nrf51822-提高nordic ble数据发送速率
http://blog.chinaunix.net/uid-28852942-id-5753308.html
讲解2点:
为什么 nordic的4.0协议栈中ble只能发送20字节的应用负载数据。
大量数据发送时如何提高发送速率
1:为何上层应用负载每次最多20字节
首先了解 4.0中链路层的包格式如下:
PDU即协议数据单元,即链路层的负载数据。应用层用户发送的数据就是在这里面,但是并不全是用户数据。
Ble有分广播态和连接态。 所以上面的这个链路层帧可能是广播数据也可能是连接后的数据。 所以就有两种情况,一种为 广播通道中的PDU,另一种为数据通道中的PDU。我们主要讨论的是连接态下的数据通道中的数据帧,这里广播通道下简单介绍下。
广播态下,广播帧中的PDU如下图所示,包含2字节的头,其后的payload即为广播数据,比如通常我们设置的 设备名,厂商自定义数据等都在这里面,广播数据肯定包含设备的地址,所以payload中的前6字节为设备地址

再看下 连接态下 数据通道中 链路层帧中的PDU组成,与广播通道帧中的PDU类似,也是有2字节头,随后为payload即链路层的真实负载数据。
MIC为4字节,只有在链路加密的情况下才会存在,为 消息完整性校验,防止消息被篡改。
PS:加密链路中的空包不会存在MIC

协议都是分层的,ble也一样,那么链路层的负载数据payload即为上层协议的数据帧,链路层的上一层协议为L2CAP,而L2CAP的帧格式如下如所示前4字节分别为长度和信道值。
PS:如果上图Header中的LLID为3,则其后的负载为链路层控制报文而不是L2CAP层帧,这里不介绍。

同样,L2CAP层的负载数据information payload为上层协议的数据帧,对于传输用户数据而言,设备作为主机时用write写数据到从机,设备作为从机是用notify或indication 发送数据给主机,这时候l2CAP层的负载中包含的就是 上层ATT的协议帧。
这里讨论的是用户发送数据为什么是限制为最大20字节,所以了解下ATT协议中的write,notify,indication的命令格式就可以了。
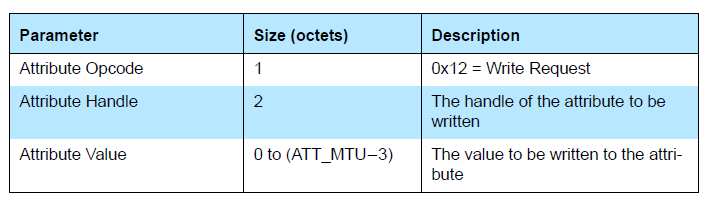
如上图所示,包含1字节opcode用来指示 write,notify,indication。2字节handle为句柄用来标识是操作哪个特性值的。 之后就是真正用户发送的数据了。
所以最终限制能一次发送多少数据就是这个 ATT_MTU 为多少了。
规范中默认这个MTU最小为23字节,这个值其实是可以通过命令来协商的,而nordic的4.0协议栈中默认只支持默认值即23,所以也就限制了最终上层一次发送的数据限制在 20字节。
nrf52832使用的最新的s132协议栈中已经开始支持MTU的协商了,这样就可以一次传输更多数据了。
综上,链路层的PDU中的数据如下图所示:

PS:回顾最开始的链路层 帧结构可以看到 PDU中允许的长度为2-39,即最少有2字节头,有效负载数据最多37字节。
但是从ATT协议往链路层看,ATT 最多20字节用户数据,加上3字节头,加上L2CAP的4字节头,也就27字节,为什么会有差额10字节?
原因在于 PDU因为分情况有广播通道的PDU,和数据通道的PDU,PDU除了2字节头,有效负载为37字节,在广播数据中PDU需要包含6字节的广播地址,其他广播数据也就只有31字节了。但是数据通道中并不需要,但是为了简单起见,也就限制了数据通道中有效负载数据最多31字节。 另一方面 如果链路加密了,数据通道中的PDU,最后会包含4字节的MIC,那么加密的有效负载数据就变成27字节了,这里又为了方便起见,也就让即使不加密的链路发送的有效负载数据也为27。这就是差额的原因。
第二个问题:既然每次发送数据最多才20字节,如果发送较多数据时如何提高发送速率?
以 ble_app_uart例子来说明,该例子中设备作为从机,已经实现了一个以notify方式向手机发送数据的函数。这里就直接利用这个发送函数。

一些简单的应用中通常可能很久才发送一次数据,数据的发送量也没有达到20字节,这种情况下 直接调用该函数发送数据就可以了。
另一种情况,发送的数据比较多,但是对发送的速率并没有要求。这种情况最简单的可以直接用一个循环发送就可以了
While(没发送完){
ble_nus_string_send(数据);
delay_ms(n);
}
通常发送的数据越多delay_ms延迟的时间要越久一点,这个要自己试验。通常只能用在一些少量数据比如一两百字节。
更规范的做法应该利用协议栈中的 发送完成事件 BLE_EVT_TX_COMPLETE,这个事件是在底层发送数据完成后由协议栈发上抛给应用层的。
那么就可以利用这个事件,首先发送20字节,当底层发送完成后上层收到这个 发送完成事件后再发送后续数据。
这里做一个简单的实现
点击(此处)折叠或打开
- 定义了一个关于发送的结构体
- typedef struct blk_send_msg_tag{
- uint32_t start; //发送的起始偏移
- uint32_t max_len; //待发送数据的总长度
- uint8_t *pdata;
- }blk_send_msg;
- //定义一个全局变量
- blk_send_msg g_send_msg;
- //发送数据时就调用这个函数,传入buff以及长度
- uint32_t ble_send_data(uint8_t *pdata, uint32_t len){
- if ( NULL == pdata || len <=0 ){
- return NRF_ERROR_INVALID_PARAM;
- }
-
- uint8_t temp_len;
- uint32_t err_code;
- g_send_msg.start = 0;
- g_send_msg.max_len = len;
- g_send_msg.pdata = pdata;
-
- temp_len = len>20?20:len;
- err_code = ble_nus_string_send(&m_nus, pdata, temp_len);
- if ( NRF_SUCCESS == err_code ){
- g_send_msg.start += temp_len; //发送成功才更新起始偏移
- }
- return err_code;
- }
- //这个函数完成后续数据的发送,将其放在收到 BLE_EVT_TX_COMPLETE事件处理中
- uint32_t ble_send_more_data(){
- uint32_t err_code;
- uint32_t dif_value;
- //计算还有多少数据没发送
- dif_value = g_send_msg.max_len-g_send_msg.start;
- if ( 0 == dif_value || NULL == g_send_msg.pdata ){
- return NRF_SUCCESS; //后续数据全发送完了
- }
-
- uint8_t temp_len;
- temp_len = dif_value>20?20:dif_value;
- err_code = ble_nus_string_send(&m_nus,
- g_send_msg.pdata+g_send_msg.start, temp_len);
- if ( NRF_SUCCESS == err_code ){
- g_send_msg.start += temp_len;
- }
- return err_code;
- }
修改一下Main函数,定义一个全局的buff用来放数据并初始化,将for循环中的power_manager去掉改成通过一个按键来启动发送 buff中的数据。
烧写程序,手机连接上后使能 特性值的notify功能,然后按键便会受到设备发给手机的100字节数据

启动发送后只会发送前20字节,当这20字节发送完成后会收到BLE_EVT_TX_COMPLETE事件,在该事件处理中添加剩余数据的发送
直接在on_ble_evt事件处理函数中添加一下这个事件的处理

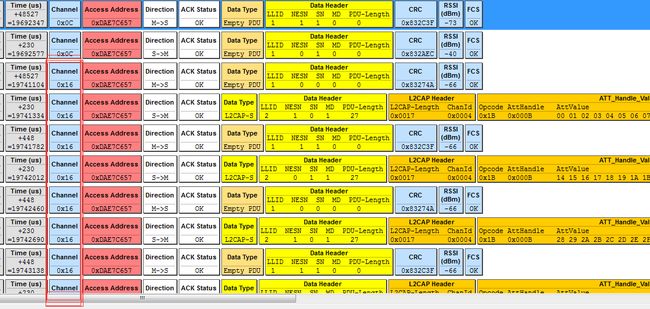
上面的实现只是针对 对发送速率没要求的情况,这里抓包看一下实际的交互过程。
部分截图如下
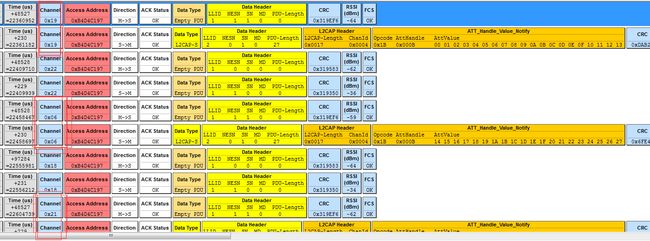
因为每个连接事件到来时都会切换到另一个通道(频率)上进行数据传输,而在这个连接事件持续时间中的数据交互都是在同一个通道上。
即每个连接事件到来时都会切换通道,但是一个连接事件内部的通信都始终在那个通道上
所以由通道号可以区分出来这里基本上是两个连接事件才会发送一次数据,这样效率就很低,因为实际的底层基带发送是很快的1Mbit/s, 也就是1us发送1bit。理论上简单算一下,这里就直接以链路层最长包来算,1+4+39+3 也就只有47字节,

47*8也就是发送一包的实际时间不足1ms,算上基带启动发送以及协议栈的一些处理也应该是几ms的事,那么一个连接间隔除了最前面的几毫秒发送了一下数据,之后这次连接间隔就关了。等之后的连接间隔到来才会继续发送后续数据。那么发送效率就很低。
如果提高每个连接间隔中发送的数据包的数量,那么就可以提高发送速率。
前面的方法是调用每次发送函数后等待 完成事件,实际上,这个协议栈的底层应该有一个自己的发送buff,能存放一定数据,我们调用发送数据后协议栈会将数据放到这个buff中,最终再发送这个buff中的数据。
如果能在下个连接事件到来前竟可能的将多的数据放入这个协议栈中的buff里,那么他下次连接间隔发送的数据就变多了。
Sdk其实提供了这种方法,只不过比较隐晦。
我们利用的发送函数ble_nus_string_send,实际是调用了sd_ble_gatts_hvx 这个协议栈api函数,这个函数有一个返回值NRF_ERROR_BUSY 表示忙,正在处理。
这应该是表示开始发送了。
那么就可以直接重复调用这个ble_nus_string_send 函数直到其返回NRF_ERROR_BUSY 错误,表示已经开始发送了,不能再处理你提交的数据。
另外,协议栈中的buff肯定是有限的,如果我们调用这个发送函数的时候,即将到来下一个连接事件,那么buff肯定填不满,最终出现的错误是NRF_ERROR_BUSY,表示已经开始发送了,你不能再填了。
但是如果调用的时候恰好离下一次连接事件到来还比较久,那么就会出现将协议栈中的buff填满了,从而出现BLE_ERROR_NO_TX_BUFFERS 这个错误。
这里只是介绍这两种错误,实际实现中可以不需要去判断是不是这些错误,因为发送是分包一点一点发送的,我们可以直接就判断 ble_nus_string_send函数调用是不是返回NRF_SUCCESS,如果是才 更新 发送偏移,并且继续循环调用该函数以填更多数据到协议栈buff中,如果返回值不正确,那么直接跳出,不更新发送偏移就可以了,而并不用去区分是BUSY错误还是NO BUFF错误。
点击(此处)折叠或打开
- 如下所示代码,实现一个新的发送子功能函数
- uint32_t send_data(void){
-
- uint8_t temp_len;
- uint32_t dif_value;
- uint32_t err_code = NRF_SUCCESS;
- uint8_t *pdata = g_send_msg.pdata;
- uint32_t start = g_send_msg.start;
- uint32_t max_len = g_send_msg.max_len;
-
- //循环发送,只要返回值正确就反复调用发送函数
- do{
- dif_value = max_len - start;
- temp_len = dif_value>20?20:dif_value;
- err_code = ble_nus_string_send(&m_nus, pdata+start, temp_len);
- if ( NRF_SUCCESS == err_code ){
- //只有返回值正确才更新偏移,
- //不需要考虑是BUSY错误还是NO BUFF错误
- start += temp_len;
- }
- //调用函数成功并且还有数据那就继续调用
- }while ( (NRF_SUCCESS == err_code) && (max_len-start)>0 );
-
- g_send_msg.start = start;
- return err_code;
- }
- 修改之前的实现的ble_send_data和ble_send_more_data函数,他们都直接调用上面的子函数
- uint32_t ble_send_data(uint8_t *pdata, uint32_t len){
- if ( NULL == pdata || len <=0 ){
- return NRF_ERROR_INVALID_PARAM;
- }
-
- uint32_t err_code = NRF_SUCCESS;
- g_send_msg.start = 0;
- g_send_msg.max_len = len;
- g_send_msg.pdata = pdata;
- err_code = send_data();
-
- //返回值应该在外面处理,返回值如果是SUCCESS,
- //或者NRF_ERROR_BUSY或者BLE_ERROR_NO_TX_BUFFERS都应该认为正确
- //因为这两种错误虽然发生了,但是我们并没有去更新start偏移,所以以后
- //的发送还是会正确进行。
- //其他情况上层应该根据情况处理
- return err_code;
- }
- uint32_t ble_send_more_data(){
- uint32_t err_code;
- uint32_t dif_value;
- dif_value = g_send_msg.max_len-g_send_msg.start;
- if ( 0 == dif_value || NULL == g_send_msg.pdata ){
- return NRF_SUCCESS; //后续数据全发送完了直接返回
- }
-
- err_code = send_data();
-
- return err_code;
- }
最后再修改一下main函数,发送500个字节
烧写程序后运行代码,我们再次抓一下空中包看看是否每个连接间隔中发送了多个数据包
由通道号可以看到现在一个连接事件中发送了多个包(最多6个)