Python2和Python3中字符串编码问题详解
本文参考:
https://www.cnblogs.com/saolv/p/8158159.html
https://blog.csdn.net/mycar001/article/details/78364357
https://blog.csdn.net/Deft_MKJing/article/details/79460485?tdsourcetag=s_pcqq_aiomsg
首先说明:
Python2和Python3的默认字符串编码是不一样的!
字符在内存中都是二进制的01,统一使用Unicode编码,当需要保存到硬盘或者传输的时候,就转换为指定编码(比如UTF8)!
Unicode和ASCII一样,即是字符集,也是一种编码,只是ASCII规定了这个二进制怎么存储,Unicode只是规定了符合的二进制代码(码点),没有规定这个二进制代码如何存储和传输。UTF-8是Unicode的一种实现方式!
UTF-8与ASCII兼容!
首先需要知道什么是Unicode,如上文解释,Python以Unicode编码为转换中介,进行字符串的转码。
了解一下什么是编码,解码:
字符需要'有效'传输,所以需要将字符编码为二进制的字节序列,解码就是从二进制序列,按照指定的规则,恢复出原始的内容(Unicode)。
字符(Unicode编码)→编码encode→指定字节序列
指定字节序列→解码decode→字符(Unicode编码)
了解Python中的编码和解码:
Python中解码就是把某种编码格式的“内容(二进制序列)”解码成Unicode(其实也是一种二进制序列,只是不便于传输),编码就是将Unicode编码成某种编码格式的“内容(二进制序列)”,Python中encode和decode的默认参数(也可以自己指定编码)是指定的编码(Python2为ASCII,Python3为utf8),默认参数与你模块的编码,编译环境的全局编码,第一行指定的编码都没有关系!
Python2中:
str类型(utf8等编码)字符串→解码(decode)→Unicode类型(Unicode编码)字符串
Unicode类型(Unicode编码)字符串→编码(encode)→str类型(utf8等编码)字符串
Python3中:
str类型(Unicode编码)字符串→编码(encode)→bytes类型字节序列
bytes类型字节序列→解码(decode)→str类型(Unicode编码)字符串
Python3中的str类型是Python2中的Unicode类型和str类型的一种组整合!!!在此处可以先简单的认为只是python2中的Unicode类型换了一个名字。
Python2中的字符串有两个类型,分别为str和unicode,接下来看两者区别


看一段代码:
# coding:utf-8
str1 = "严"
print type(str1)
print str1
print len(str1)
str2 = u"严"
print type(str2)
print str2
print len(str2)
运行结果:
严
3
严
1 下面解释每一行代码
Python2中你定义字符串的时候,字符串的类型是str,也就是具有某种编码格式的字符串,这个字符串的编码格式取决于你第一行代码声明的编码格式,注意第一行声明的编码格式需要与.py文件的编码格式相同!
第一行代码是声明本模块的编码格式,当不写这一行的时候,在Pythcam中的字符串是没办法输入汉字的,写上这一行
以后,str1就是以utf8编码的类型为str的字符串,输出的是它本身,长度为3(可以理解这个3,不知道怎么解释,utf8一个汉字三个字节)。
str2是一个unicode类型的字符串,输出也为它本身,长度为1(1个Unicode)
再看一段代码:
# coding:utf8
str1 = "严" #utf8的str类型的字符串
print type(str1)
print str1
print len(str1)
str2=str1.decode("utf8") #参数必须与第一行的声明相同,解码为unicode类型的字符串
print type(str2)
print str2
print len(str2)
str3=str2.encode("utf8") #unicode字符串编码为utf8的str类型的字符串
print type(str3)
print str3
print len(str3)
str4=str2.encode("gbk") #unicode字符串编码为gbk的str类型的字符串
print type(str4)
print str4
print len(str4)
运行结果:
严
3
严
1
严
3
��
2 str1为utf8(第一行决定的)编码的str类型的字符串。第二段代码decode将其解码为unicode类型的字符串str2.
Python2中的encode和decode函数默认为ASCII编码,可以自己写参数指定。
第三段代码,unicode类型的str2用utf8编码格式编码为str类型的字符串str3,同理,第四段代码, unicode类型的str2用gbk编码格式编码为str类型的字符串str4。当中文以utf8编码的时候占3个字节,以gbk编码的时候占2个字节。至于第四段输出乱码问题我感觉是控制台的编码是utf8的原因。
需要知道的是str类型和unicode类型的字符串输出到控制台都是可见的字符串,不是字节序列(bytes)。
接下来看Python3:
Python3中:字符串有str类型(Unicode编码)和bytes类型(字节序列)两种
str类型(Unicode编码)字符串→编码(encode)→bytes类型字节序列
bytes类型字节序列→解码(decode)→str类型(Unicode编码)字符串
Python3中的str类型是Python2中的Unicode类型和str类型的一种组整合!!!在此处可以先简单的认为只是python2中的Unicode类型换了一个名字。
看两者的区别:
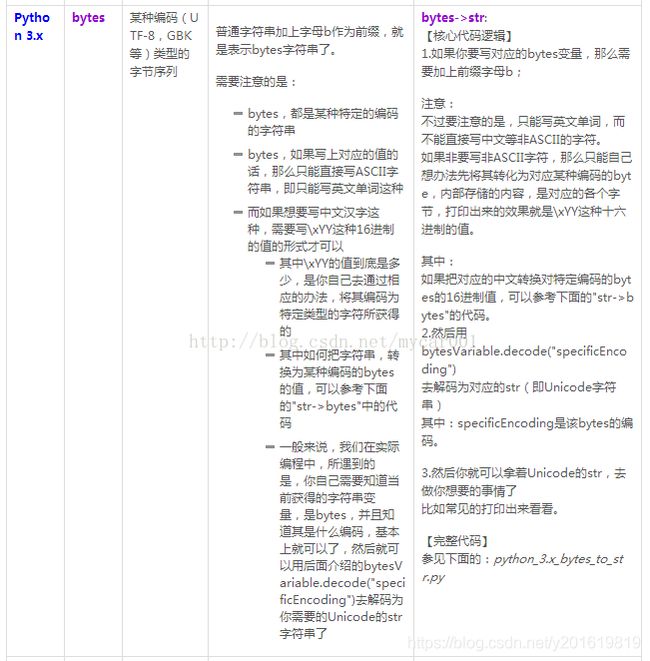

看段代码:
str1 = "我是abc"
print(type(str1))
print(str1)
print(len(str1))
str2 = bytes("我是abc", encoding="utf8")
print(type(str2))
print(str2)
print(len(str2))
运行结果:
我是abc
5
b'\xe6\x88\x91\xe6\x98\xafabc'
9 注意:Python3的字符串默认为Unicode编码的字符串(str类型),当你定义一个带中文的字符串的时候,需要在第一行声明文本类型(# coding:utf8),此类型也需要与.py文件的编码相同,如果不声明第一行的话,默认为utf8,也就是说这时候,需要.py文件的编码为utf8,否则会出错。
其原理就是,当你定义一个字符串的时候,你的文本是以一个编码成的,而Python3的str是Unicode编码的,会自动以你这一个编码(不声明的话,默认为UTF8)去解码成Unicode,当你文本格式不是UTF8并且没有声明编码格式的话,就会解码错误。
str1为str类型的(Unicode编码)的字符串,可以直接显示,长度为5。
str2为bytes类型的(必须指定编码格式)字节序列,输出时看到的不是字符串,是b开头的字节序列,长度为9,utf8中一个汉字三个字节。
注意:Python2中str类型和Unicode类型输出都是可见的字符串,Python3中str类型(Unicode编码)为可见字符串,bytes类型为字节序列,输出看不懂。
再看一段代码:
str1 = "我是abc"
print(type(str1))
print(str1)
print(len(str1))
str2 = str1.encode() # 默认为utf8,等效于encode("utf8")
print(type(str2))
print(str2)
print(len(str2))
str3 = str2.decode() # 默认为utf8,等效于decode("utf8")
print(type(str3))
print(str3)
print(len(str3))
str4 = str1.encode("gbk")
print(type(str4))
print(str4)
print(len(str4))
str5 = str4.decode("gbk") # 参数需要与上面相同
print(type(str5))
print(str5)
print(len(str5))
str6 = str4.decode("utf16",errors="ignore") #以不同方式解码的话就会报错或者乱码,由参数决定
print(str6)
执行结果:
我是abc
5
b'\xe6\x88\x91\xe6\x98\xafabc'
9
我是abc
5
b'\xce\xd2\xca\xc7abc'
7
我是abc
5
틎쟊扡 str1的类型为str(Unicode编码),str2为str1用默认编码格式(utf8)编码以后形成的bytes类型的字节序列,str3为str2解码后的str类型的字符串,str4和str5分别于str2和str3相同,只是编码不同,编码不同也导致了长度不同,,str6位当解码方式不同的时候的乱码,会报错,可以用参数忽略错误。
先写到这,回头想起来什么再来不错,有什么不对的地方,希望大家可以提出。