Distributed Representations of Sentences and Documents阅读笔记
| 论文原文 | Distributed Representations of Sentences and Documents |
|---|---|
| 论文信息 | ICML2014 |
| 论文解读 | Hytn Chen & Pvop |
| 更新时间 | 2020-02-03 |
句子分布式表示简介
句子分布式表示:将一句话用固定长度的向量进行表示,向量往往高维,因此也可看作将一句话嵌入进高维空间中去,也叫做句嵌入。
句子分布式表示相关方法
基于统计的句子分布式表示
有bag-of-words也就是著名的词袋模型,以及n-gram模型。两个模型非常基础,网络上有很多详细介绍的文章。
基于深度学习的句子分布式表示
有加权平均法以及深度学习模型。
加权平均法
所谓加权平均法模型就是把学习得到的每个词的词向量进行加权平均,从而得到这些词组成的句子的分布式表示:
e S = 1 n ∑ i = 1 n e i e_{S}=\frac{1}{n} \sum_{i=1}^{n} e_{i} eS=n1i=1∑nei
缺点就是忽略了词和词之间的顺序,同时还可以考虑对词加权,加权的方法可考虑tf-idf,基于词的重要性和独特性来分配权重。
深度学习模型
还是基于词向量的学习方法学习得到词向量,之后输入进深度神经网络模型来学习得到句子的分布式表示。类似这样的模型也叫做端到端模型,就是说模型中的所有参数都是同时一起训练的,而不存在先后顺序。
基于语言模型的词向量训练
语言模型可以给出多个词的组合是一个句子的概率:
P ( s ) = ∏ i = 1 T P ( w i ) P(s)=\prod_{i=1}^{T} P\left(w_{i}\right) P(s)=i=1∏TP(wi)
而每个词的概率定义成n-gram形式,即每个词的出现只与前n-1个词有关:
P ( w t ) = P ( w t ∣ w t − n + 1 t − 1 ) P\left(w_{t}\right)=P\left(w_{t} | w_{t-n+1}^{t-1}\right) P(wt)=P(wt∣wt−n+1t−1)
评价语言模型好坏的指标困惑度:
P P ( s ) = 1 / P ( s ) T P P(s)=\sqrt[T]{1 / P(s)} PP(s)=T1/P(s)
P P ( S ) = e − 1 T ∑ i = 1 T l o g P ( w i ) P P(S)=e^{-\frac{1}{T} \sum_{i=1}^{T} logP\left(w_{i}\right)} PP(S)=e−T1∑i=1TlogP(wi)
论文整体框架
这篇论文产生的背景是在词向量表示提出之后,当时许多的研究人员开始研究句向量的表示,并提出了大量的方法来生成句向量。
论文结构
论文大致可分为这么几个部分:摘要,介绍,句向量表示背景,句子分布式表示模型,实验设置,实验结果,相关工作,结论。
从摘要看框架
文章的摘要大致可分为四个部分:
第一部分解释了句向量表示的概念和意义,见本文第一部分;
第二部分讲述了以往的句向量表示模型以及其缺点,就是前文列出的句子分布式表示的相关方法等等;
第三部分讲述了本文提出的模型以及该模型的优点;
第四部分阐述了本文所提出模型的效果。
传统模型详解
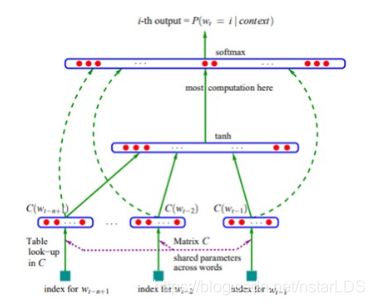
上图取自论文 A Neural Probabilistic Language Model,其算法可分为如下几步:
对每个词随机初始化词向量,通过one-hot,从vocab(字典中词的个数)乘词向量维度的矩阵中,提取得到某个单词对应的词向量;
取得一句话连续的n-1个词,将该n-1个词对应的词向量进行concatenate,形成向量e;
将e作为输入,输入进一个单隐层的神经网络,隐层的激活函数为tanh,输出层的神经元个数为vocab,就是字典中词的个数。
这就是根据前n-1个词来预测当前词的模型。
论文提出的改进的新模型
本文提出的新模型称为分布式句向量训练模型:
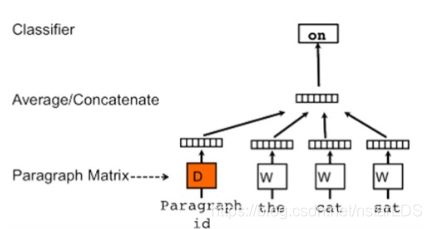
和上部分传统模型不同的是,这篇论文出现了句向量矩阵。给每一句话映射成一个句向量,将句向量与句子中的前n-1个词向量联合起来预测第n个词出现的概率。在有的数据集上(IMDB)作者还是沿袭使用了单隐层的神经网络,而在有的数据集上(例如SST)作者直接就接了分类器去掉了隐藏层,没有隐藏层的神经网络就相当于logistic回归。
模型最后训练的东西就是三个,分类器的参数,一个句向量矩阵,一个词向量矩阵。
最后将学习到的句向量用于分类器,来预测句子的类别概率。
而在测试阶段,则固定训练好的词向量矩阵W和语言模型的其他参数,重新构建一个新的测试集上的句向量矩阵D并随机初始化,然后利用梯度下降训练矩阵D,从而得到测试集每个句子的句向量(在测试的时候还需要训练是这篇文章比较致命的一个弱点)。
文章还提出了一种思路,每个句子通过随机初始化好的句向量矩阵,映射成一个句向量,然后通过句向量每次随机预测句子中的一个词(这个过程很有意思值得研究,反向传播训练到的句向量是否会同时包含这些词的词意?)。然后将学习得到的句向量送到已经训练好的分类器,预测句子的概率。
实验及结果
数据集
主要用于评测的有两个数据集,一个是斯坦福提供的情感分析数据集SST(0-1之间的情感值),一个是IMDB数据集(12500条正例,12500条负例)。
评价方法:SST数据集可根据情感值分为5类,也可以分为两类,评价指标就是预测情感类别的错误率,而IMDB数据集同样也是预测情感类别的错误率。
实验结果
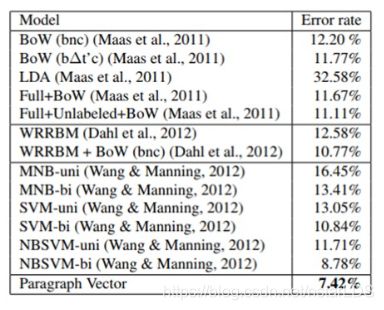
证实了在SST数据集上,该方法优于朴素贝叶斯,SVM,词向量平均法和递归神经网络方法,在二分类和五分类任务中都取得了SOTA结果。
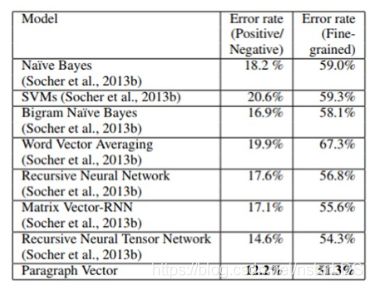
而在IMDB数据集上,本文的模型同样取得了SOTA结果。