Action Recognition调研
About Dataset
org-website link : https://www.di.ens.fr/~miech/datasetviz/
one-step material link : https://www.jianshu.com/p/a4cc71126796
相关论文中使用最频繁的数据集: UCF101-w, HMDB51, Kinectics-0.5M, Sports-1M, THUMOS14,ActivityNet-w

Video Classification challenge :
ActivityNet(大规模行为识别竞赛,自CVPR-2016开始举办),它侧重于从用户产生的视频中识别出日常生活,高层次,面向目标的活动,视频取自互联网视频门户Youtube。
challenge-link :http://activity-net.org/challenges/2017/guidelines.html

Preliminary
Optical-flow :
details :https://en.wikipedia.org/wiki/Optical_flow
demo-code(opencv):https://blog.csdn.net/linolzhang/article/details/55275994

Video-level predict manner:
1. single-frame predict + all-frames vote;
2. extract one clip from video, then predict clip instead of video;
3. divide the video into T segments, then predict indicidua-snippet, final, vote for video-level predict
Pipeline-outline

Single-stream series
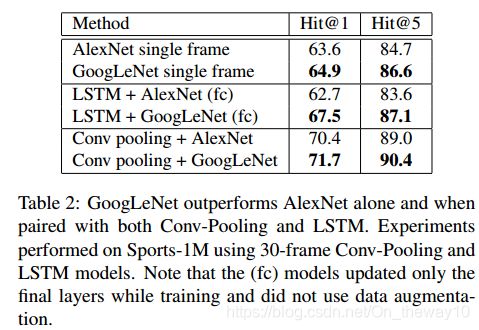
1.C2D(CVPR-2014)
paper : Large-scale Video Classification with Convolutional Neural Networks
idea & Architecture :
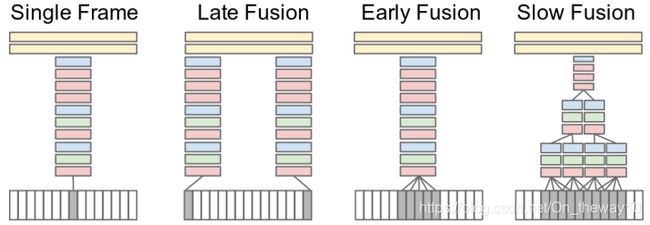
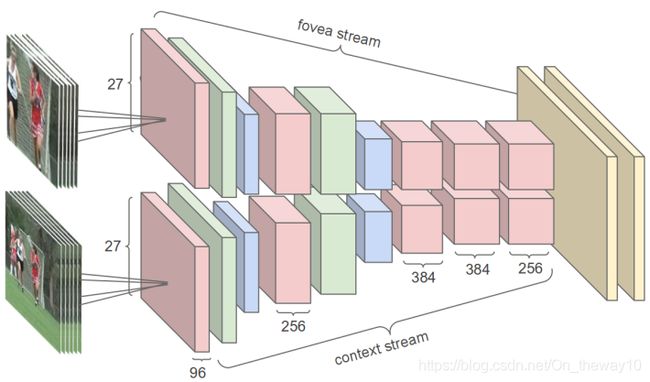
Note: 除了Slow Fusion之外,其他fusion的方式,本质上都属于C2D。
a context stream that models low-resolution image
a fovea stream that processes high-resolution center crop.
采用Multiresolution CNNs的motivation:加快训练速度(通过减小输入frame的size)
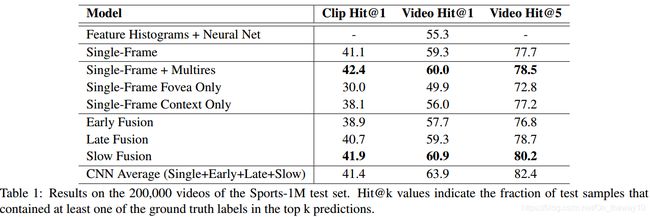
Experiment result:
2.C3D(ICCV-2015)
paper : Learning Spatiotemporal Features with 3D Convolutional Networks
idea : 3D convolutional Networks
3D-conv 操作示意图 :

Architectures:

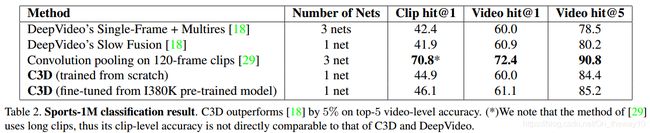
Experiment result :
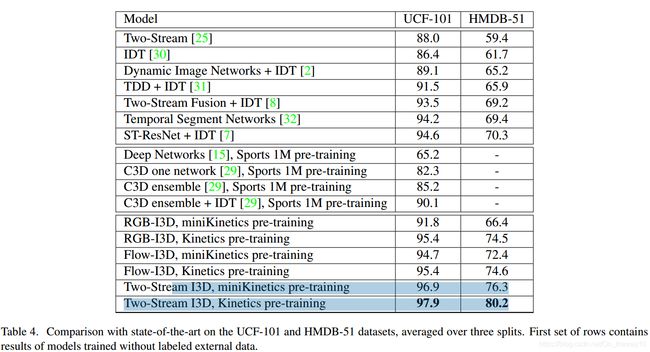
3.I3D-Inception-V1(CVPR-2017)
paper: Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
idea : 将一些经典的video understanding/act recognition的方法,用基于Inception-V1进行重现,然后在Kinetics Dataset上进行pretrain,得到一些列结果。产生如下结论:
1. 在Kinetics Dataset pretrain之后,再在各个小的数据集上进行fine-tuning,结果一般独有不同程度的提升;
2. 与3D-series网络相比,Two-Stream-based的网络优势还是比较明显。
被复现的网络架构:
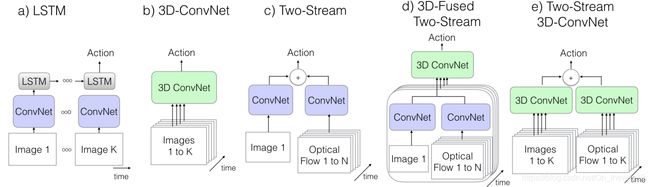
I3D-Architectures

experiment-result
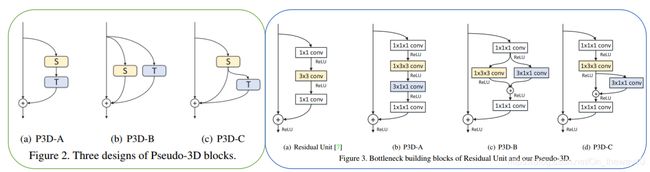
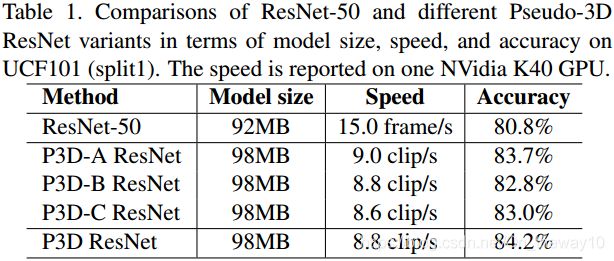
4.P3D-ResNet(ICCV-2017)
paper:Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks
idea:
1). 用2D-spatial conv和1D-temporal conv来模拟3D-conv【减少参数量和计算量】
2). 设计了基于残差学习框架的P3D-ResNet网络
Architectures:
Experiment result :

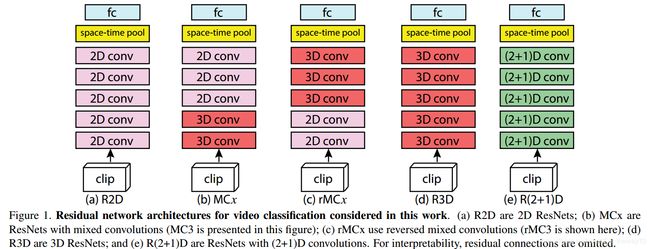
5.R(2+1)D(CVPR-2018)
paper : A Closer Look at Spatiotemporal Convolutions for Action Recognition
idea : 与P3D类似,也是将C3D进拆分为(2+1)D,同样也是基于Residual-learning框架的,但是R(2+1)D更加轻盈、简单。
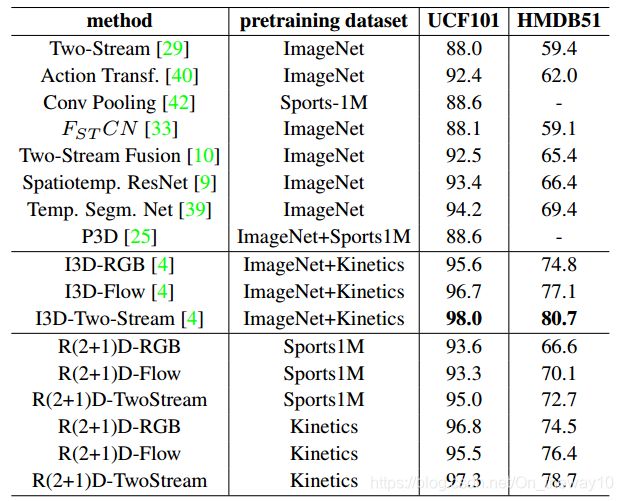
note :对比实验比较充足,具有较高的参考价值:
Architectures:
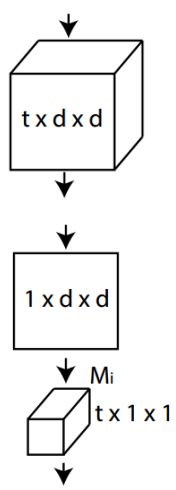
why (2+1)D ?
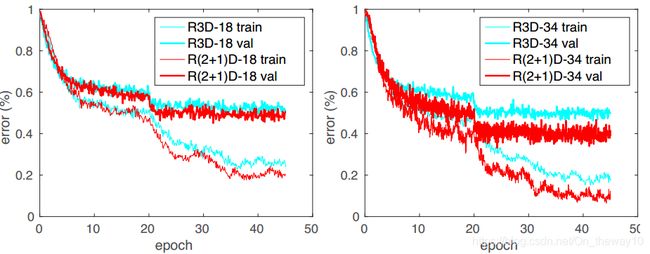
experiment-result:
Two-stream series
1.Two-Stream(NIPS-2014)
paper : Two-Stream Convolutional Networks for Action Recognition in Videos
idea:
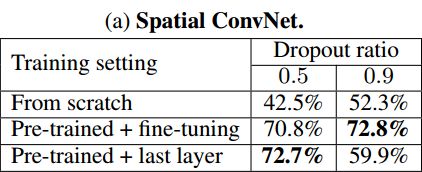
1). 提出了two-stream结构的CNN,由空间和时间两个维度的网络组成(1rgb-frame + 10optical flow-frames);
2). 使用多帧的密集光流场作为训练输入,可以提取动作的信息;
3). 为了缓解overfitting,文章提出了利用了多任务学习的方法把两个数据集联合起来训练模型。
Architecture :

Note : score fusion环节,可以选择直接concat 两个网络的score,之后在fc,但是容易overfitting; 因此,考虑average或者liner-svm的方法来fuse两个网络的score,之后再加入fc。
Experiment result:

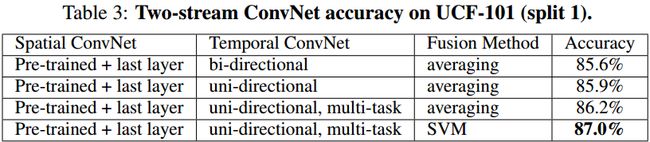

2.Two-stream + LSTM(CVPR-2015)
paper : Beyond Short Snippets: Deep Networks for Video Classification
idea : 文章尝试了2种不同的框架:conv-temporal feature pooling architectures和 LSTM-based architectures,示意图如下:

Architectures:
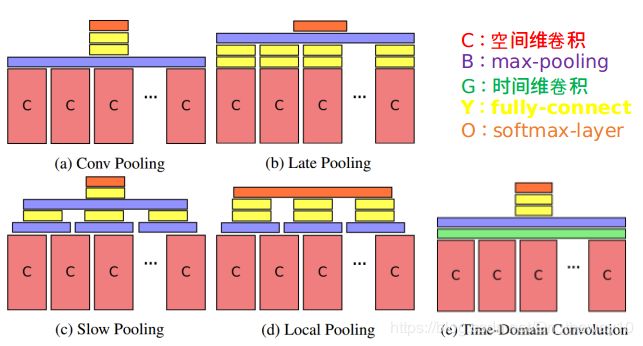

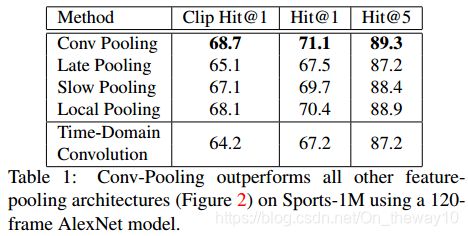
conv-temporal feature pooling architectures LSTM-based architectures
Note:
Experiment result:
3.Two-stream fusion(CVPR-2016)
paper:Convolutional Two-Stream Network Fusion for Video Action Recognition
idea :
1. 系统地探索了spatial stream和optical-flow stream如何融合:
Sum fusion,Max fusion,Concatenation fusion,Conv fusion,Bilinear fusion
2. 在网络的什么哪一层融合?
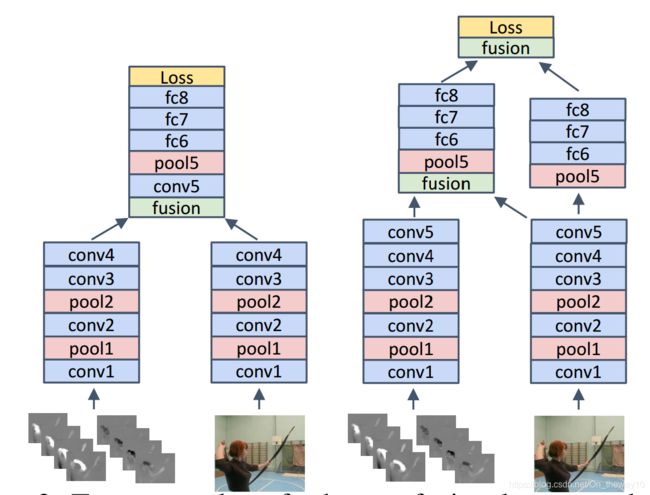
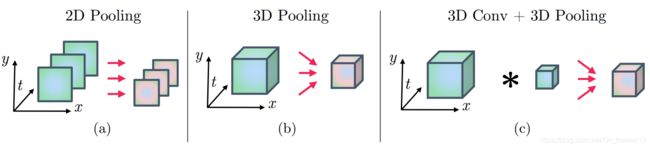
Architectures:
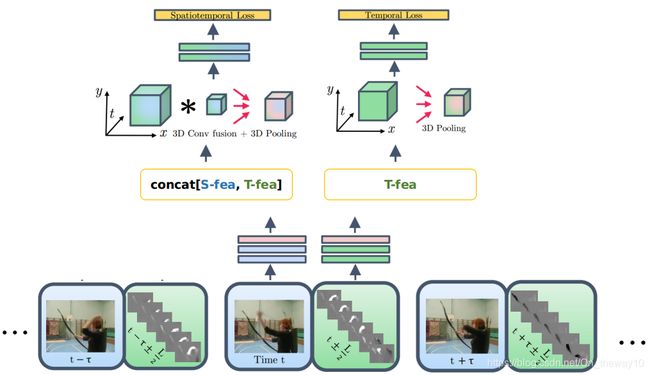
Note:
0. fusion发生在最后一个conv-layer之后(ReLU之后)
1. video-level的预测:首先,划分T个chunks(等间隔τ抽取frame);然后,对T个chunks单独的预测结果vote。
4. base model : VGG-M-2048
5. 输出结果处理:对于两个stream的预测结果取平均。
4.ST-ResNet(NIPS-2016)
paper : Spatiotemporal Residual Networks for Video Action Recognition
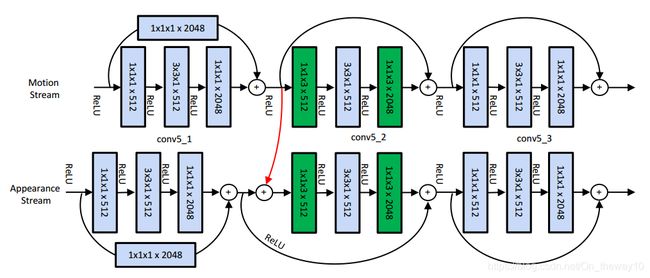
idea : 基于Two-stream + Residual learning的框架,通过在Motion stream和Spatial stream之间建立shortcut来实现时空特征学习。
Architecture :
5.TSN(ECCV-2016)
paper : Temporal Segment Networks: Towards Good Practices for Deep Action Recognition
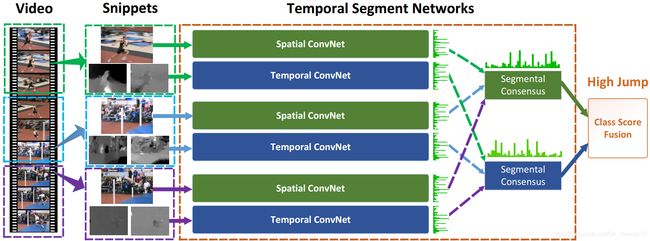
idea: 为了能够解决之前一系列方法中时间维度信息建模不充分的痛点,本文提出了Temporal Segment Networks。它的主要流程如下:
step - 1. 首先对video进行划分,将video划分为K个部分{S1; S2; · · · ; SKg};
step - 2. 对分割片段Sk随机采样,从而得到相应的序列:(T1; T2; · · · ; TK);
step - 3. 将snippet Tk输入网络 F(Tk;W),输出该snippet的类别得分;
step - 4. 对于同一个video的不同snippet对应的score,使用consensus function进行合并,输出最终关于该video的得分
model:
![]()
Architectures:
Note:
1. 问题:为什么在Segmental Consensus环节,不同segment的predict要加权组合在一起呢 ?
2. 四种不同的输入模式

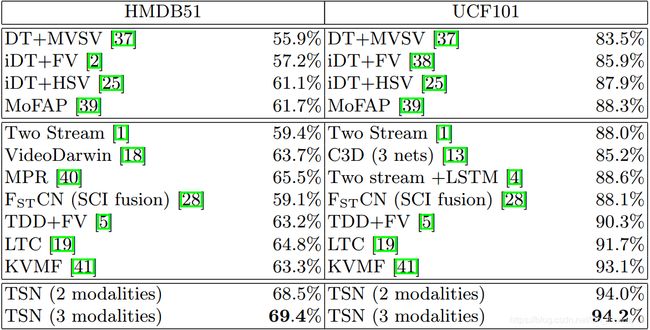
Experiment-result
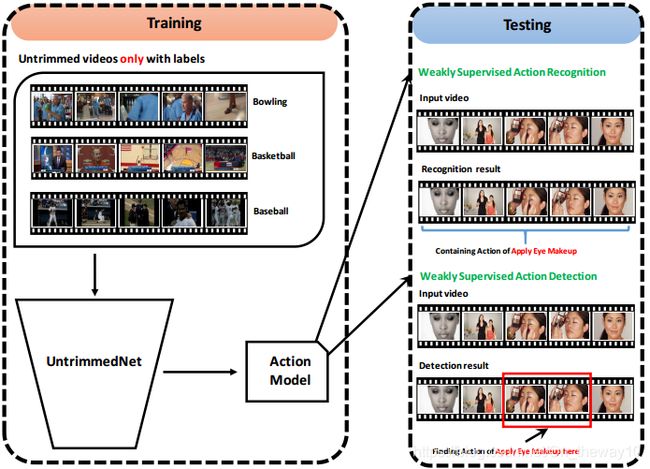
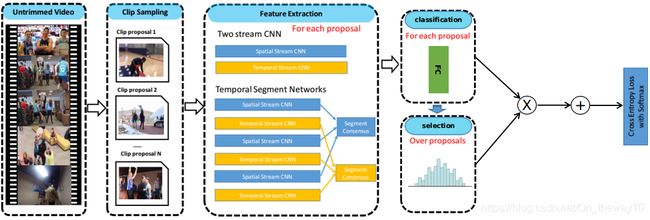
5.UntrimmedNets(CVPR-2017)
paper : UntrimmedNets for Weakly Supervised Action Recognition and Detection
github : https://github.com/wanglimin/UntrimmedNet
idea : 在TSN的基础上,新增加了selection module,结合原有的classification module对classification和detection协同学习,学到的model即可以用来做classification,同时也可以用来做detection。
train-pipeline:
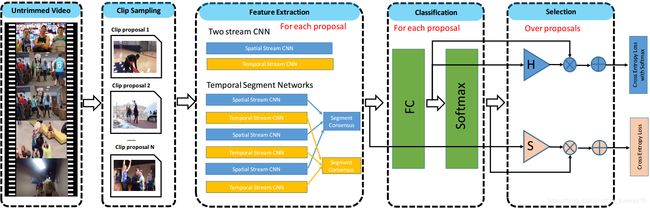
eval-pipeline
hard-mode
5.ECO(ECCV-2017)
- 核心思想:采样(均匀分段 + 段内随机采用) + 卷积(Conv2D + Conv3D)
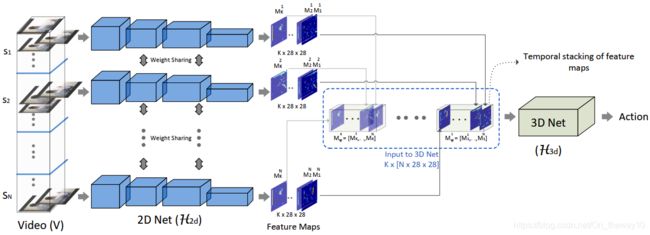
- ECO Lite vs Full ECO

- Training details
1. input-size: (240, 320) --> (224, 224);
2. mini-batch SGD, lr = 1e-3, momentum = 0.9, weight_decay = 5e-4, batch_size = 32;
3. num_segment_per_video = 12
- Result on benchmark
 ,
,

Demo(ucf101)
Solution
