Sharding-JDBC
数据库优化的几个阶段
表的垂直拆分
是指按功能模块拆分,比如分为订单库、商品库、用户库…这种方式多个数据库之间的表结构不同。
假如你有幸能够在什么经营商、银行等公司上班,你会发现他们一个表,几百个字段都是很常见的事情。所以,应该要进行拆分,拆分准则一般是如下三点:
(1)把不常使用的字段单独放在一张表。
(2)把常使用的字段单独放一张表
(3)经常组合查询的列放在一张表中(联合索引)。
水平拆分
将同一个表的数据进行分块保存到不同的数据库中,这些数据库中的表结构完全相同。
实现方法:
(1)顺序拆分:如可以按订单的日前按年份才分,2003年的放在db1中,2004年的db2,以此类推。当然也可以按主键标准拆分。
优点:可部分迁移
缺点:数据分布不均,可能2003年的订单有100W,2008年的有500W。
(2)hash取模
优点:数据分布均匀
缺点:数据迁移的时候麻烦;不能按照机器性能分摊数据 。
数据库优化的几个阶段请参考:
https://www.songma.com/news/txtlist_i21939v.html
索引使用门槛
单表数据量达到几十万或上百万已上
分表使用门槛:
单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表。
分库分表适用场景
分库分表主要用于应对当前互联网常见的两个场景——大数据量和高并发。
1.数据量大时,减少单表查询压力
2.减少单表的访问压力
3.单表数据量上百万至千万,索引性能下降
4.索引也很难在提高性能或者更新、插入数据频繁等。
Sharding-JDBC直接封装JDBC API,可以理解为增强版的JDBC驱动,旧代码迁移成本几乎为零:
可适用于任何基于Java的ORM框架,如JPA、Hibernate、Mybatis、Spring JDBC Template或直接使用JDBC。
可基于任何第三方的数据库连接池,如DBCP、C3P0、 BoneCP、Druid等。
理论上可支持任意实现JDBC规范的数据库。虽然目前仅支持MySQL,但已有支持Oracle、SQLServer等数据库的计划。
Sharding-JDBC的不足
主要针对于分表,分库对于开发的影响较低。
1.增加了开发的难度,如如何使用分布式id,如何进行调优减少路由表的数目。如何写分库分表的算法等。
2.对于跨表的查询,有时反而会降低性能,而且调试困难。
3.对部分sql语法支持不太好。如分页越是靠后的Limit分页效率就会越低,也越浪费内存。
二、实现原理
Sharding-JDBC的整体架构如下:

分片
1.分片建:
用于分片的数据库字段,是将数据库(表)水平拆分的关键字段。例:订单表订单ID分片尾数取模分片,则订单ID为分片字段。SQL中如果无分片字段,将执行全路由,性能较差,支持多分片字段。
2.分片算法
分片算法需要应用方开发者自行实现,可实现的灵活度非常高。
精确分片算法(=与IN语句)
PreciseShardingAlgorithm:用于处理使用单一键作为分片键的=与IN进行分片的场景。需要配合StandardShardingStrategy使用。
其接口定义如下:
public interface PreciseShardingAlgorithm> extends ShardingAlgorithm {
/**
* Sharding.
*
* @param availableTargetNames available data sources or tables's names
* @param shardingValue sharding value
* @return sharding result for data source or table's name
*/
String doSharding(Collection availableTargetNames, PreciseShardingValue shardingValue);
范围分片算法(BETWEEN AND 语句)
RangeShardingAlgorithm:用于处理使用单一键作为分片键的BETWEEN AND进行分片的场景。需要配合StandardShardingStrategy使用。
其接口定义如下:
public interface RangeShardingAlgorithm> extends ShardingAlgorithm {
/**
* Sharding.
*
* @param availableTargetNames available data sources or tables's names
* @param shardingValue sharding value
* @return sharding results for data sources or tables's names
*/
Collection doSharding(Collection availableTargetNames, RangeShardingValue shardingValue);
3.分片策略:
1.数据源分片策略(DatabaseShardingStrategy)
对应于DatabaseShardingStrategy。用于配置数据被分配的目标数据源。
2.表分片策略(TableShardingStrategy)
对应于TableShardingStrategy。用于配置数据被分配的目标表,该目标表存在与该数据的目标数据源内。
JDBC规范重写
Sharding-JDBC对JDBC规范的重写思路是针对DataSource、Connection、Statement、PreparedStatement和ResultSet五个核心接口封装,将多个真实JDBC实现类集合(如:MySQL JDBC实现/DBCP JDBC实现等)纳入Sharding-JDBC实现类管理。
五大接口的对应实现关系如下
DataSource-----ShardingDataSource
Connection-----ShardingConnection
Statement-----ShardingStatement
PreparedStatement-----ShardingPreparedStatement
ResultSet-----ShardingResultSet
实现原理:
SQL解析—SQL改写-SQL路由–sql执行–结果归并
SQL解析
简单地说就是对sql语句进行语法分析,看是否符合Sharding-JDBC协议下的语法规则。
SQL解析作为分库分表类产品的核心,性能和兼容性是最重要的衡量指标。目前常见的SQL解析器主要有fdb/jsqlparser和Druid。Sharding-JDBC使用Druid作为SQL解析器,经实际测试,Druid解析速度是另外两个解析器的几十倍。
目前Sharding-JDBC支持join、aggregation(包括avg)、order by、 group by、limit、甚至or查询等复杂SQL的解析。目前不支持union、部分子查询、函数内分片等不太应在分片场景中出现的SQL解析。
分析sharding-jdbc源码的词法分析之前,先大概说一下词法分析是干嘛的,后面理解起来就会更容易,例如对于SQL:“/! hello, afei /delete ignore from t_user where user_id=? “而言,词法分析结果如下:
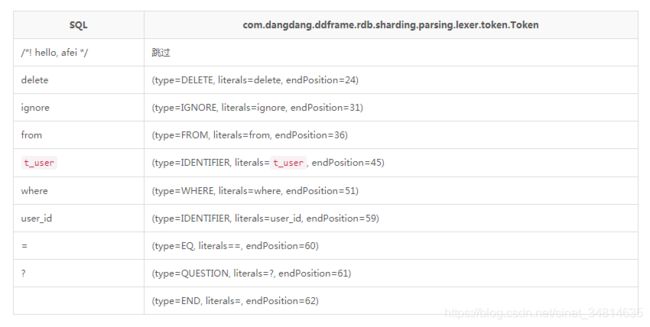
源码分析:
这里只看重要的SQL解析器,对应的源码是SQLParserFactory.newInstance(dbType, lexerEngine.getCurrentToken().getType(), shardingRule, lexerEngine),lexerEngine.getCurrentToken().getType()就是上面解析得到的第一个token的类型,核心实现源码如下:
@NoArgsConstructor(access = AccessLevel.PRIVATE)
public final class SQLParserFactory {
public static SQLParser newInstance(final DatabaseType dbType, final TokenType tokenType, final ShardingRule shardingRule, final LexerEngine lexerEngine) {
// 第一个token类型一定是默认关键词,否则抛出异常。构造这种异常很简单,只需要定义的SQL以MySQLKeyword中的关键词开头即可,例如"show create table t_order o"
if (!(tokenType instanceof DefaultKeyword)) {
throw new SQLParsingUnsupportedException(tokenType);
}
// 根据第一个token类型得到具体解析器,且第一个token一定是:select,insert,update,delete,create,alter,drop,truncate中的一个,否则会抛出SQLParsingUnsupportedException异常。构造这种异常很简单,只需要定义的sql以DefaultKeyword中的关键词开头,且不是下面枚举的关键词即可,例如"DATABASE SELECT o.* FROM t_order o"
switch ((DefaultKeyword) tokenType) {
// 从这里可知,为什么前面要调用lexerEngine.nextToken()获取第一个token,SQLParserFactory根据这个token才能确实哪种类型的SQL解析器
case SELECT:
return SelectParserFactory.newInstance(dbType, shardingRule, lexerEngine);
case INSERT:
return InsertParserFactory.newInstance(dbType, shardingRule, lexerEngine);
case UPDATE:
return UpdateParserFactory.newInstance(dbType, shardingRule, lexerEngine);
case DELETE:
return DeleteParserFactory.newInstance(dbType, shardingRule, lexerEngine);
case CREATE:
return CreateParserFactory.newInstance(dbType, shardingRule, lexerEngine);
case ALTER:
return AlterParserFactory.newInstance(dbType, shardingRule, lexerEngine);
case DROP:
return DropParserFactory.newInstance(dbType, shardingRule, lexerEngine);
case TRUNCATE:
return TruncateParserFactory.newInstance(dbType, shardingRule, lexerEngine);
default:
throw new SQLParsingUnsupportedException(lexerEngine.getCurrentToken().getType());
}
}
}
从上面的代码可知,得到的SQL解析器的一些主要属性有:
1.数据库类型dbType;
2.分库分表规则shardingRule;
3.词法分析器引擎lexerEngine;
4.判断是什么类型的sql,如是DQL还是DML等
SQL改写
SQL改写分为两部分,一部分是将分表的逻辑表名称替换为真实表名称。另一部分是根据SQL解析结果替换一些在分片环境中不正确的功能。这里具两个例子:
第1个例子是avg计算。在分片的环境中,以avg1 +avg2+avg3/3计算平均值并不正确,需要改写为(sum1+sum2+sum3)/(count1+count2+ count3)。这就需要将包含avg的SQL改写为sum和count,然后再结果归并时重新计算平均值。
第2个例子是分页。假设每10条数据为一页,取第2页数据。在分片环境下获取limit 10, 10,归并之后再根据排序条件取出前10条数据是不正确的结果。正确的做法是将分条件改写为limit 0, 20,取出所有前2页数据,再结合排序条件算出正确的数据。可以看到越是靠后的Limit分页效率就会越低,也越浪费内存。
源码分析:
核心源码就在sharding-jdbc-core模块的com.dangdang.ddframe.rdb.sharding.rewrite目录下,包含两个文件SQLBuilder和SQLRewriteEngine;
public SQLBuilder rewrite(final boolean isRewriteLimit) {
SQLBuilder result = new SQLBuilder();
if (sqlTokens.isEmpty()) {
result.appendLiterals(originalSQL);
return result;
}
int count = 0;
// 根据Token的beginPosition即出现的位置排序
sortByBeginPosition();
for (SQLToken each : sqlTokens) {
if (0 == count) {
// 第一次处理:截取从原生SQL的开始位置到第一个token起始位置之间的内容,例如"SELECT x.id FROM table_x x LIMIT 2, 2"这条SQL的第一个token是TableToken,即table_x所在位置,所以截取内容为"SELECT x.id FROM "
result.appendLiterals(originalSQL.substring(0, each.getBeginPosition()));
}
if (each instanceof TableToken) {
// 看后面的"表名重写分析"
appendTableToken(result, (TableToken) each, count, sqlTokens);
} else if (each instanceof ItemsToken) {
// ItemsToken是指当逻辑SQL有order by,group by这样的特殊条件时,需要在select的结果列中增加一些结果列,例如执行逻辑SQL:"SELECT o.* FROM t_order o where o.user_id=? order by o.order_id desc limit 2,3",那么还需要增加结果列o.order_id AS ORDER_BY_DERIVED_0
appendItemsToken(result, (ItemsToken) each, count, sqlTokens);
} else if (each instanceof RowCountToken) {
// 看后面的"rowCount重写分析"
appendLimitRowCount(result, (RowCountToken) each, count, sqlTokens, isRewriteLimit);
} else if (each instanceof OffsetToken) {
// 看后面的"offset重写分析"
appendLimitOffsetToken(result, (OffsetToken) each, count, sqlTokens, isRewriteLimit);
} else if (each instanceof OrderByToken) {
appendOrderByToken(result, count, sqlTokens);
}
count++;
}
return result;
}
private void sortByBeginPosition() {
Collections.sort(sqlTokens, new Comparator() {
// 生序排列
@Override
public int compare(final SQLToken o1, final SQLToken o2) {
return o1.getBeginPosition() - o2.getBeginPosition();
}
});
}
从这段源码可知,sql重写主要包括对表名,limit offset, rowNum以及order by的重写(ItemsToken值对select col1, col2 from… 即查询结果列的重写–需要由于ordre by或者group by需要增加一些结果列);
SQL路由
SQL路由是根据分片规则配置,将SQL定位至真正的数据源(表)。主要分为单表路由、Binding表路由和笛卡尔积路由。
单表路由最为简单,但路由结果不一定落入唯一库(表),因为支持根据between和in这样的操作符进行分片,所以最终结果仍然可能落入多个库(表)。
Binding表可理解为分库分表规则完全一致的主从表。举例说明:订单表和订单详情表都根据订单ID作为分片键,任意时刻分片逻辑均相同。这样的关联查询和单表查询难度和性能相当。
笛卡尔积查询最为复杂,因为无法根据Binding关系定位分片规则的一致性,所以非Binding表的关联查询需要拆解为笛卡尔积组合执行。查询性能较低,而且数据库连接数较高,需谨慎使用。
源码分析:
进入ShardingPreparedStatement类的executeQuery()方法
@Override
public ResultSet executeQuery() throws SQLException {
ResultSet result;
try {
// 核心方法route(),即解析SQL如何路由执行
Collection preparedStatementUnits = route();
// 根据路由信息执行SQL
List resultSets = new PreparedStatementExecutor(
getConnection().getShardingContext().getExecutorEngine(), routeResult.getSqlStatement().getType(), preparedStatementUnits, getParameters()).executeQuery();
// 对返回的结果进行merge合并
result = new ShardingResultSet(resultSets, new MergeEngine(resultSets, (SelectStatement) routeResult.getSqlStatement()).merge());
} finally {
clearBatch();
}
currentResultSet = result;
return result;
}
通过上面的源码可知,SQL查询两个核心:路由和结果合并,接下来一一分析sharding-jdbc如何实现;
路由route()核心源码如下:
private Collection route() throws SQLException {
Collection result = new LinkedList<>();
// 调用PreparedStatementRoutingEngine中的route()方法,
//route()方法调用sqlRouter.route(logicSQL, parameters, sqlStatement)
routeResult = routingEngine.route(getParameters());
for (SQLExecutionUnit each : routeResult.getExecutionUnits()) {
SQLType sqlType = routeResult.getSqlStatement().getType();
Collection preparedStatements;
if (SQLType.DDL == sqlType) {
preparedStatements = generatePreparedStatementForDDL(each);
} else {
preparedStatements = Collections.singletonList(generatePreparedStatement(each));
}
routedStatements.addAll(preparedStatements);
for (PreparedStatement preparedStatement : preparedStatements) {
replaySetParameter(preparedStatement);
result.add(new PreparedStatementUnit(each, preparedStatement));
}
}
return result;
}
SQLRouter接口有两个实现类:DatabaseHintSQLRouter和ParsingSQLRouter,由于这里没有用hint语法强制执行某个库,所以调用ParsingSQLRouter中的route()方法:
ParsingSQLRouter中的route()方法源码如下:
private RoutingResult route(final List接下来分析一下SimpleRoutingEngine和ComplexRoutingEngine;
SimpleRoutingEngine就是sql语句只会设计到一个table,SimpleRoutingEngine.route()源码如下:
@Override
public RoutingResult route() {
// 根据逻辑表得到tableRule,逻辑表为t_order;表规则的配置为:.actualTables(Arrays.asList("t_order_0", "t_order_1")),所以有两个实际表;
TableRule tableRule = shardingRule.getTableRule(logicTableName);
// 根据规则先路由数据源:即根据user_id取模路由
Collection routedDataSources = routeDataSources(tableRule);
// routedMap保存路由到的目标数据源和表的结果:key为数据源,value为该数据源下路由到的目标表集合
Map> routedMap = new LinkedHashMap<>(routedDataSources.size());
// 遍历路由到的目标数据源
for (String each : routedDataSources) {
// 再根据规则路由表:即根据order_id取模路由
routedMap.put(each, routeTables(tableRule, each));
}
// 将得到的路由数据源和表信息封装到RoutingResult中,RoutingResult中有个TableUnits类型属性,TableUnits类中有个List tableUnits属性,TableUnit包含三个属性:dataSourceName--数据源名称,logicTableName--逻辑表名称,actualTableName--实际表名称,例如:TableUnit:{dataSourceName:ds_jdbc_1, logicTableName:t_order, actualTableName: t_order_1}
return generateRoutingResult(tableRule, routedMap);
}
这样就找到了数据源和对应的表集合,完成了路由的所应该做的核心功能
源码分析参考自【死磕Sharding-jdbc】—–路由&执行 http://cmsblogs.com/?p=2530
SQL执行
路由至真实数据源后,Sharding-JDBC将采用多线程并发执行SQL,并完成对addBatch等批量方法的处理。
源码分析:
路由完成后就决定了SQL需要在哪些数据源的哪些实际表中执行,执行的核心代码在com.dangdang.ddframe.rdb.sharding.executor.ExecutorEngine中,核心源码如下
public List executePreparedStatement(
final SQLType sqlType, final Collection preparedStatementUnits, final List 主要流程为:
- 除第一个任务之外的任务异步执行,第一个任务同步执行
- 将第一个任务同步执行结果与其他任务异步执行结果合并得到最终的结果
结果归并
结果归并包括4类:普通遍历类、排序类、聚合类和分组类。每种类型都会先根据分页结果跳过不需要的数据。(最好只用到1,2种)
普通遍历类:普通遍历类最为简单,只需按顺序遍历ResultSet的集合即可。
排序类:排序类结果将结果先排序再输出,因为各分片结果均按照各自条件完成排序,所以采用归并排序算法整合最终结果。
聚合类“聚合类分为3种类型,比较型、累加型和平均值型。比较型包括max和min,只返回最大(小)结果。累加型包括sum和count,需要将结果累加后返回。平均值则是通过SQL改写的sum和count计算,相关内容已在SQL改写涵盖,不再赘述。
分组类:分组类最为复杂,需要将所有的ResultSet结果放入内存,使用map-reduce算法分组,最后根据排序和聚合条件做相关处理。最消耗内存,最损失性能的部分即是此,可以考虑使用limit合理的限制分组数据大小。
结果归并部分目前并未采用管道解析的方式,之后会针对这里做更多改进
sharding-jdbc分布式主键
数据库主键生成的几种策略
1.数据库自己生成,如MySQL的主键自增。但分库分表之后,不同表生成全局唯一的Id是非常棘手的问题。因为同一个逻辑表内的不同实际表之间的自增键是无法互相感知的, 这样会造成重复Id的生成。
2.程序的第三方,比如UUID等依靠特定算法自生成不重复键(由于InnoDB采用的B+Tree索引特性,UUID生成的主键插入性能较差),或者通过引入Id生成服务等。
3.以JDBC接口来实现对于生成Id的访问,而将底层具体的Id生成实现分离出来。如Sharding-JDBC使用分布式ID。
sharding-jdbc的分布式ID
github上对分布式ID这个特性的描述是:Distributed Unique Time-Sequence Generation,两个重要特性是:分布式唯一和时间序;基于Twitter Snowflake算法实现,长度为64bit;64bit组成如下:
- 1bit sign bit.
- 41bits timestamp offset from 2016.11.01(Sharding-JDBC distributed
primary key published data) to now. - 10bits worker process id.
- 12bits auto increment offset in one mills.
snowflake算法
snowflake算法所生成的ID结构是什么样子呢?我们来看看下图:
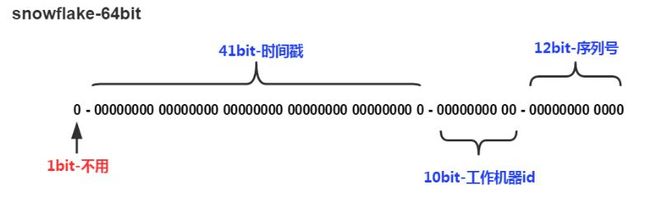
SnowFlake所生成的ID一共分成四部分:
1.第一位
占用1bit,其值始终是0,没有实际作用。
2.时间戳
占用41bit,精确到毫秒,总共可以容纳约140年的时间。
3.工作机器id
占用10bit,其中高位5bit是数据中心ID(datacenterId),低位5bit是工作节点ID(workerId),做多可以容纳1024个节点。
4.序列号
占用12bit,这个值在同一毫秒同一节点上从0开始不断累加,最多可以累加到4095。
SnowFlake算法在同一毫秒内最多可以生成多少个全局唯一ID呢?只需要做一个简单的乘法:
同一毫秒的ID数量 = 1024 X 4096 = 4194304
这个数字在绝大多数并发场景下都是够用的。
snowflake优缺点
SnowFlake算法的优点:
1.生成ID时不依赖于DB,完全在内存生成,高性能高可用。
2.ID呈趋势递增,后续插入索引树的时候性能较好。
SnowFlake算法的缺点:
依赖于系统时钟的一致性。如果某台机器的系统时钟回拨,有可能造成ID冲突,或者ID乱序。
snowflake算法的更多资料请参考:漫画:什么是SnowFlake算法?https://blog.csdn.net/bjweimengshu/article/details/80162731
插入操作
在进行主键id生成时,使用的是Sharding-JDBC内部的生成策略。如果是按时间分的表,生成的算法会与当前的时间有关,并且与当前时间是可逆的转换算法
设置Id生成器的实现类,该类必须实现io.shardingjdbc.core.keygen.KeyGenerator接口,其接口如下:
package io.shardingjdbc.core.keygen;
/**
* Key generator interface.
*
* @author zhangliang
*/
public interface KeyGenerator {
/**
* Generate key.
*
* @return generated key
*/
Number generateKey();
}
官方配置请参考:http://shardingsphere.io/document/legacy/2.x/cn/02-guide/key-generator/
读写分离
mysql主从复制原理
整体上来说,复制有3个步骤:
(1) master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events);
(2) slave将master的binary log events拷贝到它的中继日志(relay log);
(3) slave重做中继日志中的事件,将改变反映它自己的数据。
复制流程如下:
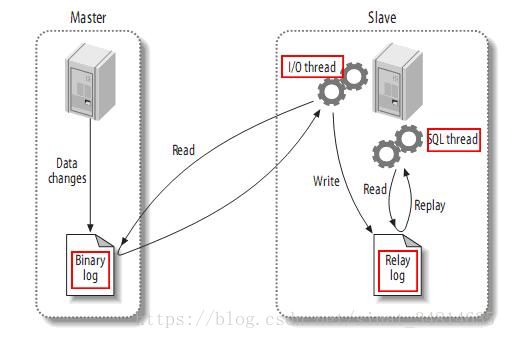
该过程的第一部分就是master记录二进制日志。在每个事务更新数据完成之前,master在二日志记录这些改变。MySQL将事务串行的写入二进制日志,即使事务中的语句都是交叉执行的。在事件写入二进制日志完成后,master通知存储引擎提交事务。
下一步就是slave将master的binary log拷贝到它自己的中继日志。首先,slave开始一个工作线程——I/O线程。I/O线程在master上打开一个普通的连接,然后开始binlog dump process。Binlog dump process从master的二进制日志中读取事件,如果已经跟上master,它会睡眠并等待master产生新的事件。I/O线程将这些事件写入中继日志。
SQL slave thread(SQL从线程)处理该过程的最后一步。SQL线程从中继日志读取事件,并重放其中的事件而更新slave的数据,使其与master中的数据一致。只要该线程与I/O线程保持一致,中继日志通常会位于OS的缓存中,所以中继日志的开销很小。
此外,在master中也有一个工作线程:和其它MySQL的连接一样,slave在master中打开一个连接也会使得master开始一个线程。复制过程有一个很重要的限制——复制在slave上是串行化的,也就是说master上的并行更新操作不能在slave上并行操作。
MySQL数据库主从同步延迟是怎么产生的。
当主库的TPS并发较高时,产生的DDL数量超过slave一个sql线程所能承受的范围(即执行这些ddl语句会耗时较大),那么延时就产生了,当然还有就是可能与slave的大型query语句产生了锁等待。
MySQL数据库主从同步延迟解决方案
1.数据库层面:
最简单的减少slave同步延时的方案就是在架构上做优化,尽量让主库的DDL快速执行。还有就是主库是写,对数据安全性较高,比如 sync_binlog=1,innodb_flush_log_at_trx_commit = 1 之类的设置,而slave则不需要这么高的数据安全,完全可以讲sync_binlog设置为0或者关闭binlog,innodb_flushlog也 可以设置为0来提高sql的执行效率。另外就是使用比主库更好的硬件设备作为slave。
2.引入缓存:
数据库的写操作,先写数据库,再写cache,但是有效期很短,就比主从延时的时间略微长一点。然后读请求的时候,先读缓存,缓存存在则直接返回。假如缓存不存在(这时主从同步已经完成),再读数据库。
3.强制路由:
对应一致性要求较高的读写请求,直接对主库读写
总结:建议从强制路由控制,这样才是正真的强一致性,而从数据库无法完全保证,且会牺牲数据安全等其他代价。
@see 深入解析Mysql 主从同步延迟原理及解决方案 https://www.cnblogs.com/cnmenglang/p/6393769.html
sharding-jdbc读写分离
前提条件:
- 开发者在配置文件配置了要进行读写分离
读写分离支持项
1.提供了一主多从的读写分离配置,可独立使用,也可配合分库分表使用。
2.同一线程且同一数据库连接内,如有写入操作,以后的读操作均从主库读取,用于保证数据一致性。
3.Spring命名空间。
4.基于Hint的强制主库路由。
读写分离不支持范围
主库和从库的数据同步。
主库和从库的数据同步延迟导致的数据不一致。
主库双写或多写。
ShardingPreparedStatement类在进行route()方法路由时会进行判断要不要进行读写分离和实现读写的逻辑。代码如下:
private Collection route() throws SQLException {
Collection result = new LinkedList<>();
routeResult = routingEngine.route(getParameters());
for (SQLExecutionUnit each : routeResult.getExecutionUnits()) {
SQLType sqlType = routeResult.getSqlStatement().getType();
Collection preparedStatements;
if (SQLType.DDL == sqlType) {
// 路由这里生成PreparedStatement时会选主从(如果是主从的话)
preparedStatements = generatePreparedStatementForDDL(each);
} else {
// 路由这里生成PreparedStatement时会选主从(如果是主从的话)
preparedStatements = Collections.singletonList(generatePreparedStatement(each));
}
routedStatements.addAll(preparedStatements);
for (PreparedStatement preparedStatement : preparedStatements) {
replaySetParameter(preparedStatement);
result.add(new PreparedStatementUnit(each, preparedStatement));
}
}
return result;
}
主从数据源中根据负载均衡策略获取数据源核心源码–MasterSlaveDataSource.java:
// 主数据源, 例如dbtbl_0_master对应的数据源
@Getter
private final DataSource masterDataSource;
// 主数据源下所有的从数据源,例如{dbtbl_0_slave_0:DataSource实例; dbtbl_0_slave_1:DataSource实例}
@Getter
private final Map slaveDataSources;
public NamedDataSource getDataSource(final SQLType sqlType) {
if (isMasterRoute(sqlType)) {
DML_FLAG.set(true);
// 如果符合主路由规则,那么直接返回主路由(不需要根据负载均衡策略选择数据源)
return new NamedDataSource(masterDataSourceName, masterDataSource);
}
// 负载均衡策略选择数据源名称[后面会分析]
String selectedSourceName = masterSlaveLoadBalanceStrategy.getDataSource(name, masterDataSourceName, new ArrayList(slaveDataSources.keySet()));
DataSource selectedSource = selectedSourceName.equals(masterDataSourceName) ? masterDataSource : slaveDataSources.get(selectedSourceName);
Preconditions.checkNotNull(selectedSource, "");
return new NamedDataSource(selectedSourceName, selectedSource);
}
// 主路由逻辑
private boolean isMasterRoute(final SQLType sqlType) {
return SQLType.DQL != sqlType || DML_FLAG.get() || HintManagerHolder.isMasterRouteOnly();
}
主路由逻辑如下:
1.非查询SQL(SQLType.DQL != sqlType)
2.当前数据源在当前线程访问过主库(数据源访问过主库就会通过ThreadLocal将DML_FLAG置为true,从而路由主库)(DML_FLAG.get())
3.HintManagerHolder方式设置了主路由规则(HintManagerHolder.isMasterRouteOnly())
强制路由
源码分析:
位于sharding-jdbc-core模块下的包com.dangdang.ddframe.rdb.sharding.hint中,核心类HintManagerHolder的部分源码如下:
/**
* Hint manager holder.
* Use thread-local to manage hint.
* @author zhangliang
*/
@NoArgsConstructor(access = AccessLevel.PRIVATE)
public final class HintManagerHolder {
// hint特性保存数据的核心变量,即保存一个HintManager类型对象到ThreadLocal中
private static final ThreadLocal HINT_MANAGER_HOLDER = new ThreadLocal<>();
/**
* Set hint manager.
* @param hintManager hint manager instance
*/
public static void setHintManager(final HintManager hintManager) {
Preconditions.checkState(null == HINT_MANAGER_HOLDER.get(), "HintManagerHolder has previous value, please clear first.");
HINT_MANAGER_HOLDER.set(hintManager);
}
public static boolean isUseShardingHint() {
// 判断当前线程中是否使用了sharding hint--即HintManager中的shardingHint为true
return null != HINT_MANAGER_HOLDER.get() && HINT_MANAGER_HOLDER.get().isShardingHint();
}
public static Optional> getDatabaseShardingValue(final ShardingKey shardingKey) {
// 如果使用了sharding hint,那么从ThreadLocal中取数据库的sharding值
return isUseShardingHint() ? Optional.>fromNullable(HINT_MANAGER_HOLDER.get().getDatabaseShardingValue(shardingKey)) : Optional.>absent();
}
public static Optional> getTableShardingValue(final ShardingKey shardingKey) {
// 如果使用了sharding hint,那么从ThreadLocal中取表的sharding值
return isUseShardingHint() ? Optional.>fromNullable(HINT_MANAGER_HOLDER.get().getTableShardingValue(shardingKey)) : Optional.>absent();
}
public static boolean isMasterRouteOnly() {
// 是否强制路由主库--sharding-jdbc的特性之一:强制路由
return null != HINT_MANAGER_HOLDER.get() && HINT_MANAGER_HOLDER.get().isMasterRouteOnly();
}
public static boolean isDatabaseShardingOnly() {
// 是否只是数据库sharding
return null != HINT_MANAGER_HOLDER.get() && HINT_MANAGER_HOLDER.get().isDatabaseShardingOnly();
}
/**
* Clear hint manager for current thread-local.
*/
public static void clear() {
// ThreadLocal用完需要清理
HINT_MANAGER_HOLDER.remove();
}
}
hreadLocal中管理的HintManager定义如下:
NoArgsConstructor(access = AccessLevel.PRIVATE)
public final class HintManager implements AutoCloseable {
// 数据库强制路由的值
private final Map> databaseShardingValues = new HashMap<>();
// 表强制路由的值
private final Map> tableShardingValues = new HashMap<>();
// 即是否使用了强制路由特性
@Getter
private boolean shardingHint;
// 是否强制路由到主数据库
@Getter
private boolean masterRouteOnly;
@Getter
private boolean databaseShardingOnly;
... ...
@Override
public void close() {
HintManagerHolder.clear();
}
}
sharding值保存在ThreadLocal中,所以需要在操作结束时调用HintManager.close()来清除ThreadLocal中的内容。
HintManager实现了AutoCloseable接口,推荐使用try with resource(JDK7新特性,参考Java 7中的Try-with-resources)自动关闭清理ThreadLocl线程中的数据。
强制路由主库
//强制路由主库//强制路由主库
HintManager hintManager = HintManager.getInstance();
hintManager.setMasterRouteOnly();
//业务代码。。。。
//操作结束时调用HintManager.close()来清除ThreadLocal中的内容。操作结束时调用HintManager.close()来清除ThreadLocal中的内容。
hintManager.close();
代理层控制读写分离
实现原理

在进入Service之前,使用AOP来做出判断,是使用写库还是读库,判断依据
1)可以根据方法名判断,比如说以query、find、get等开头的就走读库,其他的走写库。
2)拦截注解,这样是更细粒度的拦截如:
@Around("@annotation(readDatasource)")
public Object setReadDataSourceType(ProceedingJoinPoint pjp,ReadDatasource readDatasource) throws Throwable {
shardDataSourceAspect.before(pjp);
return pjp.proceed();
}
整合mybatis
用户自定义的读写控制逻辑类,需要继承org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource类,并实现protected abstract Object determineCurrentLookupKey()方法。
AbstractRoutingDataSource类选择数据源的总逻辑在determineTargetDataSource方法中,源码如下:
/**
* Retrieve the current target DataSource. Determines the
* {@link #determineCurrentLookupKey() current lookup key}, performs
* a lookup in the {@link #setTargetDataSources targetDataSources} map,
* falls back to the specified
* {@link #setDefaultTargetDataSource default target DataSource} if necessary.
* @see #determineCurrentLookupKey()
*/
protected DataSource determineTargetDataSource() {
Assert.notNull(this.resolvedDataSources, "DataSource router not initialized");
Object lookupKey = determineCurrentLookupKey();
DataSource dataSource = this.resolvedDataSources.get(lookupKey);
if (dataSource == null && (this.lenientFallback || lookupKey == null)) {
dataSource = this.resolvedDefaultDataSource;
}
if (dataSource == null) {
throw new IllegalStateException("Cannot determine target DataSource for lookup key [" + lookupKey + "]");
}
return dataSource;
}
参考资料:
1.解读分库分表中间件Sharding-JDBC https://blog.csdn.net/qiansg123/article/details/80121817
2.Sharding-JDBC官方文档 http://shardingsphere.io/document/current/cn/features/sharding/concept/sharding/
3.【死磕Sharding-jdbc】— 死磕 Sharding-jdbc 精品合集 http://cmsblogs.com/?p=2648
4.数据库优化的几个阶段https://www.songma.com/news/txtlist_i21939v.html
5.sharding-jdbc源码之强制路由https://www.jianshu.com/p/644e9d6afd2c
6.高性能Mysql主从架构的复制原理及配置详解https://blog.csdn.net/hguisu/article/details/7325124/
7.DQL、DML、DDL、DCL的概念与区别 https://www.cnblogs.com/fan-yuan/p/7879353.html
8.漫画:什么是SnowFlake算法?https://blog.csdn.net/bjweimengshu/article/details/80162731
9.Spring AOP 实现读写分离(MySQL实现主从复制)https://blog.csdn.net/zbw18297786698/article/details/54343188