电商数仓项目总结
技术选型
Hadoop-2.7.2,Zookeeper-3.4.10,Flume-1.7.0,Kafka-0.11.0.2,Kafka-manager-1.3.3.22,Sqoop-1.4.6,Mysql,HDFS,Hive-1.2.1,Tez-0.9.1,Presto0.196,yanagishima-18.0,azkaban-2.5.0,Ganglia
整体架构
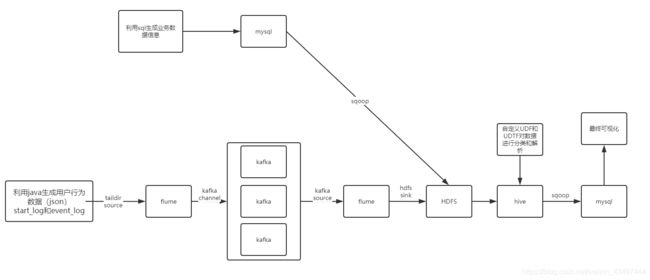
数仓分层
ODS(原始数据层)不做处理,存放原始数据
DWD(明细数据层)进行简单数据清洗,降维
DWS(服务数据层)进行轻度汇总(做宽表)
ADS(数据应用层)为报表提供数据
分为:用户行为数据仓库和系统业务数据仓库
基础知识
表的分类: 实体表:商品表、用户表
维度表:商品(一、二、三)级分类表
事物型事实表:订单详情表、支付流水表
周期事实表:订单表
同步策略: 全量表:实体表、维度表
增量表:事物型事实表
新增及变化表:周期型事实表
维度建模: 星型模型:模型维度只有一层
雪花模型:模型维度涉及多级
星座模型:基于多个事实表
拉链表
拉链表,记录每条信息的生命周期,一旦一条记录的生命周期结束,就重新开始一条新的记录,并把当前日期放入生效开始日期
适用于:数据会发生变化,但大部分是不变的。
基本原理:生成一张与当前拉链表相同的临时表,在最后插入当前拉链表没有的数据,修改已存在的数据,最后将之前的拉链表覆盖。
代码实现:
1)建立拉链表
hive (gmall)>
drop table if exists dwd_order_info_his;
create external table dwd_order_info_his(
`id` string COMMENT '订单编号',
`total_amount` decimal(10,2) COMMENT '订单金额',
`order_status` string COMMENT '订单状态',
`user_id` string COMMENT '用户id' ,
`payment_way` string COMMENT '支付方式',
`out_trade_no` string COMMENT '支付流水号',
`create_time` string COMMENT '创建时间',
`operate_time` string COMMENT '操作时间',
`start_date` string COMMENT '有效开始日期',
`end_date` string COMMENT '有效结束日期'
) COMMENT '订单拉链表'
stored as parquet
location '/warehouse/gmall/dwd/dwd_order_info_his/'
tblproperties ("parquet.compression"="snappy");
2)初始化拉链表
hive (gmall)>
insert overwrite table dwd_order_info_his
select
id,
total_amount,
order_status,
user_id,
payment_way,
out_trade_no,
create_time,
operate_time,
'2019-02-13',
'9999-99-99'
from ods_order_info oi
where oi.dt='2019-02-13';
3)制作变动数据
4)先合并变动信息,再追加新增信息,插入到临时表中
(1)创建临时表
hive (gmall)>
drop table if exists dwd_order_info_his_tmp;
create table dwd_order_info_his_tmp(
`id` string COMMENT '订单编号',
`total_amount` decimal(10,2) COMMENT '订单金额',
`order_status` string COMMENT '订单状态',
`user_id` string COMMENT '用户id' ,
`payment_way` string COMMENT '支付方式',
`out_trade_no` string COMMENT '支付流水号',
`create_time` string COMMENT '创建时间',
`operate_time` string COMMENT '操作时间',
`start_date` string COMMENT '有效开始日期',
`end_date` string COMMENT '有效结束日期'
) COMMENT '订单拉链临时表'
stored as parquet
location '/warehouse/gmall/dwd/dwd_order_info_his_tmp/'
tblproperties ("parquet.compression"="snappy");
(2)导入数据到临时表
hive (gmall)>
insert overwrite table dwd_order_info_his_tmp
select * from
(
select
id,
total_amount,
order_status,
user_id,
payment_way,
out_trade_no,
create_time,
operate_time,
'2019-02-14' start_date,
'9999-99-99' end_date
from dwd_order_info where dt='2019-02-14'
union all
select oh.id,
oh.total_amount,
oh.order_status,
oh.user_id,
oh.payment_way,
oh.out_trade_no,
oh.create_time,
oh.operate_time,
oh.start_date,
if(oi.id is null, oh.end_date, date_add(oi.dt,-1)) end_date
from dwd_order_info_his oh left join
(
select
*
from dwd_order_info
where dt='2019-02-14'
) oi
on oh.id=oi.id and oh.end_date='9999-99-99'
)his
order by his.id, start_date;
5)将临时表覆盖拉链表
hive (gmall)>
insert overwrite table dwd_order_info_his
select * from dwd_order_info_his_tmp;
hive中使用的函数
date_add
date_sub
date_format
next_date
last_date
concat
concat_ws
collec_set
get_json_object
问题总结
Sqoop问题
1)导入导出Null存储一致性问题
Hive中的Null在底层是以“\N”来存储,而MySQL中的Null在底层就是Null,为了保证数据两端的一致性。在导出数据时采用–input-null-string和–input-null-non-string两个参数。导入数据时采用–null-string和–null-non-string。
2)数据一致性问题
(1)map数量设置为1个
(2)添加–staging-table,即先将数据放到临时表,待全部导入成功才将数据写入。(添加–clear-staging-table 即可删除创建的临时表)
3)sqoop底层运行
sqoop底层是只有Map阶段,没有Reduce阶段的任务;
原理是重新了MR的inputformat和outputformat
Flume问题
问题发现:在用户行为数据仓库中,从kafka通过flume流向hdfs的过程中,发现数据无法在hdfs保存
问题解决:
(1)首先将问题锁定在flume -> kafka -> flume -> hdfs 的过程中,利用二分查找检查问题,首先利用kafka manager检查kafka中已经生成对应的topic_start和topic_event,并在集群上消费利用begging从头消费两个topic,发现数据已成功导入到kafka当中;将问题锁定在flume 和 hdfs上
(2)由于flume采用的channel为File channel,因此会在本地磁盘生成data和checkpoint,查看对应的data文件,发现数据已经读入到File channel当中,问题锁定到hdfs sink和hdfs上
(3)经查验,发现hdfs sink当中使用的filetype为CompressedStream,压缩格式为lzo,但经过检查发现hdfs的lzo压缩格式未配置成功,将sink的压缩格式改为bzip2后测试,发现采集通道运行正常,hdfs上有数据生成;最后重新添加hdfs的lzo压缩格式,经测试,一切正常。
(4)Ads层数据用Sqoop往MySql中导入数据的时候,如果用了orc(Parquet)不能导入,需转化成text格式
优化
1)利用parquet的文件格式,lzo的压缩方式处理
2)对于flume的hdfs sink产生大量小文件,调整hdfs.rollInterval、hdfs.rollSize、hdfs.rollCount这三个参数的值,将小文件合并
3)将hive的计算引擎有MapReduce换成了Tez(Tez优点:基于内存进行运算,中间过程不落盘,能将多个有依赖的作业转换成一个作业)
4)flume采用Taildir source,支持断点续传;file channel,数据落盘,提高数据可靠性。
5)使用自定义UDF和UDTF,能更方便的检查错误