Python selenium自动获取URP教务系统课表并以图片形式保存
之前写过一篇也是爬URP的(Python爬取URP教务系统课程表并保存到excel),不过用的是request+post请求,中间就借用了一下selenium获取验证码链接,所以这次我就写了一个单单用selenium模拟登录爬课表的…
首先安装selenium、ChromeDriver(因为我用的Chrome浏览器)、还有图像法识别模块pytessrtact,具体安装之前那篇文章有写。
接下来开始操作:
首先:
browser = webdriver.Chrome()
browser.get('http://202.207.177.39:8088/')
F12检查网页源码,既然我们要模拟人的输入,那么我么们就要找账号密码验证码那几个框,还有登录按钮:
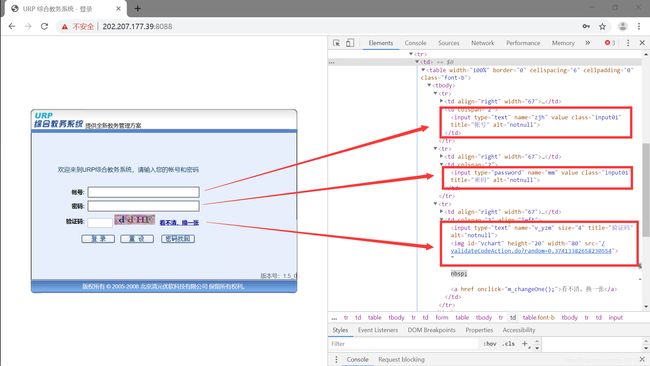
然后我们应先识别出验证码:
这里我用到的方法是截图选取验证码的区域,但是自动获取验证码的区域(注释掉的部分)我一直获取不准,就只能手动定位了…
# 截屏
browser.save_screenshot('code.png')
# 获取验证码位置 起点(x.y) 大小(width,heigth)
# photo=browser.find_element_by_css_selector('#vchart')
# x=photo.location['x']
# y=photo.location['y']
# width=photo.size['width']
# height=photo.size['height']
x = 810
y = 470
width = 120
height = 30
# 打开图片截图
im = Image.open('code.png')
im = im.crop((x, y, x + width, y + height))
im.save('codes.png')
# 验证码识别
img = Image.open('codes.png')
img = img.convert('L')
img = img.point(lambda x: 255 if x > 135 else 0)
# 验证码
text = '0000'
if pytesseract.image_to_string(img):
text = pytesseract.image_to_string(img)
另外说一下为什么验证码要初始化‘0000’,其实这东西是什么无所谓,但不能为空。因为当你的网络有延时的活,可能验证码还没加载出来程序就自动给你截图了,这样你的验证码就是空,或者验证码有点复杂,字体颜色和背景颜色很相似,pytesseract没识别出来,验证码也为空。然后程序执行‘登录’就会出现‘请输入验证码’的提示,即InvalidSessionIdException:Invalid session id。为了避免麻烦的异常处理,我就直接给他一个错误的验证码,这样就不用处理这个异常了。
然后:
# 输入账号密码验证码
browser.find_element_by_css_selector(
'body > table > tbody > tr > td > table.mainbox > tbody > tr:nth-child(1) > td:nth-child(2) > form > table > tbody > tr:nth-child(2) > td > table > tbody > tr:nth-child(1) > td:nth-child(2) > input').send_keys(
'****')
browser.find_element_by_css_selector(
'body > table > tbody > tr > td > table.mainbox > tbody > tr:nth-child(1) > td:nth-child(2) > form > table > tbody > tr:nth-child(2) > td > table > tbody > tr:nth-child(2) > td:nth-child(2) > input').send_keys(
'****')
browser.find_element_by_css_selector(
'body > table > tbody > tr > td > table.mainbox > tbody > tr:nth-child(1) > td:nth-child(2) > form > table > tbody > tr:nth-child(2) > td > table > tbody > tr:nth-child(3) > td:nth-child(2) > input[type=text]').send_keys(
'****')
# 模拟登录
browser.find_element_by_css_selector('#btnSure').click()
在这里我们就要判断登陆是否成功,若不成功就重新来一遍。但是怎么判断登陆是否成功呢?看这里:


两张图比较,可以发现,如果验证码错误,会多出一个名为“errorTop"的类,我们就可以借用这个来判断登陆是否成功,若成功,就不会有这个元素,用selenium查找就会返回NoSuchElementException的异常。如果这个元素一直存在,就说明一直登陆不成功,就让selenium继续自动重试:
try:
if browser.find_element_by_css_selector(
'body > table > tbody > tr > td > table.mainbox > tbody > tr:nth-child(1) > td:nth-child(2) > form > table > tbody > tr:nth-child(1) > td > table > tbody > tr > td > table > tbody > tr:nth-child(2) > td.errorTop'):
print("Login failed, retrying...")
login(browser, number)#登陆函数,用了个递归,详情请看文末源码
except NoSuchElementException:
print('Login successfully')
登录成功后,我们要去教学资源->班级课表里面查课表:

我们要先让selenium自动点击到这里,F12:

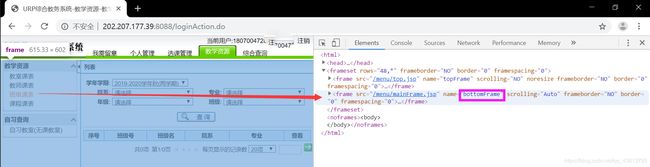

可以看到,教学资源在第一个name为"topFrame"的frame里,班级课表在第二个name为"bottomFrame"的frame里面的name为"menuFrame"的frame里。我们需要依次点击:
browser.switch_to.frame(browser.find_element_by_name('topFrame'))
browser.find_element_by_xpath('//*[@id="moduleTab"]/tbody/tr/td[4]/a').click()
browser.switch_to.default_content()#返回主界面
browser.switch_to.frame(browser.find_element_by_name('bottomFrame'))
browser.switch_to.frame('menuFrame')
browser.find_element_by_xpath('//[@id="project"]/table/tbody/tr[1]/td/table/tbody/tr[2]/td/table/tbody/tr[3]/td/a').click()
注意,browser在完成点击“教学资源”后是停留在"topFrame"中的,我们要让他返回主界面才可以继续去"bottomFrame"中去操作。
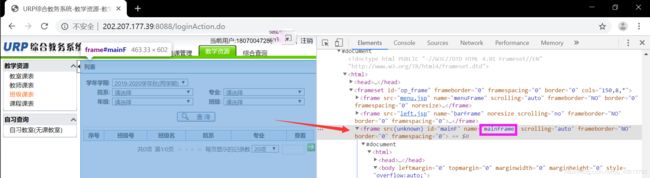
接下来该点击院系、专业、年级、班级了,他们都在name为"bottomFrame"的frame里面的name为"mainFrame"的frame里。但是因为"mainFrame"和"menuFrame"是平级的,他们都是"bottomFrame"的子frame,因此我么们要先返回"bottomFrame"才可以去"mainFrame"继续操作。
browser.switch_to.parent_frame()
browser.switch_to.frame('mainFrame')
然后依次点击:(这里以我的为例)
# 大数据学院
browser.find_element_by_xpath('/html/body/form/table[4]/tbody/tr/td/table[1]/tbody/tr[3]/td[3]/select').click()
browser.find_element_by_xpath('/html/body/form/table[4]/tbody/tr/td/table[1]/tbody/tr[3]/td[3]/select/option[14]').click()
# 计算机类
browser.find_element_by_xpath('/html/body/form/table[4]/tbody/tr/td/table[1]/tbody/tr[3]/td[7]/select').click()
browser.find_element_by_xpath('/html/body/form/table[4]/tbody/tr/td/table[1]/tbody/tr[3]/td[7]/select/option[2]').click()
# 2018级
browser.find_element_by_xpath('/html/body/form/table[4]/tbody/tr/td/table[1]/tbody/tr[5]/td[3]/select').click()
browser.find_element_by_xpath('/html/body/form/table[4]/tbody/tr/td/table[1]/tbody/tr[5]/td[3]/select/option[21]').click()
# 班级
browser.find_element_by_xpath('/html/body/form/table[4]/tbody/tr/td/table[1]/tbody/tr[5]/td[7]/select').click()
browser.find_element_by_xpath('/html/body/form/table[4]/tbody/tr/td/table[1]/tbody/tr[5]/td[7]/select/option[' + str(int(number[-1]) + 1) + ']').click()
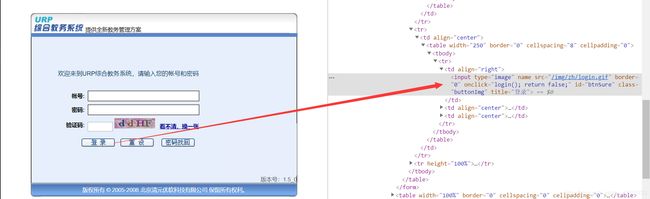
browser.find_element_by_xpath('//*[@id="btnSearch"]').click()
browser.find_element_by_xpath('//*[@id="user"]/tbody/tr/td[6]/img').click()
注意::::
一定要按顺序来,不然是没有东西的。只有当你初次点击了选项框(第一次click),才会弹出选项列表,再进行第二次click
这里解释一下班级:
18070047:
/html/body/form/table[4]/tbody/tr/td/table[1]/tbody/tr[5]/td[7]/select/option[8]
18070048:
/html/body/form/table[4]/tbody/tr/td/table[1]/tbody/tr[5]/td[7]/select/option[9]
可见关键就在于option[]内的数字,即为班级最后一个数字+1
最下面的两个click分别对应这两个点击:

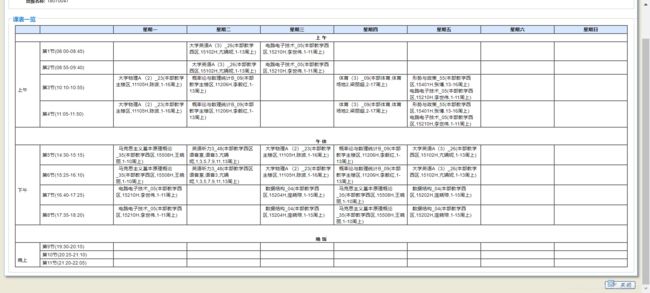
最后我们需要得到类似于这样的图片:
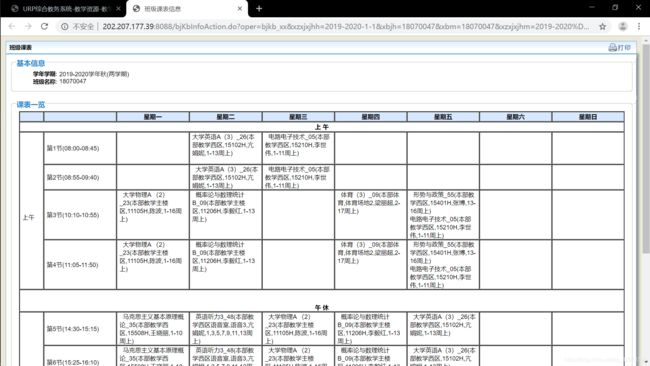
这就引出了两个问题:
1、点击查看以后出现了一个新的窗口,selenium需要跳转到这个窗口进行截屏;
2、可能由于课程较多或字体较大,一张页面显示不完全
解决方案:
1、利用browser.window_handles获取新窗口句柄进行跳转
window_after = browser.window_handles[1]
browser.switch_to.window(window_after)
2、因为selenium无法实现长截图,拼接效果又不是很好(图片也没多长,重合部分很大),所以我采取了进行适当的缩放实现全屏显示
browser.execute_script("document.body.style.zoom='0.8'")
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
然后截屏:
browser.save_screenshot(number + '.png')
接下来上源码:
from selenium.common.exceptions import NoSuchElementException
from selenium import webdriver
from PIL import Image
import pytesseract
def login(browser,number):
# 全屏
browser.maximize_window()
# 隐式等待
browser.implicitly_wait(3)
# 截屏
browser.save_screenshot('code.png')
# 获取验证码位置 起点(x.y) 大小(width,heigth)
# photo=browser.find_element_by_css_selector('#vchart')
# x=photo.location['x']
# y=photo.location['y']
# width=photo.size['width']
# height=photo.size['height']
x=810
y=470
width=120
height=30
# 打开图片截图
im=Image.open('code.png')
im=im.crop((x,y,x+width,y+height))
im.save('codes.png')
# 验证码识别
img=Image.open('codes.png')
img=img.convert('L')
img=img.point(lambda x:255 if x>135 else 0)
text='0000'
if pytesseract.image_to_string(img):
text=pytesseract.image_to_string(img)
# 输入账号密码验证码
browser.find_element_by_css_selector('body > table > tbody > tr > td > table.mainbox > tbody > tr:nth-child(1) > td:nth-child(2) > form > table > tbody > tr:nth-child(2) > td > table > tbody > tr:nth-child(1) > td:nth-child(2) > input').send_keys('*******')
browser.find_element_by_css_selector('body > table > tbody > tr > td > table.mainbox > tbody > tr:nth-child(1) > td:nth-child(2) > form > table > tbody > tr:nth-child(2) > td > table > tbody > tr:nth-child(2) > td:nth-child(2) > input').send_keys('*******')
browser.find_element_by_css_selector('body > table > tbody > tr > td > table.mainbox > tbody > tr:nth-child(1) > td:nth-child(2) > form > table > tbody > tr:nth-child(2) > td > table > tbody > tr:nth-child(3) > td:nth-child(2) > input[type=text]').send_keys(text)
# 模拟登录
browser.find_element_by_css_selector('#btnSure').click()
try:
if browser.find_element_by_css_selector('body > table > tbody > tr > td > table.mainbox > tbody > tr:nth-child(1) > td:nth-child(2) > form > table > tbody > tr:nth-child(1) > td > table > tbody > tr > td > table > tbody > tr:nth-child(2) > td.errorTop'):
print("Login failed, retrying...")
time.sleep(1)
# browser.close()
login(browser,number)
except NoSuchElementException:
print('Login successfully')
# except UnexpectedAlertPresentException:
# browser.close()
# login(browser,number)
# except InvalidSessionIdException:
# browser.refresh()
# login(browser,number)
browser.maximize_window()
browser.switch_to.frame(browser.find_element_by_name('topFrame'))
browser.find_element_by_xpath('//*[@id="moduleTab"]/tbody/tr/td[4]/a').click()
browser.switch_to.default_content()
browser.switch_to.frame(browser.find_element_by_name('bottomFrame'))
browser.switch_to.frame('menuFrame')
browser.find_element_by_xpath('//*[@id="project"]/table/tbody/tr[1]/td/table/tbody/tr[2]/td/table/tbody/tr[3]/td/a').click()
browser.switch_to.parent_frame()
browser.switch_to.frame('mainFrame')
browser.find_element_by_xpath('/html/body/form/table[4]/tbody/tr/td/table[1]/tbody/tr[3]/td[3]/select').click()
browser.find_element_by_xpath('/html/body/form/table[4]/tbody/tr/td/table[1]/tbody/tr[3]/td[3]/select/option[14]').click()
browser.find_element_by_xpath('/html/body/form/table[4]/tbody/tr/td/table[1]/tbody/tr[3]/td[7]/select').click()
browser.find_element_by_xpath('/html/body/form/table[4]/tbody/tr/td/table[1]/tbody/tr[3]/td[7]/select/option[2]').click()
browser.find_element_by_xpath('/html/body/form/table[4]/tbody/tr/td/table[1]/tbody/tr[5]/td[3]/select').click()
browser.find_element_by_xpath('/html/body/form/table[4]/tbody/tr/td/table[1]/tbody/tr[5]/td[3]/select/option[21]').click()
browser.find_element_by_xpath('/html/body/form/table[4]/tbody/tr/td/table[1]/tbody/tr[5]/td[7]/select').click()
browser.find_element_by_xpath('/html/body/form/table[4]/tbody/tr/td/table[1]/tbody/tr[5]/td[7]/select/option['+str(int(number[-1])+1)+']').click()
browser.find_element_by_xpath('//*[@id="btnSearch"]').click()
browser.find_element_by_xpath('//*[@id="user"]/tbody/tr/td[6]/img').click()
window_after = browser.window_handles[1]
browser.switch_to.window(window_after)
browser.execute_script("document.body.style.zoom='0.8'")
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.save_screenshot(number+'.png')
browser.quit()
exit(0)
def main():
browser=webdriver.Chrome()
browser.get('http://202.207.177.39:8088/')
print('请输入想要查找的班级号:')
number=input()
login(browser,number)
if __name__=='__main__':
main()
接下来是程序运行结果演示:
演示结果
结果图片: