成分句法分析 & 依存句法分析 Parsing 知识图谱
文章目录
- 一、成分句法分析
- 1. 上下文无关文法
- 2. CNF 范式
- 3. CKY 算法
- 4. Probabilistic CFG
- 5. 词汇化 PCFG
- 6. 算法性能评价
- 二、依存句法分析
- 1. 依存关系结构
- 2. Transition-based D-Parsers
句法分析 (Parsing, Syntactic Analysis) 是自然语言处理(以下都简称 NLP)领域最核心的技术之一,旨在分析一个句子的语法结构、成分和词语之间的依存关系,是语法校验、语义解释、对话理解、机器翻译等应用的基础。
句法分析一般会分为成分句法分析 (Constituency Parsing) 与依存句法分析 (Dependency Parsing) ,借助下图可以清晰地看出两者区别:
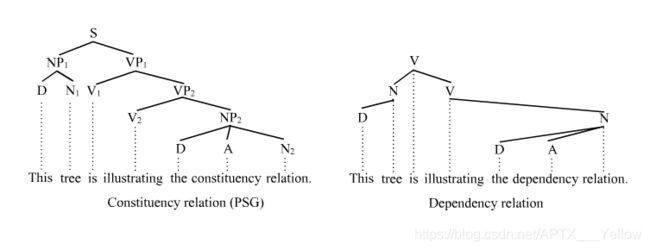
图1 成分与依存句法分析产生的语法树的对比[1]
前者基于词语结构的文法,后者通过词语间的语法关系的文法。通俗理解就是,前者是从一个句子、分解为若干个词语组、最后到分解到一个单词,建立语法结构分析;后者是通过词语之间的语言学联系,建立语法结构分析。
下面将分别详述两种句法分析的经典算法(第一种内容较多)
一、成分句法分析
1. 上下文无关文法
Context-Free Grammar (以下简称 CFG),是描述计算机程序语言和自然语言非常有效的语法。本质上,CFG 是描述语言语法结构的一组形式规则。对于程序语言,这种语法很适用,但我们都知道,人类使用的自然语言,是上下文有关的。那么为什么要用这种不符合现实的语法呢?
以我的理解,因为 NLP 本质上还是用计算机语言去处理自然语言,必须基于机器能懂的语法去扩展。很多编程语言都是 CFG。当然用上下文有关文法去处理也可以,但这里面涉及到程序语言设计的复杂度、可扩展性、处理效率等因素,是一个综合权衡的结果。
那么,接下来就看看 CFG 在数学上的定义。通常可被定义为四个要素:
G={N, T, R, S}
- 非终结符 (Non-terminal) 集合 N。 在 NLP 中一般为词性 (Part-of-Speech) 的集合,如名词、动词、形容词等;
- 终结符 (Terminal) 集合 T。 在 NLP 中一般为一个词汇表;
- 推导规则 (Rules of Productions) 集合 R。 形式为 A → β,其中 A 必须为 单独一个非终结符 ,而 β 可以由非终结符或/与终结符自由组合而成,β ∈ (N ∪ T)*
- 起始符号 S,S 属于非终结符。
最终得出的语法结构分析的形式有多种,最常见的是语法树,下面举一个具体的例子:
 图2 CFG 句子分析的简单例子
图2 CFG 句子分析的简单例子
当然,在实际情况中,集合 T 会是一个非常庞大的词汇表。
运用 CFG 做句法分析,其实就是对每个输入的字符串(即句子),搜索并赋予合适的语法结构,如上图的语法树。那么,CFG 具体是怎么完成这个任务的呢?
最基础的 Parsing 搜索算法有两种,自顶向下和自底向上算法 (Top-down/Bottom-up Parsing)

图3 自顶向下搜索的核心流程
如上图3,自顶向下算法。
步骤1:从根节点开始,根据文法规则,优先扩展当前最左侧的非终结符;
步骤2:NP 有两种扩展模式,如果选择了 Det NP ,那么无法与第一个终结符(单词 ‘I’)匹配,回溯至上一层 NP;
步骤3:NP 扩展为 Pron,然后匹配到了终结符(单词 ‘I’),回溯,从左到右对下一个未进行扩展的终结符进行相似的处理。
直至最后,所有的终结符(单词)都被匹配到了,终止流程。

图4 自底向上搜索的核心流程
如上图4,自底向上算法。
步骤1:从第一个输入的终结符开始,根据文法规则,向上匹配非终结符;
步骤2:,因为有 N → Pron 的规则,所以 Pron 可以直接向上匹配。但再往上就没有规则匹配了,因此处理下一个输入符;
步骤3:,第2个输入符也向上匹配终结符,但 NP 和 V 没有可组合的文法规则,因此继续推进下一个输入符;
直到扫描到最后两个单词,对应的 adj 和 N 可以组成 NP,然后 Det 和 NP 组成 NP,以此类推,最后可以组成相同的语法树。
两者对比
Top-down 会浪费较多时间在探索不能匹配到输入句子的情况上,如图3步骤2;Bottom-up 可能会得出不符合真实语法的语法树(即错误判断句子的语法结构和部分词语的词性)。在这两点上,两者互相避免了对方的情况。
此外,Top-down 还有以下缺点:
-
当出现类似 NP → Det NP 这种文法规则,如果句子较长以及文法规则较多,那么很有可能会出现无限递归的情况;
-
无法处理不合语法规则的句子。
而这两种基础的算法,还有共同的缺陷:
-
由于不牵涉任何语义层面处理,因此无法处理 句子歧义 问题,即同一个句子会有不止一种合乎文法的结构,如下图5;
-
没有对每个节点各种扩展赋予权值,因此无法给出一个最合适的语法树。

图5 句子结构层面的歧义[2]]
因此,在这两者基础上有很多优化的算法,下文即将介绍到的 CKY 算法,就是自底向上的一种。
2. CNF 范式
在详述 CKY 算法前,需要先简单了解一下 CNF (Chomsky Normal Form, 乔姆斯基范式)。CNF 是 CFG 文法规则的一种形式,当一个 CFG 只存在以下文法规则,那它就是符合 CNF 的:
A → B C,A → a,S → ε
ABC 皆为非终结符,a 为终结符,S 为起始符,ε 为空串。
值得一提的是,基于 CNF 得出的语法树会是一棵 二叉树,其二分性质能有效应用到后面介绍到的很多算法中。
每条 CFG 的文法规则都能转化为等价的 CNF,分为以下几种转换:
-
当起始符出现在右侧时,需要添加规则 S0 → S,使原本的 S 变为普通非终结符;
-
非终结符与终结符混合。如:A → b C,可转换为两条规则:A → B C,B → b;
-
右侧多于2个非终结符。如:A → B C D,可转换为两条规则:A → B X,X → C D;
-
右侧为单个非终结符或空串。如:A → B / A → ε,可直接移除这些规则,如果 B 有相应的推导规则,那么 A 可以直接指向 B 指向的规则。
另外,可通过 CNF 创造出乔姆斯基邻接 (Chomsky-adjunction),缩小语法规模。
如:VP → VBD NP PP*,可分解为:
VP → VBD NP PP,VP → VBD NP PP PP,…
而使用 CNF 则可以简单描述为:
VP → VBD NP,NP → NP PP
3. CKY 算法
如上文所说,CKY 算法 (Cocke–Kasami–Younger algorithm,或 CYK) 是一种相对高效的 Bottom-up 算法,运用了动态规划的思想。
首先,我们创建一个表格,存储一个句子的单词对应的词性。若句子的单词数为 n,则创建一个 (n+1)*(n+1) 的矩阵表格,使用它的上半区三角,如下图6:

图6 CKY 识别矩阵表格初始化
此处不列出详细的文法规则,但要注意的是,一个单词可能会对应多个词性,词性之间也不止一种组合方式。与基础的 Bottom-up 每次只选取一种匹配/组合的方式不同,CKY 把每种可能都记录在单元格中。

图7 完整 CKY 识别矩阵表格
从上图7中可见,到最后可以匹配出2棵符合文法规则、以 S 为根节点的语法树结构(为了直观,一些单元格里的词性做了重复处理)。与基础的 Bottom-up 算法相比, CKY 能有效过滤那些无法形成以 S 为根节点的 无效语法树。
但同时,我们也应该发现了,像上面这个句子,CKY 识别后返回的是两课语法树,并且都是符合实际语法的:“预订到 Huston(地名)的航班” 和 “通过 Huston(人名)预订航班”。可见 CKY 算法无法解决 句子歧义 问题,无法选出最符合实际的一种语法结构(而按照我们日常用语,可以判断出前一种句子语义是比较合理的)。
接下来介绍的算法,可以一定程度上解决这个问题。
4. Probabilistic CFG
概率化上下文无关文法(下面简称 PCFG),基于 CFG 文法,给每条文法规则赋予一个事先确定(通过统计语料库或其它方法)的先验概率,如 p(A → β), 0 其中,对于每个有文法推导式的非终结符,它的所有推导式的概率之和必为1。 比如 A 有:A → B C,A → D,A → a,这三条规则的概率之和为1。 基于上一节的 CKY 算法得出的不同语法树,直接分别把每棵树的每条文法规则的概率连乘,最后选出总概率最大的语法树即可。 为什么说是一定程度上解决歧义问题呢?确实,PCFG 可以给出一棵 概率上“最常见” 的语法树,但还是有缺陷的。 首先,因为基于上下文无关文法,PCFG 也是很直接粗暴地预设了文法规则之间相互独立,忽略了句子成分(词语词性)之间的依赖关系。比如在英语中,当一个名词短语 NP 是句子中的宾语时,它是代词 Pronoun 的几率远高于它不是代词(比如专有名词 Proper noun)的几率。以下是一个语料库中的分布情况: 但是,PCFG 无法知晓这个短语是宾语还是主语,无法把这些信息运用到概率计算中,导致计算出来的总概率与实际语法还是有一定程度出入的。 词汇化概率上下文无关文法 (Lexicalized PCFG),给每条文法规则指定一个 中心词 (head),让文法规则扩展为 词汇化语法 (Lexicalized grammar)。中心词可通过语言学知识事先确定,比如一个句子的中心词一般是动词词组 VP,VP 的中心词是动词 V 等。 语法树结构与 CFG 保持一致,增添了每个节点的中心词,如下图9: 其中,有上划线的代表中心词。 接下来,需要进行一些统计概率上的计算。 首先将文法规则扩展为为(以上图9为例子): 每条文法规则的概率可以以下方式转换为条件概率: 等号右边的条件概率即:当确定非终结符 S 的中心词为 ‘question’ 时,S 扩展为 NP+VP 且非中心词为 ‘lawyer’ 的概率。 上述等式比较难理解,但根据条件概率的 链式法则 ,可以进一步分解为: 等号右边第1个概率为:当确定非终结符 S 的中心词为 ‘question’ 时,S 扩展为 NP+VP 的概率; 我们很难直接得出以上的概率,但可以用 极大似然估计 基于语料库训练集近似估计概率。但考虑到 数据稀疏 问题(某些词汇数据在训练集中正好偏少或没有,导致概率为0),所以需要采用平滑方法避免这种情况。如步骤3等号右边第1个概率可以进一步分拆为: 然后,以一个 平滑参数 λ1 表示上面两个式子的权重 (0<λ<1)。因此有: p(S→NP VP | S, questioned) = λ1e1 + (1-λ1)e2 同理,步骤三等号右边第2个概率也做这种处理,最后就能求出原本文法规则的概率了。 词汇化 PCFG 能有效解决上述主语宾语的相关歧义,但在语言分析中,还有很多种类的歧义,下面列举几种常见的: 介词短语修饰歧义 (PP attachment ambiguity),如: 不结合上下文,我们无法得知 with 是修饰 killed 的还是 knife 的。 连词范围歧义 (Coordination scope ambiguity),如: 不能确定第1个划线短语(航天飞机专家)是和第二个一起修饰 Fred Gregory 还是指的是另一个人。 形容词修饰歧义 (Adjectival modifier ambiguity),如: 所以,基于以上介绍的分析算法,至今还有很多研究人员不断改进算法或寻找新的算法去提高性能,接下来简单介绍几个评价算法性能的参数。 Parser evaluation,基于一个已完成对每个句子人工标注(词性、结构)、被视为“黄金标准”的语料库,目标句法分析器对里面的句子进行分析,得出的结果与“标准”作对比。对比内容为 非终结符的取值、起始点、结束点(一般针对有多分支的非终结符)。 对于上图11,假设这个句子的“标准”标注如中间表格所示,然后又有有个分析器得出右边图表的标注。我们设立以下3个标准: 如图11,召回率 R=2/4,准确率 P=2/3,F1=8/14 另附: 最后提一下,所有基于 CFG 的算法,计算复杂度都是处于 O ( ∣ R ∣ 2 ∗ ∣ N ∣ 3 ) O(|R|^2*|N|^3) O(∣R∣2∗∣N∣3) 的量级。 每棵成分语法树都能转换为依存关系树,原理也是先找出每个成分的中心词,然后让另一个非中心词依赖于此中心词,转化方式如下图13: 上图右边的依存关系树的每条连线上,还要加上 依赖标签 ,下图14是一些标签的例子: 相比于 CFG,依存关系语法更关注与词语间关系、高度词汇化,能更好的应用于 问答系统 与 关系抽取 等场景。另外,这种语法对就这种词语的顺序要求相对比较低,所以在处理一些语法复杂、次序排列更灵活的语言时,依存关系语法比 CFG 更有优势。 经过依存关系语法处理后,一个句子的语法结构一般以以下形式展现: 这样的数学结构有以下特性: 需要额外添加一个根节点 ROOT,它不会有输入弧,而且对句子里每一个单词(包括标点),它都有唯一一条路径; 除根节点外,每个单词都有且只有一条输入弧; 如果这个结构是从 CFG 结构转化而来(见上一节),那么它就会是图15这样的形式——没有交叉的弧线。这是我们称这种结构是 Projective 的,这也是我们实际处理过程中比较常见的形式。 接下来介绍给一个句子剖析赋予这种结构的一种基础算法。 基于转移的依存句法分析,将依存关系结构的构建过程当做一个 动作序列,本质上是以贪婪算法的思想(总是做出在当前看来是最好的选择,求得局部最优解)去确定这个最有动作序列。其中最常被提到的是 MALTparser。 首先是一些数学定义: 一个用于处理词汇依存关系的 堆栈 σ,从 ROOT 开始; 一个存储待处理词汇的 缓冲器 β,初始化时为整个句子; 产生的依存关系弧的 集合 A,开始时为空。 整个算法过程只有以下4种动作: Shift:把缓冲器内的最左边单词移动到堆栈中; Left arc:此时堆栈中最右侧的单词与缓冲器最左侧的单词形成依存关系,后者为中心词,前者成为后者的左侧子节点;在 A 中添加这个依存关系,并把非中心词从堆栈中移除; Right arc:如上,两者形成依存关系,但前者为中心词,后者成为前者的右侧子节点;在 A 中添加这个依存关系,保留堆栈中的单词,将非中心词也加到堆栈中; Reduce:此时堆栈最右边的单词无法与缓冲器中仅剩的最后一个单词产生依存关系,将堆栈中的最右侧的单词移除。 当 缓冲器为空 时,终止算法过程。 具体例子见下图: 但是,上面这些动作,选择哪个并没有固定的规则,需要用一些判别式分类器,比如 SVM、最大熵分类器、DNNs+LSTM 等,这些涉及到机器学习的技术,每个都是需要很长篇幅去讲,后面我会另开一个系列。 此外,也有更多的更有效、性能更高的 Parser,比如基于神经网络的、基于图的等等,不一一详述。但最后,依存句法分析算法的性能评估方法也是要提一提。 其实很简单,也是基于一个人工标注的语料库,对比内容是依存关系,有以下两个参数: Unlabeled attachment score (UAS) , 正确标记关系的比率; Labeled attachment score (LAS), 正确标记关系且关系标签正确的比率 ; 具体例子见下图(UAS 只要求前两项相同,LAS 要求整行相同): 参考 References: [1] https://en.wikipedia.org/wiki/Phrase_structure_grammar [2][3] Jurafsky, D. and Martin, J.H. Speech and Language Processing [4] University of Washington, Course Ling-571 [5] Manning, C. Stanford University, Natural Language Processing with [6] https://blog.csdn.net/wang_yi_wen/article/details/8906121 [7] https://blog.csdn.net/kunpen8944/article/details/83349880 Thanks for reading ; )
图8 名词短语分别为宾语和主语时,是代词的概率分布[3]5. 词汇化 PCFG
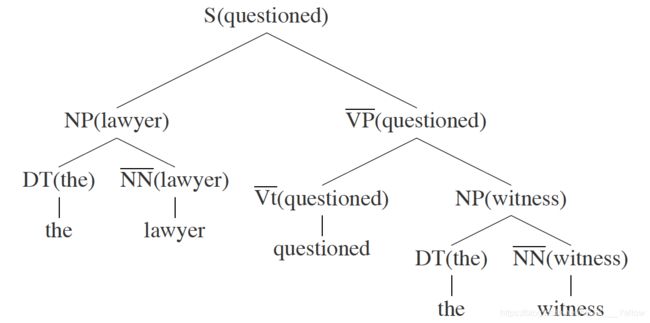
图9 L-PCFG 语法树
S(questioned)→NP(lawyer) VP(questioned)
p(S(questioned)→NP(lawyer) VP(questioned))
= p(S →NP VP, lawyer | S, questioned)
p(S →NP VP, lawyer | S, questioned) =
p(S→NP VP | S, questioned) * p(lawyer | S → NP VP, S, questioned)
第2个概率为:当确定 S 扩展为 NP+VP 且中心词为 ‘question’ 时,非中心词为 ‘lawyer’ 的概率。
图10 极大似然估计法,直接在训练集中累计对应词汇/语法数据的数量
He killed the man with a knife.
Shuttle expert and NASA executive Fred Gregory appointed to board.
He painted her sitting on the step.
不能确定划线部分是在修饰 he 还是 her。6. 算法性能评价
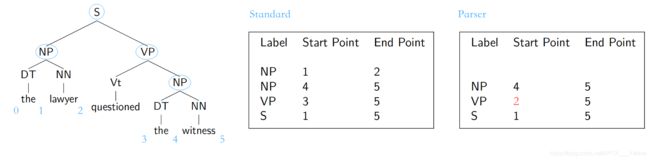
图11 句法分析算法的3个参数
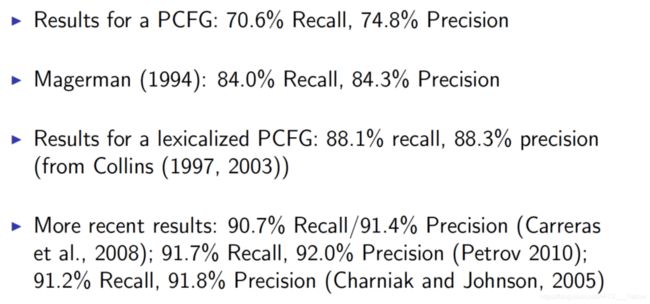
图12 几种基础句法分析的得分二、依存句法分析
1. 依存关系结构
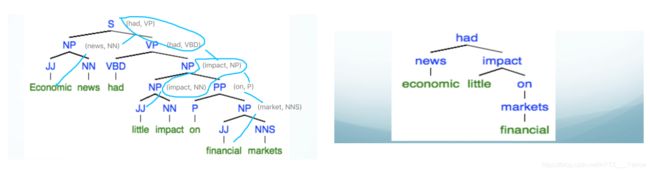
图13 成分语法树转化为依存关系树
图14 部分依赖关系标签及其描述
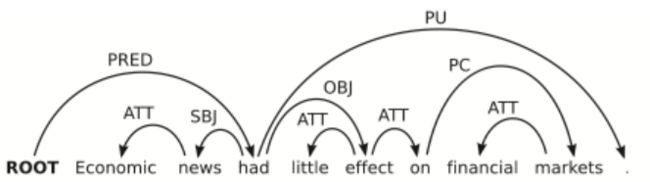
图15 依存句法分析结构
2. Transition-based D-Parsers

图16 Transition-based D-Parsers 例子
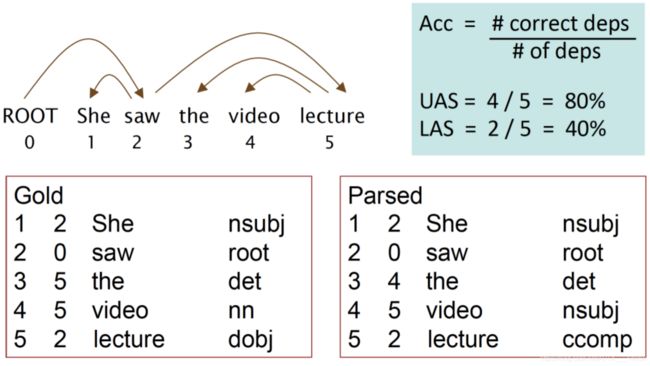
图17 评估依存句法分析算法的参数
Deep Learning