知识整理(三)
目录
1.java数组实现队列
2.java数组实现栈
3.java交替打印AB
4.java交替打印ABC
5.java常见算法的复杂度
6.mysql索引
7.红黑树
8.秒杀系统设计
9.dubbo的调用过程
10.java主内存和工作内存
11,各个收集器
12.zk的工作原理https://blog.csdn.net/yanxilou/article/details/84400562
13.树的遍历
1.java数组实现队列
class MyQueue{
private int[] arr;
private int size;
private int start;
private int end;
MyQueue(int initSize){
if (initSize < 0) {
throw new IllegalArgumentException("the init size must more than 0");
}
arr = new int[initSize];
start = 0;
end = 0;
size = 0;
}
public void push(int obj) {
if (size == arr.length) {
throw new ArrayIndexOutOfBoundsException("The queue is full");
}
arr[end] = obj;
end = end == arr.length - 1 ? 0 : end + 1;
size++;
}
public int poll() {
if (size == 0) {
throw new ArrayIndexOutOfBoundsException("The queue is empty");
}
int tmp = start;
start = start == arr.length - 1 ? 0 : start + 1;
size--;
return arr[tmp];
}
public Integer peek(){
if (size == 0) {
return null;
}
return arr[start];
}
}2.java数组实现栈
public class ArrayStack {
private int length; //定义栈的长度
private Object[] array; //存放数据的数组
private int point; //指向栈顶的指针(下标)
//初始化栈
public ArrayStack(int length) {
this.length = length; //指定栈的大小
point = -1; //默认为-1(空栈)
array = new Object[length]; //数组的长度即为栈的大小
}
//向栈存放元素,即压栈
public void push(Object obj) throws Exception {
if (point == array.length - 1) {
throw new Exception("栈已经满了");
}
array[++point] = obj;
}
//从栈里取元素,即弹栈
public Object pop() throws Exception {
if (point == -1) {
throw new Exception("栈已经空了");
}
return array[point--];
}
//遍历栈里的元素
public void out() {
for (Object obj : array) {
System.out.println(obj);
}
}
/*
*
* 测试
*
* */
public static void main(String[] args) throws Exception {
ArrayStack arrayStack = new ArrayStack(5);
for (int i = 0; i < 5; i++) {
arrayStack.push(i);
}
arrayStack.pop(); //弹栈
arrayStack.push("test"); //压栈
arrayStack.out(); //查看栈内所有元素
}
}
3.java交替打印AB
/**
* Created by Mr.Jo on 2018/9/10.
*/
public class Main{
static class Word {
String s;
public Word(String a) {
s = a;
}
public void setS (String a) {
s = a;
}
public String getS() {
return s;
}
}
static int i = 0;
static Word s = new Word("A");
public static void main(String[] args) {
//A线程
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
while (i < 100) {
synchronized (s) {
if (s.getS().equals("B")) {
try {
s.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
} else {
System.out.println(s.getS());
s.setS("B");
i++;
s.notify();
}
}
}
}
});
//B线程
Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
while (i < 100) {
synchronized (s) {
if (s.getS().equals("A")) {
try {
s.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
} else {
System.out.println(s.getS());
s.setS("A");
i++;
s.notify();
}
}
}
}
});
t1.start();
t2.start();
}
}4.java交替打印ABC
public class ABC_Synch {
public static class ThreadPrinter implements Runnable {
private String name;
private Object prev;
private Object self;
private ThreadPrinter(String name, Object prev, Object self) {
this.name = name;
this.prev = prev;
this.self = self;
}
@Override
public void run() {
int count = 10;
while (count > 0) {// 多线程并发,不能用if,必须使用whil循环
synchronized (prev) { // 先获取 prev 锁
synchronized (self) {// 再获取 self 锁
System.out.print(name);//打印
count--;
self.notifyAll();// 唤醒其他线程竞争self锁,注意此时self锁并未立即释放。
}
//此时执行完self的同步块,这时self锁才释放。
try {
prev.wait(); // 立即释放 prev锁,当前线程休眠,等待唤醒
/**
* JVM会在wait()对象锁的线程中随机选取一线程,赋予其对象锁,唤醒线程,继续执行。
*/
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}
public static void main(String[] args) throws Exception {
Object a = new Object();
Object b = new Object();
Object c = new Object();
ThreadPrinter pa = new ThreadPrinter("A", c, a);
ThreadPrinter pb = new ThreadPrinter("B", a, b);
ThreadPrinter pc = new ThreadPrinter("C", b, c);
new Thread(pa).start();
Thread.sleep(10);//保证初始ABC的启动顺序
new Thread(pb).start();
Thread.sleep(10);
new Thread(pc).start();
Thread.sleep(10);
}
} 5.java常见算法的复杂度

6.mysql索引
二叉树当数据有序时会有线性,红黑树多用于内存,b+树用于外存,红黑树会旋转
7.红黑树
https://www.jianshu.com/p/e136ec79235c
1. 每个节点或是黑色或是红色
2. 根节点是黑色
3. 每个叶节点是黑色(叶节点为空节点)
4. 如果一个节点是红色,则它的子节点必须是黑色
5. 从一个节点到该节点的所有叶节点的路径包含相同数目的黑色节点
定理:红黑树的时间复杂度为O(log2n)O(log2n)。
https://blog.csdn.net/dongzhong1990/article/details/80758256
8.秒杀系统设计
限流: 鉴于只有少部分用户能够秒杀成功,所以要限制大部分流量,只允许少部分流量进入服务后端秒杀程序。
削峰:对于秒杀系统瞬时会有大量用户涌入,所以在抢购一开始会有很高的瞬间峰值。高峰值流量是压垮系统很重要的原因,所以如何把瞬间的高流量变成一段时间平稳的流量也是设计秒杀系统很重要的思路。实现削峰的常用的方法有前端添加一定难度的验证码后端利用缓存和消息中间件等技术。
异步处理:秒杀系统是一个高并发系统,采用异步处理模式可以极大地提高系统并发量,其实异步处理就是削峰的一种实现方式。
内存缓存:秒杀系统最大的瓶颈一般都是数据库读写,由于数据库读写属于磁盘IO,性能很低,如果能够把部分数据或业务逻辑转移到内存缓存,效率会有极大地提升。
可拓展:当然如果我们想支持更多用户,更大的并发,最好就将系统设计成弹性可拓展的,如果流量来了,拓展机器就好了。像淘宝、京东等双十一活动时会增加大量机器应对交易高峰。
9.dubbo的调用过程
- client一个线程调用远程接口,生成一个唯一的ID(比如一段随机字符串,UUID等),Dubbo是使用AtomicLong从0开始累计数字的
- 将打包的方法调用信息(如调用的接口名称,方法名称,参数值列表等),和处理结果的回调对象callback,全部封装在一起,组成一个对象object
- 向专门存放调用信息的全局ConcurrentHashMap里面put(ID, object)
- 将ID和打包的方法调用信息封装成一对象connRequest,使用IoSession.write(connRequest)异步发送出去
- 当前线程再使用callback的get()方法试图获取远程返回的结果,在get()内部,则使用synchronized获取回调对象callback的锁, 再先检测是否已经获取到结果,如果没有,然后调用callback的wait()方法,释放callback上的锁,让当前线程处于等待状态。
- 服务端接收到请求并处理后,将结果(此结果中包含了前面的ID,即回传)发送给客户端,客户端socket连接上专门监听消息的线程收到消息,分析结果,取到ID,再从前面的ConcurrentHashMap里面get(ID),从而找到callback,将方法调用结果设置到callback对象里。
- 监听线程接着使用synchronized获取回调对象callback的锁(因为前面调用过wait(),那个线程已释放callback的锁了),再notifyAll(),唤醒前面处于等待状态的线程继续执行(callback的get()方法继续执行就能拿到调用结果了),至此,整个过程结束。
- https://www.cnblogs.com/aspirant/p/9002663.html
10.java主内存和工作内存
https://www.cnblogs.com/songpingyi/p/9121745.html
11,各个收集器
新生代收集器还是老年代收集器:
新生代收集器:Serial、ParNew、Parallel Scavenge;
老年代收集器:Serial Old、Parallel Old、CMS;
整堆收集器:G1
吞吐量优先、停顿时间优先
吞吐量优先:Parallel Scavenge收集器、Parallel Old 收集器。
停顿时间优先:CMS(Concurrent Mark-Sweep)收集器。
吞吐量与停顿时间适用场景
停顿时间优先:交互多,对响应速度要求高
吞吐量优先:交互少,计算多,适合在后台运算的场景。
串行并行并发
串行:Serial、Serial Old
并行:ParNew、Parallel Scavenge、Parallel Old
并发:CMS、G1
算法
复制算法:Serial、ParNew、Parallel Scavenge、G1
标记-清除:CMS
标记-整理:Serial Old、Parallel Old、G1
12.zk的工作原理
https://blog.csdn.net/yanxilou/article/details/84400562
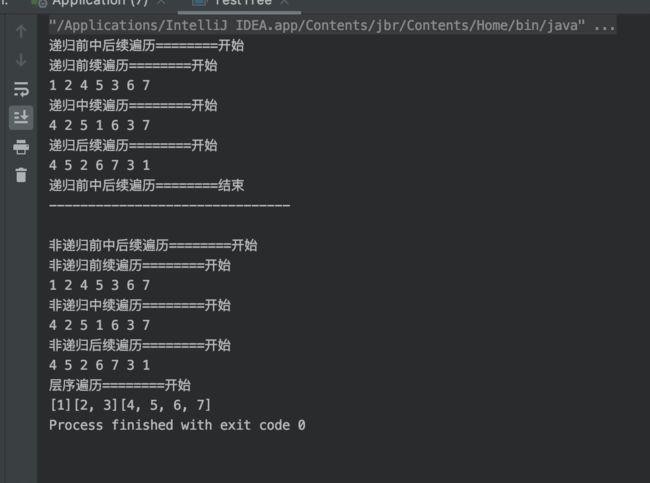
13.树的遍历

package com.example.demo.algorithm;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.Queue;
import java.util.Stack;
import com.example.demo.algorithm.model.TreeNode;
/**
* @author hanzl
* @date 2020/7/30 10:34 上午
*/
public class TestTree {
public static void main(String args[]){
TreeNode root4=new TreeNode(4,null,null);
TreeNode root5=new TreeNode(5,null,null);
TreeNode root6=new TreeNode(6,null,null);
TreeNode root7=new TreeNode(7,null,null);
TreeNode root2=new TreeNode(2,root4,root5);
TreeNode root3=new TreeNode(3,root6,root7);
TreeNode root1=new TreeNode(1,root2,root3);
System.out.println("递归前中后续遍历========开始");
System.out.println("递归前续遍历========开始");
preorder(root1);
System.out.println();
System.out.println("递归中续遍历========开始");
inorder(root1);
System.out.println();
System.out.println("递归后续遍历========开始");
postorder(root1);
System.out.println();
System.out.println("递归前中后续遍历========结束");
System.out.println("-------------------------------");
System.out.println();
System.out.println("非递归前中后续遍历========开始");
System.out.println("非递归前续遍历========开始");
List list=preorderTraversal(root1);
for(Integer i:list){
System.out.print(i+" ");
}
System.out.println();
System.out.println("非递归中续遍历========开始");
List list2=inorderTraversal(root1);
for(Integer i:list2){
System.out.print(i+" ");
}
System.out.println();
System.out.println("非递归后续遍历========开始");
List list3=postorderTraversal_(root1);
for(Integer i:list3){
System.out.print(i+" ");
}
System.out.println();
System.out.println("层序遍历========开始");
levelOrder(root1).forEach(integers -> {
System.out.print(integers);
}
);
}
// 前序遍历
public static void preorder(TreeNode treeNode) {
if (treeNode == null){
return;
}
System.out.print(treeNode.val + " ");
preorder(treeNode.left);
preorder(treeNode.right);
}
// 中序遍历
public static void inorder(TreeNode treeNode) {
if (treeNode == null){
return;
}
inorder(treeNode.left);
System.out.print(treeNode.val + " ");
inorder(treeNode.right);
}
// 后序遍历
public static void postorder(TreeNode treeNode) {
if (treeNode == null) {
return;
}
postorder(treeNode.left);
postorder(treeNode.right);
System.out.print(treeNode.val + " ");
}
// 前序遍历的非递归解法
public static List preorderTraversal(TreeNode root) {
List lists = new ArrayList<>();
if (root == null) return lists;
Stack stack = new Stack<>();
stack.push(root);
TreeNode temp = null;
while (!stack.isEmpty()) {
temp = stack.pop();
lists.add(temp.val);
// 这里注意,要先压入右子节点,再压入左节点
if (temp.right != null) {
stack.push(temp.right);
}
if (temp.left != null) {
stack.push(temp.left);
}
}
return lists;
}
// 二叉树非递归的中序遍历
public static List inorderTraversal(TreeNode root) {
if (root == null) {
return new ArrayList<>();
}
Stack stack = new Stack<>();
TreeNode node = root, temp = null;
List lists = new ArrayList<>();
// 判断条件:所有栈为空,且节点指向为空,即所有节点已经完成遍历
while (!stack.isEmpty() || node != null) {
// 向左搜索,寻找最左的节点,即中序遍历的第一个节点
while (node != null) {
stack.add(node);
node = node.left;
}
// 对每一个节点进行判断
if (!stack.empty()) {
// 获取当前节点
temp = stack.pop();
// 遍历该节点
lists.add(temp.val);
// 如果该节点为内部节点,则按中序遍历的顺序,遍历其右子节点
node = temp.right;
}
}
return lists;
}
二叉树非递归的后序遍历
public static List postorderTraversal_(TreeNode root) {
LinkedList lists = new LinkedList<>();
if (root == null) return lists;
Stack stack = new Stack<>();
stack.push(root);
TreeNode temp = null;
while (!stack.isEmpty()) {
temp = stack.pop();
lists.addFirst(temp.val);
if (temp.left != null) {
stack.push(temp.left);
}
if (temp.right != null) {
stack.push(temp.right);
}
}
return lists;
}
// 根据层序遍历的特点,我们很容易想到使用队列,利用广度优先遍历的方式,进行遍历
public static List> levelOrder(TreeNode root) {
if (root == null) {
return new ArrayList<>();
}
Queue queue = new LinkedList<>();
queue.add(root);
List> lists = new ArrayList<>();
List arrays = new ArrayList<>();
TreeNode temp = null;
while (!queue.isEmpty()) {
int n = queue.size();
// 这里通过读取队列的元素,获取这一层有多少个元素
for (int i = 0; i < n; i++) {
temp = queue.poll();
arrays.add(temp.val);
if (temp.left != null) {
queue.add(temp.left);
}
if (temp.right != null) {
queue.add(temp.right);
}
}
// 将每一层的数据放入到链表中
lists.add(new ArrayList<>(arrays));
arrays.clear();
}
return lists;
}
}
结果:
14.java中锁原理
https://www.cnblogs.com/barrywxx/p/8678698.html
15.mysql 索引学习笔记
二叉树索引有序会形成链 性能不能提升
红黑树自旋 层多(二叉平衡树)
b+树 (相对于b树 非叶子节点只存储索引)又叫多叉平衡树 一个节点16kb bigint 8byte 指针 6byte 16kb/14=1170 叶子节点 1kb 总共存放1170*1170*16 约等于2000万数据
Innodb 聚集 myisam 非聚集 是形容数据库表级别的
myisam 叶子节点data放内存地址 innodb叶子节点data放具体数据
innodb 必须有主键
http://60.205.301.106:8080
hash索引 hash映射表 计算索引hash值 查找hash表 为什么不用hash 范围查找有弊端
主键建议整数递增 原因防止 节点分裂 增加了磁盘Io
mysql联合索引结构 联合字段作为index 根据字段一个一个比 最左前缀
16多线程
.16.1CAS
Lock 指令 compare and change 多核cpu锁总线 Lock copxchg 指令 atomicInteger .creamentandget ->unsafe- native方法->linux64 实现 -->Lock copxchg
解决AbA问题 - 版本号
16.2 对象
T{int m=0} JOL工具 openJdk的一个工具 new 一个对象默认16字节
markword 8bit
class pointer 压缩4bit 不压缩 8bit
成员变量 4 bit 即m
对齐 paddinng 64 为 计算机 8bit (通常作为补全)
锁定对象 是改变了对象的markword
markword 记录了锁信息,gc,hashcode
轻量级锁 又叫自旋锁,无锁 CAS
00 轻锁 10(重锁) 11(gc标记) 001(无锁) 101(偏向锁) 简单记录就是 无 偏 轻 重