智能优化算法:教与学优化算法-附代码
智能优化算法:教与学优化算法-附代码
文章目录
- 智能优化算法:教与学优化算法-附代码
- 1.算法原理
- 1.1“教”阶段
- 1.2 “学”阶段
- 1.3 更新
- 2.算法流程
- 3.算法结果
- 4.参考文献
- 5.MATLAB代码
摘要:教与学优化算法(Teaching-learning-based optimization,TLBO)算法和其他群智能优化算法一样,也是利用群体信息进行启发式搜索[1] 。TLBO 算法通过模拟人类在学习过程中的“教”和“学”2个阶段的学习方法,从而提高每个个体的能力。
1.算法原理
TLBO 算法是模拟以班级为单位的学习方式,班级中的学员水平的提高需要教师的“教”来引导,同时,学员之间需要相互“学习”来促进知识的吸收。其中,教师和学员相当于进化算法中的个体,而教师是适应值最好的个体之一。每个学员所学的某一科目相当于一个决策变量。具体定义如下:
1)搜索空间:搜索空间可表示为 S = { X ∣ x i L ≤ x i ≤ x i U , i = 1 , 2 … , d } S = \{X | x_i^L ≤x_i ≤ x_i^U ,i = 1,2…,d\} S={X∣xiL≤xi≤xiU,i=1,2…,d} , d d d 表示维空间的维数(决策变量的个数), x i L x_i^L xiL和 $x_i^U(i = 1,2,…,d) $分别为每一维的上界和下界。
2)搜索点:设 X j = ( x 1 j , x 2 j , … , x d j ) ( j = 1 , 2 , … , N P ) X_j = (x_1^j ,x_2^j ,…,x_d^j) ( j = 1,2,…,NP ) Xj=(x1j,x2j,…,xdj)(j=1,2,…,NP)为搜索空间中的一个点, x i j ( i = 1 , 2 , … , d ) x_i^j (i = 1,2,…,d) xij(i=1,2,…,d) 为点 X j X_j Xj 的一个决策变量。 N P NP NP 为空间搜索点的个数(种群规模)。
3)班级:在 TLBO 算法中,将搜索空间中所有点的集合称为班(Class)。
4)学员:班级中某一个点 X j = x 1 j , x 2 j , . . . , x d j X^j={x_1^j,x_2^j,...,x_d^j} Xj=x1j,x2j,...,xdj称之为一个学员。
5)教师:班级中成绩最好的学员 X b e s t X_{best} Xbest称之为教师,用 X t e a c h e r X_{teacher} Xteacher表示。
1.1“教”阶段
在 TLBO 算法的“教”阶段,班级中每个学员 X j ( j = 1 , 2 , … , N P ) X_j (j = 1,2,…,NP ) Xj(j=1,2,…,NP)根据 X t e a c h e r X_{teacher} Xteacher 和学员平均值 M e a n Mean Mean之间的差异性进行学习。
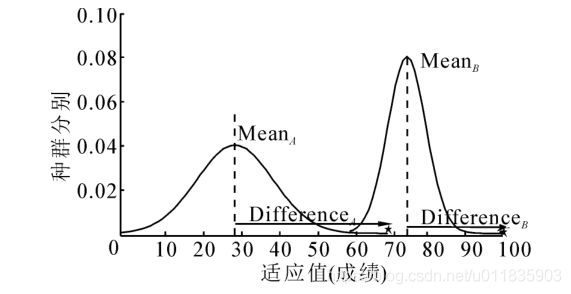
如图1所示,在开始时,班级平均成绩是MeanA=30,平均成绩较低,并且成绩分布比较广,通过Teacher多次的努力教学,班级平均成绩逐步提高到了MeanB=80,成绩分布也越来越集中。在“教”阶段,每个学员向老师学习,学习的方法是利用老师Xteacher和学员的平均值Mean之间的水平差异性进行学习,具体的教学方法如式(1)和(2)
X n e w i = X o l d i + D i f f e r e n c e (1) X_{new}^i=X_{old}^i+Difference\tag{1} Xnewi=Xoldi+Difference(1)
D i f f e r e n c e = r i . ( X t e a c h e r − T F i . M e a n ) (2) Difference=r_i.(X_teacher-TF_i.Mean)\tag{2} Difference=ri.(Xteacher−TFi.Mean)(2)
式中: X o l d i X_{old}^i Xoldi和 X n e w i X_{new}^i Xnewi 分别表示第 i 个学员学习前和学习后的值, M e a n = 1 N P ∑ i = 1 N P X i Mean=\frac{1}{NP}\sum_{i=1}^{NP}X^i Mean=NP1∑i=1NPXi是所有学员的平均值,还有2个关键的参数: 教 学因子 T F i = r o u n d [ 1 + r a n d ( 0 , 1 ) ] TF_i=round[1+rand(0,1)] TFi=round[1+rand(0,1)],学习步长 r i = r a n d ( 0 , 1 ) r_i=rand(0,1) ri=rand(0,1)。
1.2 “学”阶段
在“学”阶段,对每一个学员 X i ( i = 1 , 2 , . . . , N P ) X^i(i=1,2,...,NP) Xi(i=1,2,...,NP),在班级中随机选取一个学习对象 X j ( j = 1 , 2 , . . . , N P , j ≠ i ) X^j(j=1,2,...,NP,j\neq i) Xj(j=1,2,...,NP,j=i), X i X^i Xi通过分析自己和学员 X j X^j Xj的差异进行学习调整,学习改进的方法类似于差分算法中的差分变异算子,不同在于,TLBO算法中的学习步长r对每个学员采用不同的学习因子。采用式(3)实现“学”的过程。
X n e w i = { X o l d i + r i . ( X i − X j ) , f ( X j ) < f ( X i ) X o l d i + r i . ( X j − X i ) , f ( X i ) < f ( X j ) (3) X_{new}^i=\begin{cases}X_{old}^i+r_i.(X^i-X^j),f(X^j)
式中: r i = U ( 0 , 1 ) r_i = U(0,1) ri=U(0,1) 表示第 i 个学员的学习因子(学习步长)。
1.3 更新
学员在经过“教”阶段和“学”阶段都要分别进行更新操作。更新思想类似于差分进化算法,如果学习后的个体 X n e w i X_{new}^i Xnewi比学习前的学员 X o l d i X_{old}^i Xoldi 更好,则用 X n e w i X_{new}^i Xnewi替换 X o l d i X_{old}^i Xoldi 。否则,保持 X o l d i X_{old}^i Xoldi不变。更新方法如下:
I F X n e w i i s b e t t e r t h a n X o l d i IF\quad X_{new}^i\quad is\quad better\quad than \quad X^i_{old} IFXnewiisbetterthanXoldi
X o l d i = X n e w i X^i_{old}= X_{new}^i Xoldi=Xnewi
E n d I F End\quad IF EndIF
2.算法流程
算法流程图如下图所示:

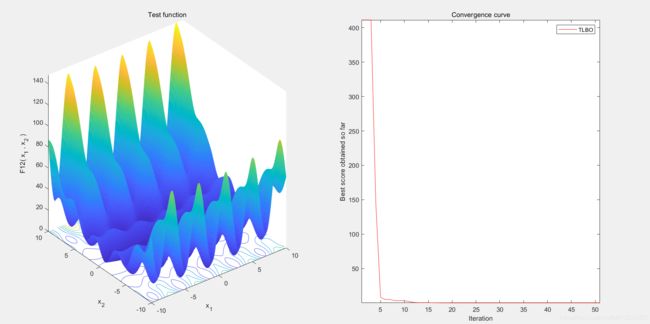
3.算法结果
4.参考文献
[1]Teaching–Learning-Based Optimization: An optimization method for continuous non-linear large scale problems[J] . R.V. Rao,V.J. Savsani,D.P. Vakharia. Information Sciences . 2011 (1)
[2]拓守恒,雍龙泉.一种用于PID控制的教与学优化算法[J].智能系统学报,2014,9(06):740-746.
5.MATLAB代码
https://mianbaoduo.com/o/bread/Z5mYlp4=