 将所有数据按照日期进行排序
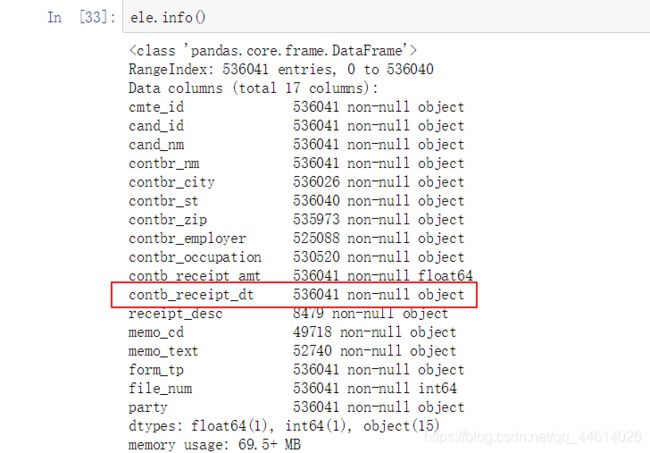
3.5.1 对日期进行整合
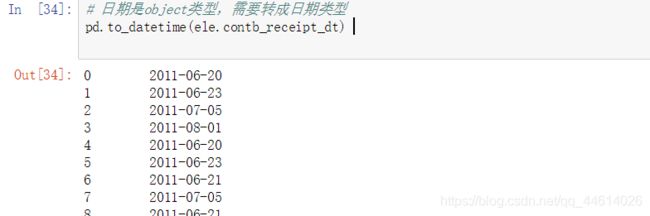
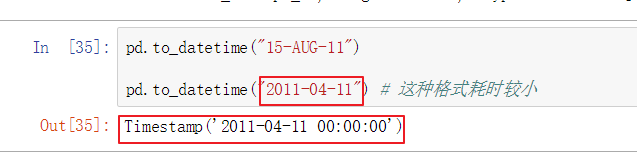
- 日期是object类型,需要转成日期类型
运行该命令,可以发现转换非常慢,因为数据量太大了,还有就是格式问题
查看一下日期
数据表中默认的日期格式耗时非常巨大,我们需要换成耗时较小的格式
第二种格式耗时比较小
将object类型,转成日期类型

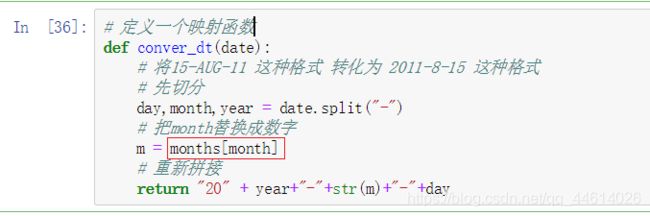
- 定义一个映射函数
这里的month就是前面的运行过的

- 类型转换
格式转换成功

3.5.2 政治捐献金
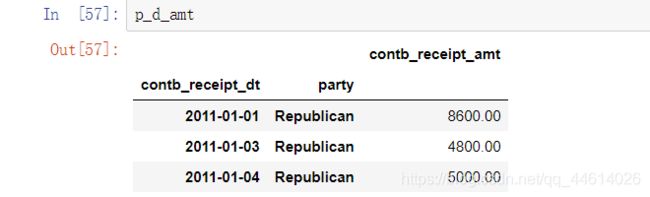
- 查看每一天,每个党派收到的政治捐献金总和
用到分组聚合
分组:日期和党派 聚合:政治捐献金
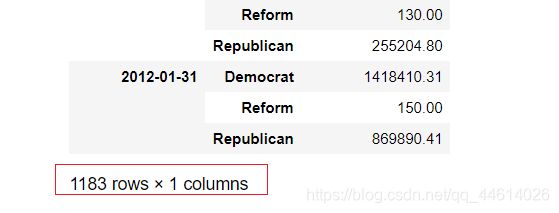
总共有1183行数据

- 查看每一天每个党派收到的政治捐献金的累积值并且画出累计值的曲线
什么叫累计值呢?
举个例子,你第一天吃了一个苹果,第二天吃了两个苹果,那么你第1天和第二天累计吃了3个苹果
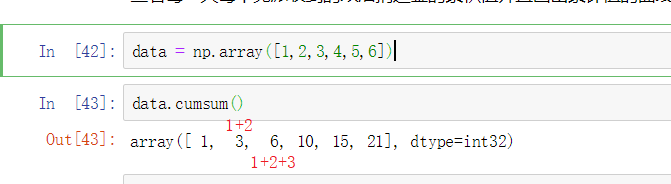
累计值要用到一个cumsum()的函数,举个例子
那是不是用cumsum()函数就能计算了呢?
试一下后发现
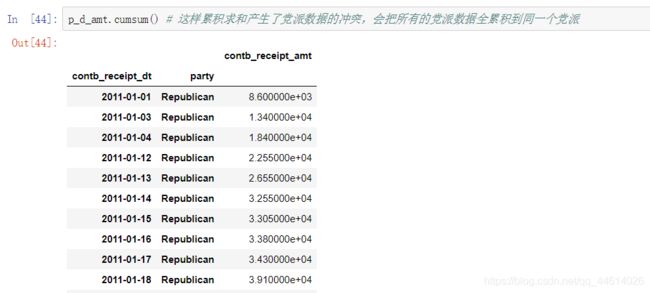
这样累积求和产生了党派数据的冲突,会把所有的党派数据全累积到同一个党派,因为这些党派都在同一列,没有分隔开,所以数据是不断叠加的
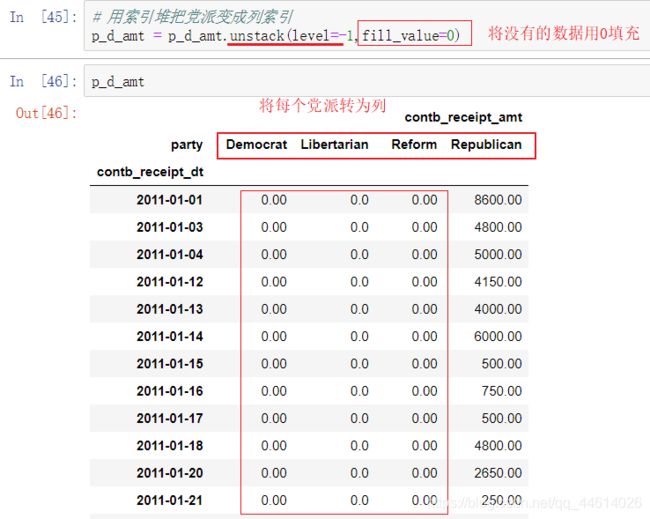
那么怎么解决?方法就是,将各个党派的数据弄出单独一列,每一列只有本党派的数据,这样就不会有数据的重叠
采用用索引堆把党派变成列索引
现在用cumsum()函数就能正确计算了
最后一步绘制图像
x轴为日期,y轴为政治捐献金



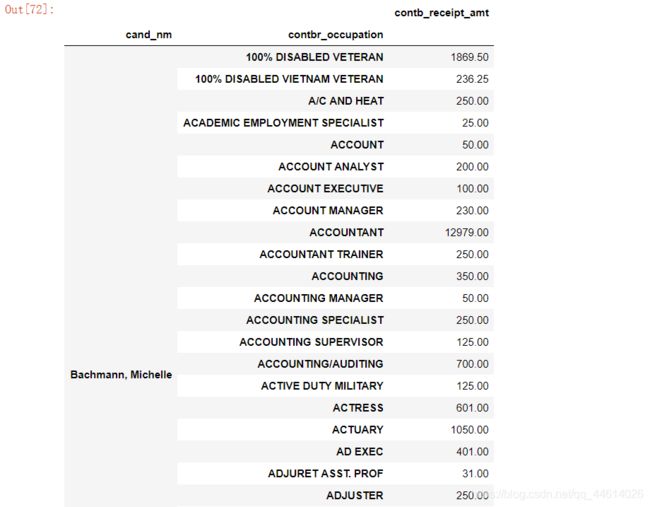
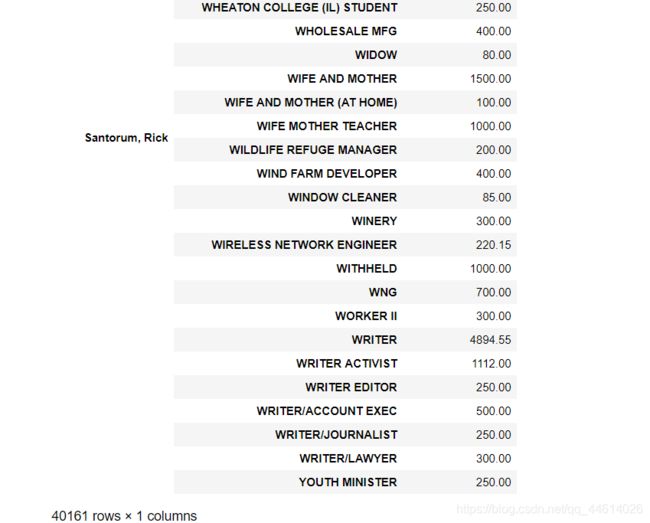
3.6 查看候选人姓名和其政治捐献者的职业以及其政治捐献情况
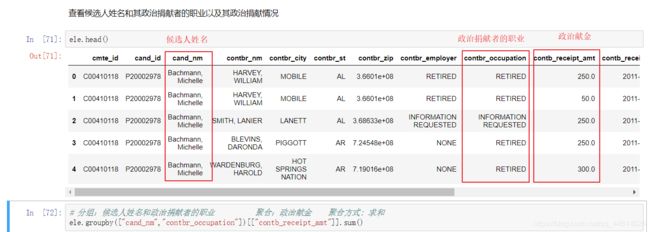
查看情况
3.7 查看企业高管都支持谁?
企业高管包括(CEO,BUSSINESS OWNER,CHIRMAN,OWNER)
方案一、建表级联
将企业高管(CEO,BUSSINESS OWNER,CHIRMAN,OWNER)每个都建一张表
将这些表级联


方案二、把以上所有的职业都用替换成"Senior Manager"