(DenseNet)Densely Connected Convolutional Networks论文阅读笔记
文章目录
- (DenseNet)Densely Connected Convolutional Networks论文阅读笔记2018
- Abstract
- 1. Introduction
- 2. Related Work
- 3. DenseNets
- 4. Experiments
- 4.1 Datasets
- 4.2 Training
- 4.3 Classification Results on CIFAR and SVHN
- 4.4 Classification Results on ImageNet
- 5. Discussion
- 6. Conclusion
(DenseNet)Densely Connected Convolutional Networks论文阅读笔记2018
Abstract
最近的工作表明,对于CNN,如果在接近输入或输出的那些卷积层之间包含一些更短的连接,网络可以持续的变深,且训练更有效率,取得更好的准确率。本文中,我们在此基础上提出了一种密集卷积网络(DenseNet),**它以前馈方式将每一层连接到其他每一层上。**对于传统的有L层的卷积网络,==有着L个连接,即一个接一个的,那么我们的网络就有着L(L+1)/2个连接,即每层与后面的所有层都有连接。对于每一层,前面所有层的特征图都作为输入,它的特征图又作为后面所有层的输入。==DenseNet有下面几个优点:
- 减轻了梯度消失的问题
- 增强了特征的传播,使得特征可以反复使用
- 减少了参数量
我们在四个数据集上评估了我们的结构(CIFAR-10/100、SVHM、ImageNet),DenseNet在大部分任务中都对SOTA取得了提升,且计算量更少。
1. Introduction
CNN已经成为视觉目标识别任务中的统治性方法。尽管20多年前就有了,近年来随着计算机硬件和网络结构进步,才使得CNN成为了主流。
随着CNN越来越深,一个新的研究问题出现了:因为输入或梯度的信息要穿过好多层,因此在它传到最后或最初(梯度回传)的时候,它可能会消失。许多最近的论文在试图解决相关问题。ResNet和Highway Network通过identity mapping来在层之间传递信号。FractalNets重复地组合几个有着不同卷积数的平行层来获得一个比较深的深度,同时保持网络中有许多的short paths。尽管这些方法在网络的拓扑结构和训练流程上不同,它们都有一个特点:对前面的层引入一个short path接到后面的层。
本文中,我们提出了一种结构,将这种想法变成简单的连接:确保网络的各层中可以传递最多的信息,我们直接连接了所有层(匹配特征图尺寸)。为了保持前馈方式,每个层都获得了前面所有层的输入并且将自己的特征图输出到后面所有层中。图1展示了网络的结构:
关键的一点是,与ResNet不同,**我们不会在特征传到层之前就通过求和将特征进行组合;相反,我们通过级联的方式将这些输入进行组合。**因此,第l层有l个输入,它生成的特征图又会传到后面所有层中,因此对于L层的网络,一共有L(L+1)/2个连接。因为这种密集连接,所以我们把网络叫做DenseNet。
**这种密集连接有着一个违背直觉的特点,它需要更少的参数,因为不需要重新学习之前的特征图。**传统的前馈结构可以看做具有状态的算法,一层一层的逐层进行传递。每一层读取前一层的状态然后传到下一层,这个过程改变了状态,同时也会传递需要保存的信息。ResNet将前一层信息保存,然后通过identity变换来相加。最近的一些ResNet变体研究表明,有许多层的贡献很小,实际上可以随机dropout。这就使得ResNet的状态与RNN相近,但是ResNet的参数更多,因为每一层都有自己的权值。我们提出的DenseNet结构明确区分添加到网络的信息和保留的信息。DenseNet层非常的窄(可能每层只有12filters),对整体的“collective knowledge”只增加很小的特征图,且保持特征图不变,最后的分类器基于的是整个网络的所有特征图做出决策。
除了更少的参数量,DenseNet的另一个优点在于提升了信息和提出在网络之间的传播,使得训练更加容易。每层有与loss函数梯度直接相连的access,和与各层输入相连的通道。这对训练深层网络很有效。而且,我们同样观察到密集连接有正则化的效果,这会减小在小训练集上任务的过拟合。
2. Related Work
对网络结构的探索一直是神经网络研究的一部分。现代网络中层数的增加加深了网络结构之间的差别,因此就激励研究人员探索不同的网络结构以及对旧的想法的重新审视。
类似我们的DenseNet的一种级联结构在1980s就已经出现。它们主要关注一层一层训练多层的FC感知机。之后,全连接的级联网络提出,尽管在小的数据集上有效,这种网络只有几百的参数。目前,利用shortcut来利用CNN中多等级的特征已经证明有效。
Highway Network几乎是第一个提出了有效训练超过100层的CNN方法的网络。使用了带有门单元的bypassing paths,上百层的网络都可以优化。这种bypass path被认为是减轻深层网络训练困难的关键因素。这个观点被ResNet进一步证实,它使用了纯的恒等映射当作bypass path。ResNet在许多任务上都取得了打破纪录的效果。最近,stochastic depth提出,使用这种方式可以成功训练1202层的ResNet,它是通过训练中随机丢弃层来实现,因为有大量的层是冗余的。
使得网络更深的一种正交方法就是增加网络的宽度。GooLeNet使用了Inception模块,来将不同卷积生成的特征图级联在一起。实际上,简单增加ResNet中每层的卷积核数量,在网络足够深的时候是可以改善网络性能的。FractalNets通过使用更宽的网络结构,同样在一些数据集上取得了很好的效果。
**与通过更深或更宽的网络结构获得更强的表示能力不同,DenseNet通过对特征的重复使用来获得网络的潜在能力,这使得我们的网络更好训练,效率更高。**通过不同层学习到的级联特征图增加了后续层输入的信息,且提升了效率。这就是DenseNet和ResNet的主要不同,与Inception相比,DenseNet更加简单有效。
有一些其他的网络结构也取得了不错的效果。NIN网络在卷积层中引入了小的多层感知机来提取更复杂的特征。深度监督网络(DSN)中,中间的层被额外的分类器所监督,这可以增强前面层接收到的梯度。Ladder Network对自动编码器中引入了横向连接,对于半监督学习任务中取得了很好的效果。深度融合网络(DFN)通过组合不同基础网络的中间层来提升信息的flow。
3. DenseNets
考虑单张图像x0,传进一个CNN。网络有L层,每层应用一个非线性的变换Hl(.),l为层的下标。这个非线性变换可以是许多操作,比如BN、ReLU、池化、conv。我们设第l层的输出为xl。
ResNets
传统的卷积前馈网络将l层的输入作为l+1层的输入,因此变换如下:![]() 。ResNet增加了一个skip连接,变换更改为:
。ResNet增加了一个skip连接,变换更改为: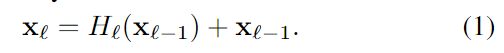
ResNet的优点在于梯度可以直接从后面层的identity连接回传到前面的层。然而,这个组合是通过求和得到的,可能会阻碍网络中信息的传递。
Dense connectivity.
为了进一步提升信息在层之间的传递,我们提出了一种不同的连接样式:对每个层与后续的层直接引入连接,如图1所示。这样,第l层接受的就是l之前左右层的特征图作为输入:
为了应用简单,我们把之前的特征图进行了级联,变幻成一个tensor,送入l层进行变换处理。
Composite function.
我们定义H为连续的三个操作:BN+ReLU+3 * 3conv。
Pooling layers.
当特征图的尺寸不一致的时候,式子2中级联操作就出现了问题。然而,卷积网络中的一个重要的操作就是下采样。为了在我们的网络中实现下采样,我们将网络分成多个密集连接的dense blocks,如图2所示。
在block之间的层我们设为过渡层,进行卷积以及池化来下采样。我们的过渡层通常包括一个BN+1 * 1卷积+2 * 2平均池化。
Growth rate.
**在每个Hl函数中,生成k通道特征图,这遵循着第l层有k0+k*(l-1)通道的输入,k0为输入层的通道数。**DenseNet与ResNet的一个最重要区别在于DenseNet可以很窄,比如k = 12。我们将这个超参数k设为网络的成长率(growth rate)。在第四部分我们会发现一个相对较小的成长率就足以获得SOTA。一种解释是每一层都有通向之前所有层的通道,因此可以访问网络的“collective knowledge”。可以把特征图当作网络的全局状态,每一层都添加k个自己的特征图到这个状态中。成长率决定了每一层对全局状态贡献新信息的多少。全局状态可以被网络中所有层访问,因此不需要每一层复制它,所以不需要很大的k。
Bottleneck layers.
尽管每一层只产生k个输入特征图,但是它一般有着更多的输入。1 * 1卷积可以用在每个3 * 3卷积之前,用作瓶颈层,来降低输入特征图的数量,因此可以提升计算效率。我们发现这种设计对于DenseNet非常有效,因此我们将这样的瓶颈层引入了网络,比如BN-ReLU-Conv(1 * 1)-BN-ReLU-Conv(3 * 3)版本的Hl,我们记作DenseNet-B。在我们的实验中,我们让每个1 * 1卷积生成4k个特征图。
Compression.
为了进一步提升模型紧凑性,我们可以减少过渡层之中特征图的数量。如果dense block有m个特征图,我们让接下来的过渡层生成![]() 个输出特征图,这个参数是压缩参数,在[0,1]之间。当参数为1的时候,过渡层的特征图数量不变。我们将参数小于1的模型记作DenseNet-C,我们实验中设置参数为0.5。当既使用了瓶颈又使用了压缩参数小于1的模型,我们记作DenseNet-BC。
个输出特征图,这个参数是压缩参数,在[0,1]之间。当参数为1的时候,过渡层的特征图数量不变。我们将参数小于1的模型记作DenseNet-C,我们实验中设置参数为0.5。当既使用了瓶颈又使用了压缩参数小于1的模型,我们记作DenseNet-BC。
Implementation Details.
在除了ImageNet的所有数据集,我们的网络使用了三个dense block,每个block层数相同。在进入第一个dense block之前,对输入图像进行一次卷积,通道数为16(对于BC,为成长率的2倍)。对于每个3 * 3卷积,使用zero-padding1来保持特征图尺寸不变。过渡层使用1 * 1卷积和2 * 2的平均池化。在最后一个dense block之后,使用一个全局平均池化,然后一个softmax分类器。在三个dense block之内的特征图大小为32 * 32、16 * 16、8 * 8。实验中我们使用如下配置来实验基础的DenseNet:{L=40,k=12}、{L=100,k=12}、{L=100,k=24}。对于DenseNet-BC,使用如下配置:{L=100,k=12}、{L=250,k=24}、{L=190,k=40}。
在ImageNet上,我们使用有着4个block的DenseNet-BC,输入图像224 * 224。初始的卷积层包含2k个7 * 7,步长2的卷积;其它层的特征图数量遵守k,网络的配置如表1所示。
4. Experiments
我们在几个数据集上测试了DenseNet的效果,并与SOTA结构进行比较,尤其是ResNet和其变体。
4.1 Datasets
CIFAR:两个CIFAR数据集包含32 * 32像素的彩色图像,分别包含10类和20类目标,训练分别有50000和10000张,我们选出5000训练集当作验证集。我们使用了标准的数据增强策略(镜像,平移),使用这种数据增强策略的我们在数据集名字后加上加号,比如“C10+”。我们使用了通道均值和标准差进行了预处理。我们使用所有50000训练图像,报告最后的测试错误率。
SVHN:SVH包含了32 * 32的彩色数字图像,73257张训练集,26032张测试集以及531131张额外训练集。我们使用所有的训练数据,不使用任何数据增强,使用从训练集找出的6000张当作验证集。训练中我们选择最低验证错误率的模型,报告它的测试错误率。将所有的像素值除以255,这样它们就在[0,1]之间了。
ImageNet:包含1.2million训练集,50000验证集,1000类图像。使用与之前文章中相同的数据增强手段,测试时候使用单独的crop或10个crop平均。报告在验证集上的分类错误率。
4.2 Training
所有模型使用SGD进行训练。在CIFAR和SVHN使用64的batchsize训练300/40epochs。初始学习率为0.1,训练50%和75%的时候除以10。在ImageNet上,以256的batchsize训练90epochs,学习率为0.1,在30和60epoch除以10。
使用0.0001的权值衰减和0.9的动量。对于未使用数据增强的数据集,在每个卷积层(除了第一个)后使用一个dropout层(0.2)。
4.3 Classification Results on CIFAR and SVHN
我们训练了不同深度L和成长率k的DenseNet。在CIFAR和SVHN上的主要结果如表2所示。
Accuracy
可能最值得注意的一个趋势来自表2的最后一行,DenseNet-BC,L=190,k=40在CIFAR数据集上超过了所有现存的SOTA方法。在SVHM上,使用dropout,L=100,k=24的DenseNet同样超过了wide ResNet达成的最好结果。然而250层的DenseNet-BC没有进一步提升效果,可能是因为SVHN是一个叫简单的任务,非常深的模型可能会过拟合。
Capacity.
不使用压缩和瓶颈层,有一个趋势是随着L和k的增加,DenseNet效果更好。我们把这个归因于模型容量的相对增长。这表明DenseNet可以利用更大更深模型增大的表示能力,同样表明它们不会受到过拟合和残差网络优化困难的制约。
Parameter Efficiency.
**表2中的结果表明DenseNet比其他的网络结构(尤其是ResNet)可以更有效地利用参数。DenseNet-BC尤其是参数有效率的。**比如,我们250层的模型只有15.3M参数,但是超过了有30M参数的其他模型。我们同样发现DenseNet-BC,L=100,k=12模型取得了与1001层ResNet相当的结果,但是比它的参数少90%。图4(右)展示了这两个网络在C10+上的训练loss和测试错误率。1001层的ResNet取得了更低的训练loss,但是却取得了与我们模型相似的测试错误率。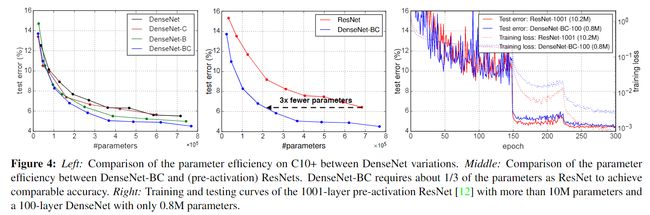
Overfitting.
我们同样发现,DenseNet更不易于过拟合。我们观察到在不使用数据增强的数据集上,DenseNet结构的提升非常明显。在我们的实验中,我们在一个单一设置中观察到潜在的过拟合:在C10,将k从12提升到24,导致错误率从5.77%提升到了5.83%。使用DenseNet-BC可以有效克服这个困难。
4.4 Classification Results on ImageNet
我们使用不同深度和成长率的DenseNet-BC,在ImageNet分类任务上进行评估,并与SOTA ResNet结构进行比较。为了确保比较公平,我们消除了两者其他应用上的不同,使用通用的设置。直接将ResNet模型替换为DenseNet-BC,保持其他的试验设置不变。
表3中我们报告了单crop和10crop的验证错误率。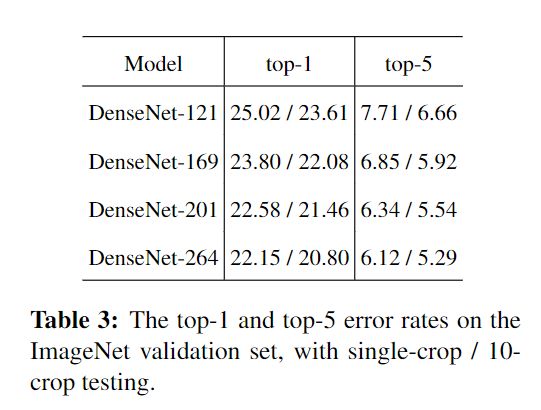
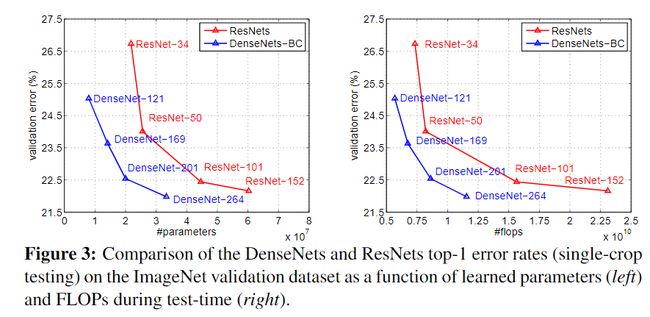
图3展示了单crop的错误率随着参数和flop的变化曲线图。图中表明,DenseNet的表现与SOTA的ResNet效果相当,同时有着更少的参数和计算量。
值得注意的是,本次实验,我们对DenseNet的超参数设置使用的与ResNet相同,如果使用的是更适合DenseNet的超参数,效果可能会更好。
5. Discussion
从表面上看,DenseNets与ResNets非常相似,式子2和式子1非常相似,唯一的不同就是一个是相加,一个是通道上级联。然而这种小小的不同导致了两个网络结构表现的大不同。
Model compactness.
作为输入级联的一个直接结果,每个DenseNet层学习到的特征图都可以被后续层所使用。这在网络中导致了特征图的重复使用,模型就更加紧凑了。
图4左边的两幅图展示了实验的结果,比较了不同DenseNet变体以及ResNet变体的参数效率。我们在C10上训练了多个不同深度的网络,画出它们测试准确率和参数之间的函数关系图像。在与其他比较流行的网络结构比较中,比如AlexNet、VGG-net。带有pre-activation的ResNet使用更少的参数取得了更好的效果。因此我们使用DenseNet(k=12)与其进行比较。
图中表示DenseNet-BC是DenseNet变体中最有效率的,而且可以达到相当的准确率,DenseNet-BC只需要ResNet的三分之一的参数。
Implicit Deep Supervision.
对于DenseNet提升准确率的一种解释是每一层都通过shorter connections收到了额外的来自loss函数的监督。可以看做是一种深度监督。深度监督网络的优点在DSN中已经有所展现,这个网络将分类器连接到每个隐藏层,使得中间层学习判别特征。
DenseNet以一种隐式的方式完成了相似的深度监督。一个单独的分类器在网络最后,但是为其提供了所有层的信息监督。然而DenseNet的loss函数和梯度不怎么复杂,因为所有层共享相同的loss函数。
Stochastic vs. deterministic connection.
在密集的卷积网络和残差网络的随机深度正则化之间有一个有趣的联系。在随机深度中,残差网络的层被随机drop,这就创建了它周围层之间的直接连接。因为池化层不会被deop,最后的网络结构就与DenseNet类似:如果所有的中间层都被丢弃了,那么就可能池化层之间的任意两层可以直接相连。尽管方法完全不同,两者之间的联系可以为这种正则化的成功提供一些理论支持。
Feature Reuse.
设计中,DenseNet允许每一层得到前面所有层的特征图(尽管有时会通过过渡层)。我们进行一个实验来验证是否网络利用了这一特点。我们首先在C10+上训练了一个L=40、k=12的DenseNet。**对于block中的每一个卷积层l,我们计算分配给s层的联机的平均权重(绝对权重)。图5展示了所有三个dense block的热力图。平均绝对权重就表示这一层对之前层的依赖性。**在位置(l,s)的红点表示l层平均来说,较多的使用了之前s层池生成的特征图。
从图中我们可以观察到:
- 所有的层都将它的权重分布在它的所有输入上。这表明前面层提取的特征确实被后面的层直接使用了。
- 过渡层的权重同样分布在它的所有输入上,这表明尽管经过了过渡层,前面层的信息同样可以传到后面的层中,只不过不是通过直接的相连。
- 第二和第三个block中的层一直把最小的权重分配给过渡层的输出,这表明过渡层输出了许多冗余的特征,在DenseNet-BC中,正是将这些冗余压缩,取得了更好效果。
- 尽管最后的分类层(图中最右边)同样使用了全部block的权重,它似乎对最后的特征图更加关注,这表明网络最后可能生成了一些更高级的特征。
6. Conclusion
我们提出了一种新的CNN结构,DenseNet。它在任意有着相同特征图尺寸的两层之间引入直接的连接。我们实验证明DenseNet在上百层的时候也没有优化困难,在我们的实验中,随着参数数量的提升,准确率持续提升,没有出现退化和过拟合,进行设置之后,它在多个数据集上取得了SOTA效果。而且,DenseNet比SOTA的方法有着更少的参数和计算量,仍能取得SOTA结果。
遵循简单的连接规则,DenseNets自然地集成了identity映射,深度监督和多样化深度的属性。网络允许特征在网络中重复使用,可以学习到更紧凑、更有效的模型。由于其紧凑的内部表示形式和对特征冗余进行了减少,DenseNet可能适合多种视觉任务,作为特征提取器。