Kafka系列1----Consumer Rebalance过程
1.Coordinator介绍
Coordinator简单的总结一下就是负责协调组内partition分配,以及Group的管理,每个Broker上都有一个GroupCoordinator的实例
负载均衡的过程涉及以下的几个概念
- group member:一个消费组类的成员
- group leader:一个消费组的leader,负责分配partition
- coodinator:协调者
涉及以下几个请求:
- GroupCoordinatorRequest(GCR)
- JoinGroupRequest(JGR)
- SyncGroupRequest(SGR)
2.主要流程
主要的流程如下:
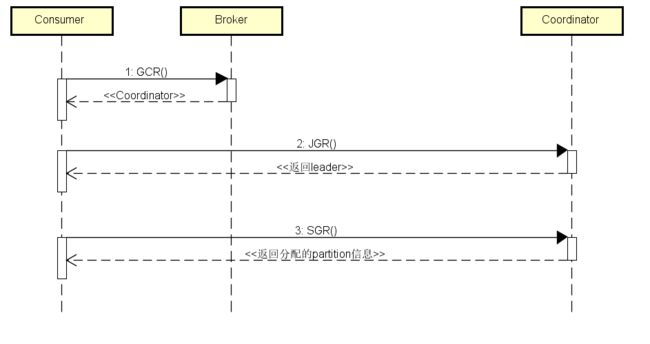
1. 发送GCR请求寻找Coordinator:这个过程主要会向集群中负载最小的broker发起请求,等待成功返回后,那么该Broker将作为Coordinator,尝试连接该Coordinator
2. 发送JGR请求加入该组:当成功找到Coordinator后,那么就要发起加入group的请求,表示该consumer是该组的成员,Coordinator会接收到该请求,会给集群分配一个Leader(通常是第一个),让其负责partition的分配
3. 发送SGR请求:JGR请求成功后,如果发现当前Consumer是leader,那么会进行partition的分配,并发起SGR请求将分配结果发送给Coordinator;如果不是leader,那么也会发起SGR请求,不过分配结果为空
流程图如下
3.具体实现
具体的过程是在ConsumerCoordinator.poll方法里实现的
public void poll(long now) {
invokeCompletedOffsetCommitCallbacks();
//手动指定分区的模式不会有rebalance过程
if (subscriptions.partitionsAutoAssigned() && coordinatorUnknown()) {
ensureCoordinatorReady();//GCR
now = time.milliseconds();
}
if (needRejoin()) {
if (subscriptions.hasPatternSubscription())
client.ensureFreshMetadata();
ensureActiveGroup();// JGR和SCR
now = time.milliseconds();
}
pollHeartbeat(now);
maybeAutoCommitOffsetsAsync(now);
}先看下ensureCoordinatorReady方法
protected synchronized boolean ensureCoordinatorReady(long startTimeMs, long timeoutMs) {
long remainingMs = timeoutMs;
while (coordinatorUnknown()) {//没找到coordinator 或者 coordinator 已经挂了
//具体获取Coordinator的过程
RequestFuture future = lookupCoordinator();
client.poll(future, remainingMs);
if (future.failed()) {
if (future.isRetriable()) {
remainingMs = timeoutMs - (time.milliseconds() - startTimeMs);
if (remainingMs <= 0)
break;
client.awaitMetadataUpdate(remainingMs);
} else
throw future.exception();
} else if (coordinator != null && client.connectionFailed(coordinator)) {
// we found the coordinator, but the connection has failed, so mark
// it dead and backoff before retrying discovery
coordinatorDead();
time.sleep(retryBackoffMs);
}
remainingMs = timeoutMs - (time.milliseconds() - startTimeMs);
if (remainingMs <= 0)
break;
}
return !coordinatorUnknown();
} 再看下lookupCoordinator方法
protected synchronized RequestFuture lookupCoordinator() {
if (findCoordinatorFuture == null) {
// 从集群中找出一个负载最小的broker节点
Node node = this.client.leastLoadedNode();
if (node == null) {
return RequestFuture.noBrokersAvailable();
} else
findCoordinatorFuture = sendGroupCoordinatorRequest(node);
}
return findCoordinatorFuture;
}
private RequestFuture sendGroupCoordinatorRequest(Node node) {
GroupCoordinatorRequest.Builder requestBuilder =
new GroupCoordinatorRequest.Builder(this.groupId);
return client.send(node, requestBuilder)
.compose(new GroupCoordinatorResponseHandler());
} 上面发送了GCR请求,请求参数就一个groupId,并且设置回调GroupCoordinatorResponseHandler,成功后会调用GroupCoordinatorResponseHandler的onSuccess方法
private class GroupCoordinatorResponseHandler extends RequestFutureAdapter<ClientResponse, Void> {
@Override
public void onSuccess(ClientResponse resp, RequestFuture future) {
log.debug("Received GroupCoordinator response {} for group {}", resp, groupId);
GroupCoordinatorResponse groupCoordinatorResponse = (GroupCoordinatorResponse) resp.responseBody();
Errors error = Errors.forCode(groupCoordinatorResponse.errorCode());
clearFindCoordinatorFuture();
if (error == Errors.NONE) {
synchronized (AbstractCoordinator.this) {
//成功后会返回broker节点的信息,那么consumer就与coordinator 建立连接
AbstractCoordinator.this.coordinator = new Node(
Integer.MAX_VALUE - groupCoordinatorResponse.node().id(),
groupCoordinatorResponse.node().host(),
groupCoordinatorResponse.node().port());
client.tryConnect(coordinator);
heartbeat.resetTimeouts(time.milliseconds());
}
future.complete(null);
} else if (error == Errors.GROUP_AUTHORIZATION_FAILED) {
future.raise(new GroupAuthorizationException(groupId));
} else {
future.raise(error);
}
}
} 分析完GCR请求之后,在看下发起JGR和CGR请求的ensureActiveGroup方法
public void ensureActiveGroup() {
//又调用了一次方法,判断是否已经找到Coordinator
ensureCoordinatorReady();
//开启心跳线程
startHeartbeatThreadIfNeeded();
//JGR和SGR请求的真正处理的地方
joinGroupIfNeeded();
}
void joinGroupIfNeeded() {
while (needRejoin() || rejoinIncomplete()) {
ensureCoordinatorReady();
// 提交offset、触发监听器、重置订阅关系
if (needsJoinPrepare) {
onJoinPrepare(generation.generationId, generation.memberId);
needsJoinPrepare = false;
}
// JGR和SGR
RequestFuture future = initiateJoinGroup();
client.poll(future);
resetJoinGroupFuture();
if (future.succeeded()) {
needsJoinPrepare = true;
// 成功之后执行的操作
onJoinComplete(generation.generationId, generation.memberId, generation.protocol, future.value());
} else {
RuntimeException exception = future.exception();
if (exception instanceof UnknownMemberIdException ||
exception instanceof RebalanceInProgressException ||
exception instanceof IllegalGenerationException)
continue;
else if (!future.isRetriable())
throw exception;
time.sleep(retryBackoffMs);
}
}
} needRejoin方法返回rejoinNeeded的值,表示是否需要重新发起JCR请求,这个后面会讲到
rejoinIncomplete=>joinFuture != null ,joinFuture是发起JCR请求后返回的futrue,在完成之后,会将其设置为null,joinFuture != null即表示在请处理当中,则执行循环(joinFuture!=null表示请求已经在执行了,但是为什么还需要重试?)
initiateJoinGroup方法如下
private synchronized RequestFuture initiateJoinGroup() {
if (joinFuture == null) {
disableHeartbeatThread();
state = MemberState.REBALANCING;
joinFuture = sendJoinGroupRequest();
joinFuture.addListener(new RequestFutureListener() {
@Override
public void onSuccess(ByteBuffer value) {
synchronized (AbstractCoordinator.this) {
state = MemberState.STABLE;//改变当前组的状态
if (heartbeatThread != null)
heartbeatThread.enable();
}
}
});
}
return joinFuture;
}
private RequestFuture sendJoinGroupRequest() {
if (coordinatorUnknown())
return RequestFuture.coordinatorNotAvailable();
JoinGroupRequest.Builder requestBuilder = new JoinGroupRequest.Builder(
groupId,
this.sessionTimeoutMs,
this.generation.memberId,
protocolType(),
metadata()).setRebalanceTimeout(this.rebalanceTimeoutMs);
return client.send(coordinator, requestBuilder)
.compose(new JoinGroupResponseHandler());
}
private class JoinGroupResponseHandler extends CoordinatorResponseHandler<JoinGroupResponse, ByteBuffer> {
@Override
public void handle(JoinGroupResponse joinResponse, RequestFuture future) {
Errors error = Errors.forCode(joinResponse.errorCode());
if (error == Errors.NONE) {
sensors.joinLatency.record(response.requestLatencyMs());
synchronized (AbstractCoordinator.this) {
if (state != MemberState.REBALANCING) {
future.raise(new UnjoinedGroupException());
} else {
AbstractCoordinator.this.generation = new Generation(joinResponse.generationId(),
joinResponse.memberId(), joinResponse.groupProtocol());
AbstractCoordinator.this.rejoinNeeded = false;
if (joinResponse.isLeader()) {
onJoinLeader(joinResponse).chain(future);
} else {
onJoinFollower().chain(future);
}
}
}
} else if (error == Errors.GROUP_LOAD_IN_PROGRESS) {
....
} else if (error == Errors.UNKNOWN_MEMBER_ID) {
....
} else if (error == Errors.GROUP_COORDINATOR_NOT_AVAILABLE || error == Errors.NOT_COORDINATOR_FOR_GROUP) {
....
} else if (error == Errors.INCONSISTENT_GROUP_PROTOCOL || error == Errors.INVALID_SESSION_TIMEOUT || error == Errors.INVALID_GROUP_ID) {
....
} else if (error == Errors.GROUP_AUTHORIZATION_FAILED) {
....
} else {
....
}
}
} 看到进来的时候,会判断joinFuture == null,这个为了防止在请求还没处理完的时候,又重复执行了加入组的操作,那么外面joinFuture != null会继续执行下面的代码,应该只有一种可能,就是请求失败了,重新执行client.poll(future);这个操作获取结果
sendJoinGroupRequest才是发送请求的地方,同GCR,看下handler的回调方法,response会返回是否leader的标志,按照一开始说的,leader需要通过SGR请求把分配结果发送给Coodinator,而follower不需要该参数
那么onJoinLeader和onJoinFollower方法就很好猜了,发送SGR请求,直接看对应的handler。不过onJoinLeader里会分配好partition
private class SyncGroupResponseHandler extends CoordinatorResponseHandler<SyncGroupResponse, ByteBuffer> {
@Override
public void handle(SyncGroupResponse syncResponse,
RequestFuture future) {
Errors error = Errors.forCode(syncResponse.errorCode());
if (error == Errors.NONE) {
sensors.syncLatency.record(response.requestLatencyMs());
future.complete(syncResponse.memberAssignment());//这是分配的结果,将其设置到future中,在onJoinComplete中使用
} else {
requestRejoin();
if (error == Errors.GROUP_AUTHORIZATION_FAILED) {
...
} else if (error == Errors.REBALANCE_IN_PROGRESS) {
...
} else if (error == Errors.UNKNOWN_MEMBER_ID || error == Errors.ILLEGAL_GENERATION) {
....
} else if (error == Errors.GROUP_COORDINATOR_NOT_AVAILABLE || error == Errors.NOT_COORDINATOR_FOR_GROUP) {
....
} else {
....
}
}
}
} 返回没什么说的,看下失败的情况,requestRejoin这个方法,会把rejoinNeeded设置为true,那么在外面循环的条件就是rejoinNeeded为true,就会再次执行
这里有种情况就是一个leader和一个follower,follower先发起了请求但是leader还没有将分配结果发送出去,那么follower这时是取不到分配结果的,那么会请求失败,设置为true之后,重新执行这个过程
SGR和JGR请求成功之后,会执行onJoinComplete方法
protected void onJoinComplete(int generation,String memberId,String assignmentStrategy,ByteBuffer assignmentBuffer) {
// 只有leader才负责数据的变化
if (!isLeader)
assignmentSnapshot = null;
PartitionAssignor assignor = lookupAssignor(assignmentStrategy);
if (assignor == null)
throw new IllegalStateException("Coordinator selected invalid assignment protocol: " + assignmentStrategy);
//这个assignmentBuffer就是SyncGroupResponseHandler往future设置的值
Assignment assignment = ConsumerProtocol.deserializeAssignment(assignmentBuffer);
// set the flag to refresh last committed offsets
subscriptions.needRefreshCommits();
// 更新leader分配的partition
subscriptions.assignFromSubscribed(assignment.partitions());
// check if the assignment contains some topics that were not in the original
// subscription, if yes we will obey what leader has decided and add these topics
// into the subscriptions as long as they still match the subscribed pattern
//
// TODO this part of the logic should be removed once we allow regex on leader assign
Set addedTopics = new HashSet<>();
for (TopicPartition tp : subscriptions.assignedPartitions()) {
if (!joinedSubscription.contains(tp.topic()))
addedTopics.add(tp.topic());
}
if (!addedTopics.isEmpty()) {
Set newSubscription = new HashSet<>(subscriptions.subscription());
Set newJoinedSubscription = new HashSet<>(joinedSubscription);
newSubscription.addAll(addedTopics);
newJoinedSubscription.addAll(addedTopics);
this.subscriptions.subscribeFromPattern(newSubscription);
this.joinedSubscription = newJoinedSubscription;
}
// update the metadata and enforce a refresh to make sure the fetcher can start
// fetching data in the next iteration
this.metadata.setTopics(subscriptions.groupSubscription());
client.ensureFreshMetadata();
// give the assignor a chance to update internal state based on the received assignment
assignor.onAssignment(assignment);
// reschedule the auto commit starting from now
this.nextAutoCommitDeadline = time.milliseconds() + autoCommitIntervalMs;
// execute the user's callback after rebalance
ConsumerRebalanceListener listener = subscriptions.listener();
log.info("Setting newly assigned partitions {} for group {}", subscriptions.assignedPartitions(), groupId);
try {
Set assigned = new HashSet<>(subscriptions.assignedPartitions());
listener.onPartitionsAssigned(assigned);//执行监听
} catch (WakeupException | InterruptException e) {
throw e;
} catch (Exception e) {
log.error("User provided listener {} for group {} failed on partition assignment",
listener.getClass().getName(), groupId, e);
}
} 到这里,Rebalance过程就结束了